面经
java基础面试题总结
Java SE vs Java EE
Java SE 是 Java 的基础版本,Java EE 是 Java 的高级版本。Java SE 更适合开发桌面应用程序或简单的服务器应用程序,Java EE 更适合开发复杂的企业级应用程序或 Web 应用程序
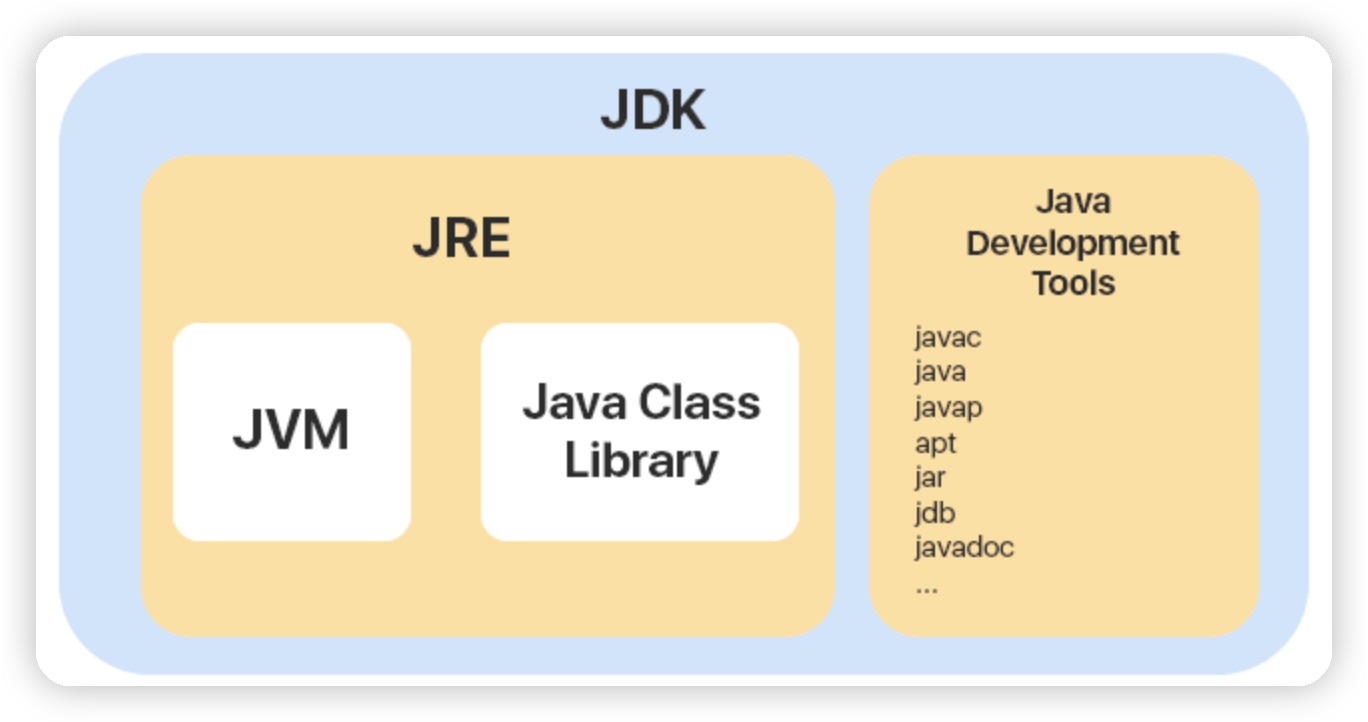
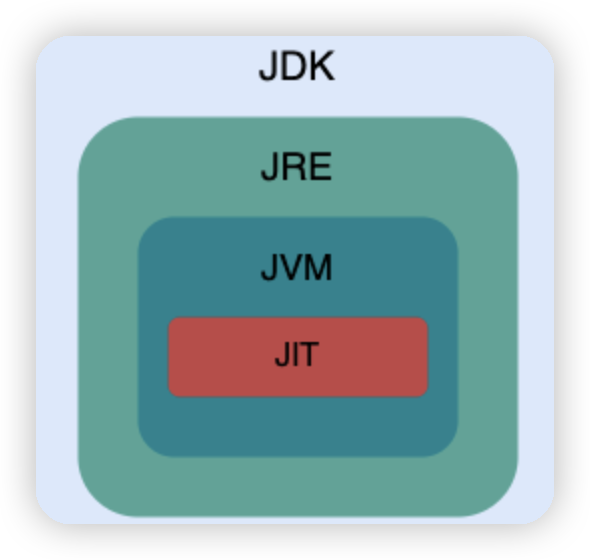
JVM vs JDK vs JRE
JVM是java运行字节码的虚拟机,有针对不同系统的的实现,程序编译成字节码,通过JVM,就可以在不同系统上运行,得到相同的结果
JDK是java开发者工具,提供给开发者使用,能够创建和编译java程序,其包含了JRE,并且包含编译器等
JRE是java运行环境,包含了Java程序运行时候的环境,和必须的库
如果需要进行 Java 编程工作,比如编写和编译 Java 程序、使用 Java API 文档等,就需要安装 JDK。而对于某些需要使用 Java 特性的应用程序,如 JSP 转换为 Java Servlet、使用反射等,也需要 JDK 来编译和运行 Java 代码
字节码
在 Java 中,JVM 可以理解的代码就叫做字节码(即扩展名为 .class 的文件),它不面向任何特定的处理器,只面向虚拟机。
由于字节码并不针对一种特定的机器,因此,Java 程序无须重新编译便可在多种不同操作系统的计算机上运行
从字节码到机器码这一段,JVM会加载字节码文件,然后通过解释器逐行解释执行,这种方式比较慢,所以后面引入JIT,会在第一次编译之后,将字节码对应的机器码保存起来,供下次使用,所以速度更快 对热点代码进行保存
高级编程语言按照程序的执行方式分为两种:
- 编译型:通过编译器将代码一次性翻译成可被该平台执行的机器码,执行速度比较快,开发效率比较低
- 解释型:通过解释器将代码一句一句的将代码解释(interpret)为机器代码后再执行。开发效率比较快,执行速度比较慢
Java 语言既具有编译型语言的特征,也具有解释型语言的特征。因为 Java 程序要经过先编译,后解释两个步骤,由 Java 编写的程序需要先经过编译步骤,生成字节码(.class 文件),这种字节码必须由 Java 解释器来解释执行。
AOT
这种编译模式会在程序被执行前就将其编译成机器码,属于静态编译,AOT 避免了 JIT 预热等各方面的开销,可以提高 Java 程序的启动速度,避免预热时间长。
但AOT也存在一些缺点,所以只能说 AOT 更适合当下的云原生场景,对微服务架构的支持也比较友好,OT 编译无法支持 Java 的一些动态特性,如反射、动态代理、动态加载、JNI(Java Native Interface)等。然而,很多框架和库(如 Spring、CGLIB)都用到了这些特性。如果只使用 AOT 编译,那就没办法使用这些框架和库了
Java与c++区别
-
Java 不提供指针来直接访问内存,程序内存更加安全
-
Java 的类是单继承的,C++ 支持多重继承;虽然 Java 的类不可以多继承,但是接口可以多继承。
-
Java 有自动内存管理垃圾回收机制(GC),不需要程序员手动释放无用内存。
-
C ++同时支持方法重载和操作符重载,但是 Java 只支持方法重载(操作符重载增加了复杂性,这与 Java 最初的设计思想不符)。
标识符和关键字
标识符是程序、类、变量、方法等的名字,关键字是Java 语言已经赋予了其特殊的含义,只能用于特定的地方。关键字是被赋予特殊含义的标识符,所有的关键字都是小写的,在 IDE 中会以特殊颜色显示
⚠️ 注意:虽然 true, false, 和 null 看起来像关键字但实际上他们是字面值,同时也不可以作为标识符来使用。
移位运算符
<< :左移运算符,向左移若干位,高位丢弃,低位补零。x << 1,相当于 x 乘以 2(不溢出的情况下)。
>> :带符号右移,向右移若干位,高位补符号位,低位丢弃。正数高位补 0,负数高位补 1。x >> 1,相当于 x 除以 2。
>>> :无符号右移,忽略符号位,空位都以 0 补齐。
由于 double,float 在二进制中的表现比较特殊,因此不能来进行移位操作。
移位操作符实际上支持的类型只有int和long,编译器在对short、byte、char类型进行移位前,都会将其转换为int类型再操作。
当 int 类型左移/右移位数大于等于 32 位操作时,会先求余(%)后再进行左移/右移操作。也就是说左移/右移 32 位相当于不进行移位操作(32%32=0),左移/右移 42 位相当于左移/右移 10 位(42%32=10)。当 long 类型进行左移/右移操作时,由于 long 对应的二进制是 64 位,因此求余操作的基数也变成了 64。
基本数据类型
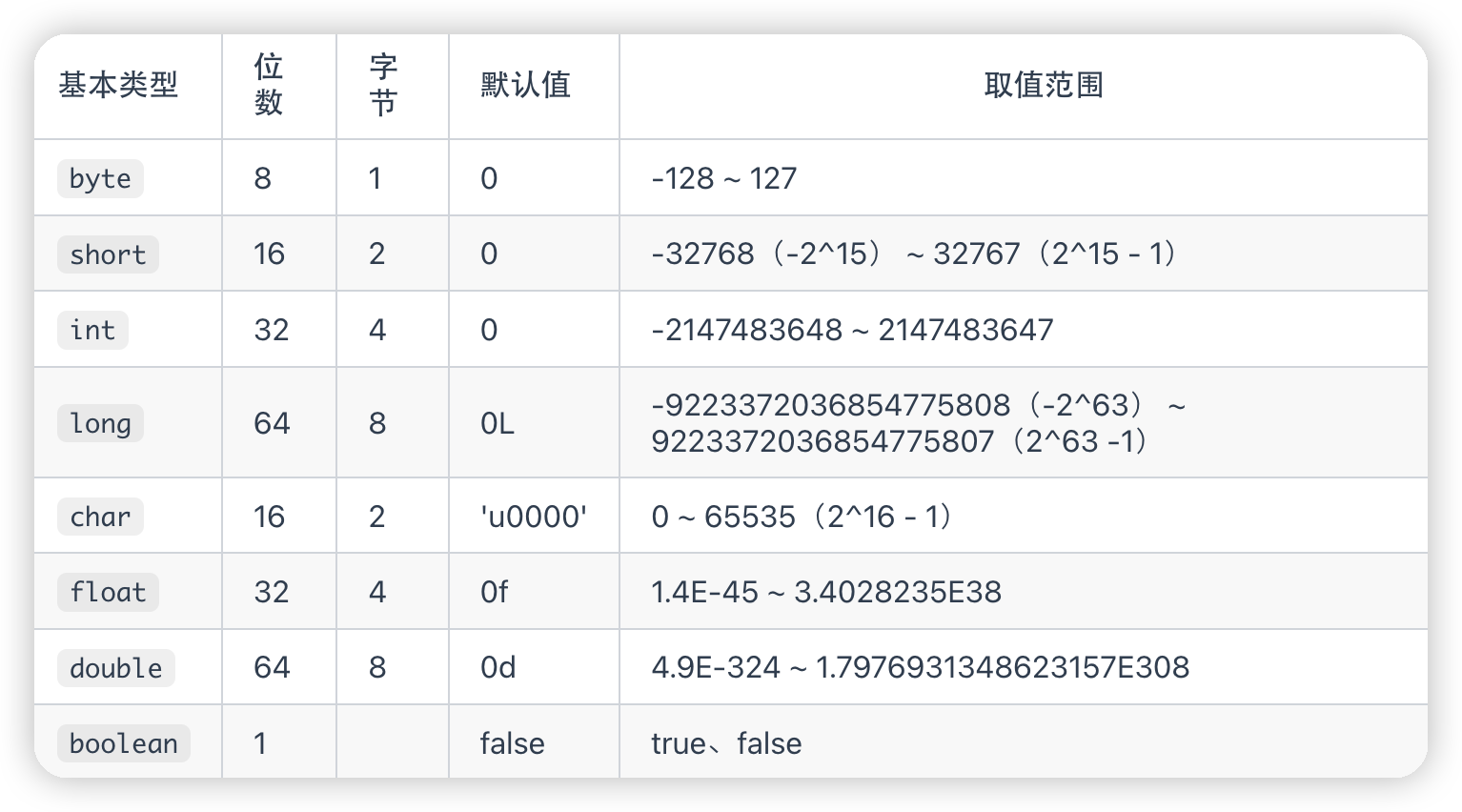
Java 里使用 long 类型的数据一定要在数值后面加上 L,否则将作为整型解析
这八个基本类型都有自己的包装类,比如说int的包装类是Integer
包装类和基本类型的区别
- 包装类型可用于泛型,而基本类型不可以
- 相比于包装类型(对象类型), 基本数据类型占用的空间往往非常小
- 基本数据类型的局部变量存放在Java 虚拟机栈中的局部变量表中,成员变量被存放在 Java 虚拟机的堆中,包装类型属于对象类型,我们知道几乎所有对象实例都存在于堆中。
- 对于基本数据类型来说,
==比较的是值。对于包装数据类型来说,==比较的是对象的内存地址。所有整型包装类对象之间值的比较,全部使用equals()方法
包装类型的缓存机制
Java 基本数据类型的包装类型的大部分都用到了缓存机制来提升性能
Byte,Short,Integer,Long 这 4 种包装类默认创建了数值 [-128,127] 的相应类型的缓存数据,Character 创建了数值在 [0,127] 范围的缓存数据,Boolean 直接返回 True or False
缓存机制代表了在这个范围内,定义相同的值,两个值的内存地址是一样的,Float和Double没有实现缓存机制
1
2
3
4
5
6
7
8
9
10
11
Integer i1 = 33;
Integer i2 = 33;
System.out.println(i1 == i2);// 输出 true
Float i11 = 333f;
Float i22 = 333f;
System.out.println(i11 == i22);// 输出 false
Double i3 = 1.2;
Double i4 = 1.2;
System.out.println(i3 == i4);// 输出 false
自动装箱和拆箱
- 装箱:将基本类型用它们对应的引用类型包装起来;
- 拆箱:将包装类型转换为基本数据类型;
1
2
Integer i = 10; //装箱
int n = i; //拆箱
如果频繁拆装箱的话,也会严重影响系统的性能。我们应该尽量避免不必要的拆装箱操作
解决浮点数运算精度丢失的问题
BigDecimal 可以实现对浮点数的运算,不会造成精度丢失。通常情况下,大部分需要浮点数精确运算结果的业务场景(比如涉及到钱的场景)都是通过 BigDecimal 来做的。
1
2
3
4
5
6
7
8
9
10
BigDecimal a = new BigDecimal("1.0");
BigDecimal b = new BigDecimal("0.9");
BigDecimal c = new BigDecimal("0.8");
BigDecimal x = a.subtract(b);
BigDecimal y = b.subtract(c);
System.out.println(x); /* 0.1 */
System.out.println(y); /* 0.1 */
System.out.println(Objects.equals(x, y)); /* true */
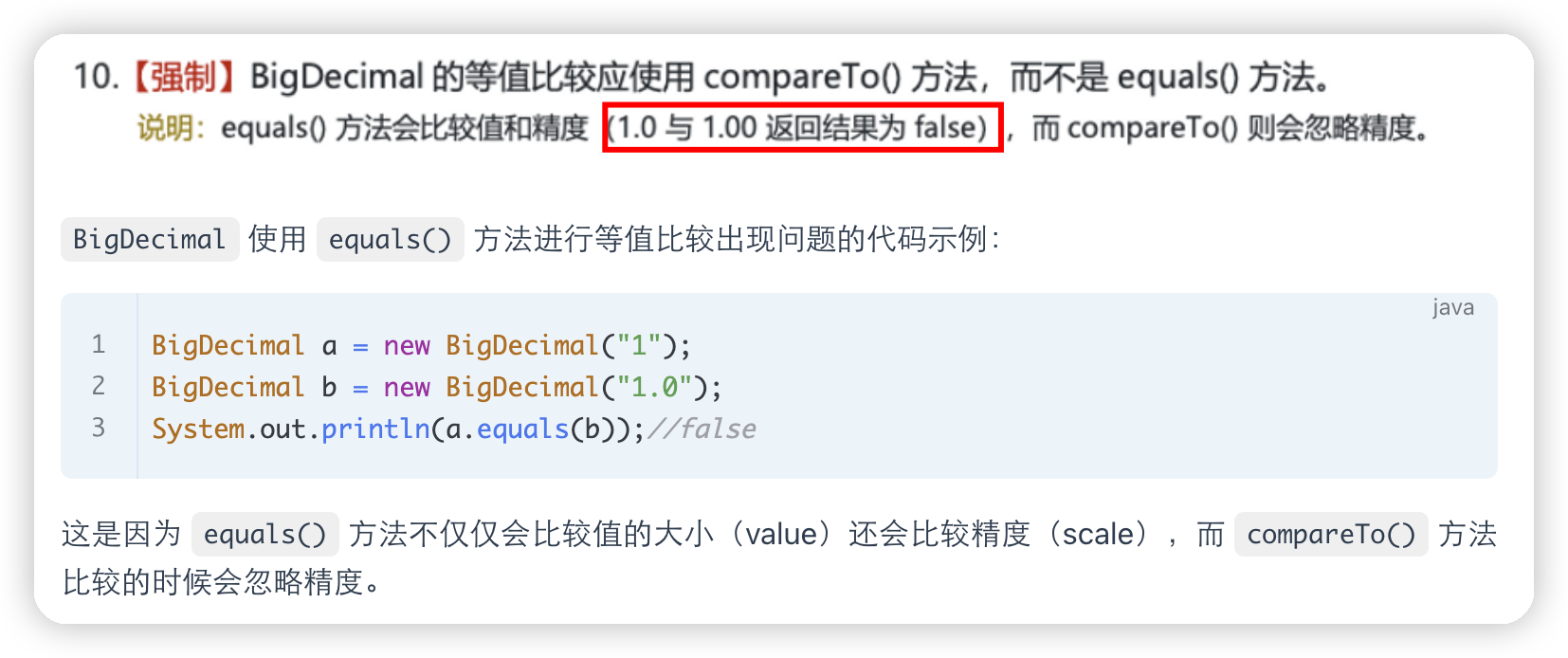
在使用BigDecimal的时候

对于BigDecimal方法有自己的数据操作的方法
1
2
3
4
5
6
7
8
BigDecimal a = new BigDecimal("1.0");
BigDecimal b = new BigDecimal("0.9");
System.out.println(a.add(b));// 1.9
System.out.println(a.subtract(b));// 0.1
System.out.println(a.multiply(b));// 0.90
System.out.println(a.divide(b));// 无法除尽,抛出 ArithmeticException 异常
System.out.println(a.divide(b, 2, RoundingMode.HALF_UP));// 1.11
工具类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
import java.math.BigDecimal;
import java.math.RoundingMode;
/**
* 简化BigDecimal计算的小工具类
*/
public class BigDecimalUtil {
/**
* 默认除法运算精度
*/
private static final int DEF_DIV_SCALE = 10;
private BigDecimalUtil() {
}
/**
* 提供精确的加法运算。
*
* @param v1 被加数
* @param v2 加数
* @return 两个参数的和
*/
public static double add(double v1, double v2) {
BigDecimal b1 = BigDecimal.valueOf(v1);
BigDecimal b2 = BigDecimal.valueOf(v2);
return b1.add(b2).doubleValue();
}
/**
* 提供精确的减法运算。
*
* @param v1 被减数
* @param v2 减数
* @return 两个参数的差
*/
public static double subtract(double v1, double v2) {
BigDecimal b1 = BigDecimal.valueOf(v1);
BigDecimal b2 = BigDecimal.valueOf(v2);
return b1.subtract(b2).doubleValue();
}
/**
* 提供精确的乘法运算。
*
* @param v1 被乘数
* @param v2 乘数
* @return 两个参数的积
*/
public static double multiply(double v1, double v2) {
BigDecimal b1 = BigDecimal.valueOf(v1);
BigDecimal b2 = BigDecimal.valueOf(v2);
return b1.multiply(b2).doubleValue();
}
/**
* 提供(相对)精确的除法运算,当发生除不尽的情况时,精确到
* 小数点以后10位,以后的数字四舍五入。
*
* @param v1 被除数
* @param v2 除数
* @return 两个参数的商
*/
public static double divide(double v1, double v2) {
return divide(v1, v2, DEF_DIV_SCALE);
}
/**
* 提供(相对)精确的除法运算。当发生除不尽的情况时,由scale参数指
* 定精度,以后的数字四舍五入。
*
* @param v1 被除数
* @param v2 除数
* @param scale 表示表示需要精确到小数点以后几位。
* @return 两个参数的商
*/
public static double divide(double v1, double v2, int scale) {
if (scale < 0) {
throw new IllegalArgumentException(
"The scale must be a positive integer or zero");
}
BigDecimal b1 = BigDecimal.valueOf(v1);
BigDecimal b2 = BigDecimal.valueOf(v2);
return b1.divide(b2, scale, RoundingMode.HALF_EVEN).doubleValue();
}
/**
* 提供精确的小数位四舍五入处理。
*
* @param v 需要四舍五入的数字
* @param scale 小数点后保留几位
* @return 四舍五入后的结果
*/
public static double round(double v, int scale) {
if (scale < 0) {
throw new IllegalArgumentException(
"The scale must be a positive integer or zero");
}
BigDecimal b = BigDecimal.valueOf(v);
BigDecimal one = new BigDecimal("1");
return b.divide(one, scale, RoundingMode.HALF_UP).doubleValue();
}
/**
* 提供精确的类型转换(Float)
*
* @param v 需要被转换的数字
* @return 返回转换结果
*/
public static float convertToFloat(double v) {
BigDecimal b = new BigDecimal(v);
return b.floatValue();
}
/**
* 提供精确的类型转换(Int)不进行四舍五入
*
* @param v 需要被转换的数字
* @return 返回转换结果
*/
public static int convertsToInt(double v) {
BigDecimal b = new BigDecimal(v);
return b.intValue();
}
/**
* 提供精确的类型转换(Long)
*
* @param v 需要被转换的数字
* @return 返回转换结果
*/
public static long convertsToLong(double v) {
BigDecimal b = new BigDecimal(v);
return b.longValue();
}
/**
* 返回两个数中大的一个值
*
* @param v1 需要被对比的第一个数
* @param v2 需要被对比的第二个数
* @return 返回两个数中大的一个值
*/
public static double returnMax(double v1, double v2) {
BigDecimal b1 = new BigDecimal(v1);
BigDecimal b2 = new BigDecimal(v2);
return b1.max(b2).doubleValue();
}
/**
* 返回两个数中小的一个值
*
* @param v1 需要被对比的第一个数
* @param v2 需要被对比的第二个数
* @return 返回两个数中小的一个值
*/
public static double returnMin(double v1, double v2) {
BigDecimal b1 = new BigDecimal(v1);
BigDecimal b2 = new BigDecimal(v2);
return b1.min(b2).doubleValue();
}
/**
* 精确对比两个数字
*
* @param v1 需要被对比的第一个数
* @param v2 需要被对比的第二个数
* @return 如果两个数一样则返回0,如果第一个数比第二个数大则返回1,反之返回-1
*/
public static int compareTo(double v1, double v2) {
BigDecimal b1 = BigDecimal.valueOf(v1);
BigDecimal b2 = BigDecimal.valueOf(v2);
return b1.compareTo(b2);
}
}
成员变量和局部变量
- 成员变量可以被
public,private,static等修饰符所修饰,而局部变量不能被访问控制修饰符及static所修饰;但是,成员变量和局部变量都能被final所修饰 - 从变量在内存中的存储方式来看,如果成员变量是使用
static修饰的,那么这个成员变量是属于类的,如果没有使用static修饰,这个成员变量是属于实例的。而对象存在于堆内存,局部变量则存在于栈内存。 - 从变量在内存中的生存时间上看,成员变量是对象的一部分,它随着对象的创建而存在,而局部变量随着方法的调用而自动生成,随着方法的调用结束而消亡
- 成员变量如果没有被赋初始值,则会自动以类型的默认值而赋值(一种情况例外:被
final修饰的成员变量也必须显式地赋值),而局部变量则不会自动赋值
静态变量
被 static 关键字修饰的变量。它可以被类的所有实例共享,无论一个类创建了多少个对象,它们都共享同一份静态变量
静态方法为什么不能调用非静态成员
- 静态方法是属于类的,在类加载的时候就会分配内存,可以通过类名直接访问。而非静态成员属于实例对象,只有在对象实例化之后才存在,需要通过类的实例对象去访问
- 在类的非静态成员不存在的时候静态方法就已经存在了,此时调用在内存中还不存在的非静态成员,属于非法操作。
静态方法和实例方法的不同
- 在外部调用静态方法时,可以使用
类名.方法名的方式,也可以使用对象.方法名的方式,而实例方法只有后面这种方式。也就是说,调用静态方法可以无需创建对象 - 静态方法在访问本类的成员时,只允许访问静态成员(即静态成员变量和静态方法),不允许访问实例成员(即实例成员变量和实例方法),而实例方法不存在这个限制
重载和重写
重载是同一个方法,拥有相同的方法名,但输入数据不同,这样编译器必须挑选出具体执行哪个方法,它通过用各个方法给出的参数类型与特定方法调用所使用的值类型进行匹配来挑选出相应的方法。
1
2
StringBuilder sb = new StringBuilder();
StringBuilder sb2 = new StringBuilder("HelloWorld");
重写是子类继承自父类的相同方法,输入数据一样,但要做出有别于父类的响应时,你就要覆盖父类方法,重写发生在运行期,是子类对父类的允许访问的方法的实现过程进行重新编写
- 方法名、参数列表必须相同,子类方法返回值类型应比父类方法返回值类型更小或相等,抛出的异常范围小于等于父类,访问修饰符范围大于等于父类。
- 如果父类方法访问修饰符为
private/final/static则子类就不能重写该方法,但是被static修饰的方法能够被再次声明。 - 构造方法无法被重写

⭐️ 如果方法的返回类型是 void 和基本数据类型,则返回值重写时不可修改。但是如果方法的返回值是引用类型,重写时是可以返回该引用类型的子类的。
遇到方法重载会优先匹配固定参数的方法,因为固定参数的方法匹配度更高
面向对象的三大特征
封装
一个对象的状态信息(也就是属性)隐藏在对象内部,不允许外部对象直接访问对象的内部信息。但是可以提供一些可以被外界访问的方法来操作属性。
继承
继承是使用已存在的类的定义作为基础建立新类的技术,新类的定义可以增加新的数据或新的功能,也可以用父类的功能,但不能选择性地继承父类
关于继承有几个点需要注意的
- 子类不能直接访问父类的私有方法和私有变量。私有方法和变量只在定义它们的类内部可见,这是封装的一个重要方面,不过可以通过共有方法或者protect方法进行访问
- 子类可以拥有自己属性和方法,即子类可以对父类进行扩展
- 子类可以用自己的方式实现父类的方法
多态
对象可以采用多种形态。在 Java 中,多态主要通过继承(inheritance)和接口(interfaces)以及方法的重写(overriding)和重载(overloading)来实现。多态使得我们可以用统一的方式处理不同类型的对象
实现方法
- 方法重写:子类重写父类的方法。当子类对象调用这个方法时,执行的是子类中重写的版本
- 方法重载:同一个类中多个同名方法,但它们的参数列表不同
- 向上转型:子类对象可以被当作父类对象使用。例如,如果有一个父类
Animal和一个子类Dog,那么Dog对象也可以被当作Animal对象使用。这使得你可以用Animal类型的变量来引用一个Dog对象 - 一个类实现一个接口,它需要提供接口中所有方法的具体实现。一个接口引用可以指向任何实现了该接口的类的对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
// 父类
class Animal {
public void sound() {
System.out.println("Animal makes a sound");
}
}
// 子类
class Dog extends Animal {
@Override
public void sound() {
System.out.println("Dog barks");
}
}
// 主程序
public class Main {
public static void main(String[] args) {
Animal myAnimal = new Animal(); // 创建 Animal 对象
Animal myDog = new Dog(); // 创建 Dog 对象,但将其视为 Animal
myAnimal.sound(); // 输出: Animal makes a sound
myDog.sound(); // 输出: Dog barks,尽管 myDog 被声明为 Animal 类型
}
}
接口和抽象类
共同点:
- 都不能被实例化。
- 都可以包含抽象方法。
- 都可以有默认实现的方法
区别:
- 接口里只有抽象方法,抽象类可以有非抽象方法
- 一个类只能继承一个类,但是可以实现多个接口
- 接口中的成员变量只能是
public static final类型的,不能被修改且必须有初始值,而抽象类的成员变量默认 default,可在子类中被重新定义,也可被重新赋值
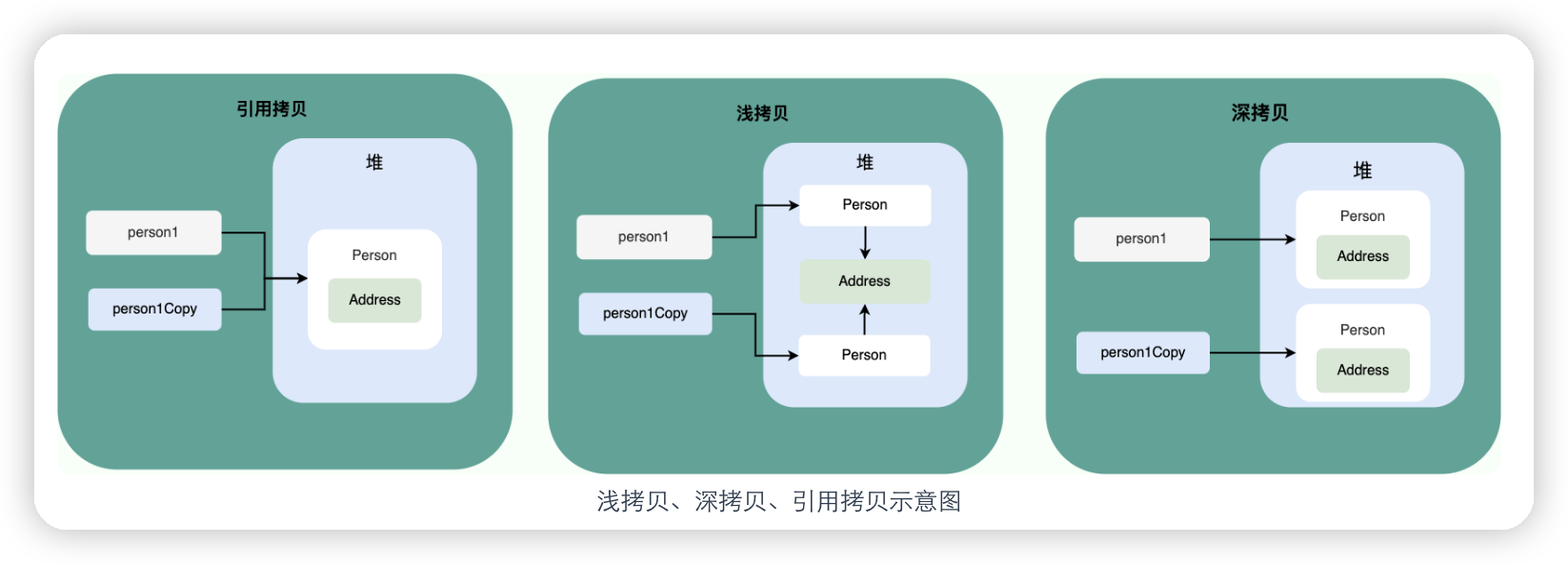
深拷贝和浅拷贝
-
浅拷贝:浅拷贝会在堆上创建一个新的对象(区别于引用拷贝的一点),不过,如果原对象内部的属性是引用类型的话,浅拷贝会直接复制内部对象的引用地址,也就是说拷贝对象和原对象共用同一个内部对象。
-
深拷贝:深拷贝会完全复制整个对象,包括这个对象所包含的内部对象。
1
2
3
4
5
6
7
8
String a = new String("ab"); // a 为一个引用
String b = new String("ab"); // b为另一个引用,对象的内容一样
String aa = "ab"; // 放在常量池中
String bb = "ab"; // 从常量池中查找
System.out.println(aa == bb);// true
System.out.println(a == b);// false
System.out.println(a.equals(b));// true
System.out.println(42 == 42.0);// true
hashCode
hashCode() 的作用是获取哈希码(int 整数),也称为散列码。这个哈希码的作用是确定该对象在哈希表中的索引位置
如果两个对象的hashCode 值相等,那这两个对象不一定相等(哈希碰撞)。
如果两个对象的hashCode 值相等并且equals()方法也返回 true,我们才认为这两个对象相等。
如果两个对象的hashCode 值不相等,我们就可以直接认为这两个对象不相等
如果重写 equals() 时没有重写 hashCode() 方法的话就可能会导致 equals 方法判断是相等的两个对象,hashCode 值却不相等
String、StringBuffer、StringBuilder 的区别
可变性
String 是不可变的
StringBuilder 与 StringBuffer 都继承自 AbstractStringBuilder 类,在 AbstractStringBuilder 中也是使用字符数组保存字符串,不过没有使用 final 和 private 关键字修饰,最关键的是这个 AbstractStringBuilder 类还提供了很多修改字符串的方法比如 append 方法
线程安全性
String 中的对象是不可变的,也就可以理解为常量,线程安全。
StringBuffer 对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。
StringBuilder 并没有对方法进行加同步锁,所以是非线程安全的。
性能
String 类型进行改变的时候,都会生成一个新的 String 对象
StringBuffer 每次都会对 StringBuffer 对象本身进行操作,而不是生成新的对象并改变对象引用。
相同情况下使用 StringBuilder 相比使用 StringBuffer 仅能获得 10%~15% 左右的性能提升,但却要冒多线程不安全的风险
总结
- 操作少量的数据: 适用
String - 单线程操作字符串缓冲区下操作大量数据: 适用
StringBuilder - 多线程操作字符串缓冲区下操作大量数据: 适用
StringBuffer
String类型的不可变性
String 类中使用 final 关键字修饰字符数组来保存字符串,但这不是其不可变的原因,因为对于final来说,被 final 关键字修饰的类不能被继承,修饰的方法不能被重写,修饰的变量是基本数据类型则值不能改变,修饰的变量是引用类型则不能再指向其他对象
不可变的原因:
- 保存字符串的数组被
final修饰且为私有的,并且String类没有提供/暴露修改这个字符串的方法。 String类被final修饰导致其不能被继承,进而避免了子类破坏String不可变。
字符串拼接用“+” 还是 StringBuilder
字符串对象通过“+”的字符串拼接方式,实际上是通过 StringBuilder 调用 append() 方法实现的,拼接完成之后调用 toString() 得到一个 String 对象
即先创建StringBuilder对象,然后用append进行拼接,然后toString转回String对象
这种方式会创建多个StringBuilder对象,空间上产生了浪费
如果直接使用 StringBuilder 对象进行字符串拼接的话,就不会存在这个问题了。
1
2
3
4
5
6
String[] arr = {"he", "llo", "world"};
StringBuilder s = new StringBuilder();
for (String value : arr) {
s.append(value);
}
System.out.println(s);
String 中的 equals 方法是被重写过的,比较的是 String 字符串的值是否相等。 Object 的 equals 方法是比较的对象的内存地址
String s1 = new String(“abc”)
上面这句话会创建1-2个对象,依据常量池中是否含有该字符串常量来判断
-
如果常量池含有该字符串常量
则会创建一个对象,即new的时候会创建一个对象
-
如果常量池不含有该字符串常量
会创建两个对象,new的时候会创建一个对象,然后会创建一个字符串对象abc,进行赋值
intern 方法的作用
String.intern() 是一个 native(本地)方法,其作用是将指定的字符串对象的引用保存在字符串常量池中,可以简单分为两种情况:
- 如果字符串常量池中保存了对应的字符串对象的引用,就直接返回该引用。
- 如果字符串常量池中没有保存了对应的字符串对象的引用,那就在常量池中创建一个指向该字符串对象的引用并返回。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// 在堆中创建字符串对象”Java“
// 将字符串对象”Java“的引用保存在字符串常量池中
String s1 = "Java";
// 直接返回字符串常量池中字符串对象”Java“对应的引用
String s2 = s1.intern();
// 会在堆中在单独创建一个字符串对象
String s3 = new String("Java");
// 直接返回字符串常量池中字符串对象”Java“对应的引用
String s4 = s3.intern();
// s1 和 s2 指向的是堆中的同一个对象
System.out.println(s1 == s2); // true
// s3 和 s4 指向的是堆中不同的对象
System.out.println(s3 == s4); // false
// s1 和 s4 指向的是堆中的同一个对象
System.out.println(s1 == s4); //true

异常处理
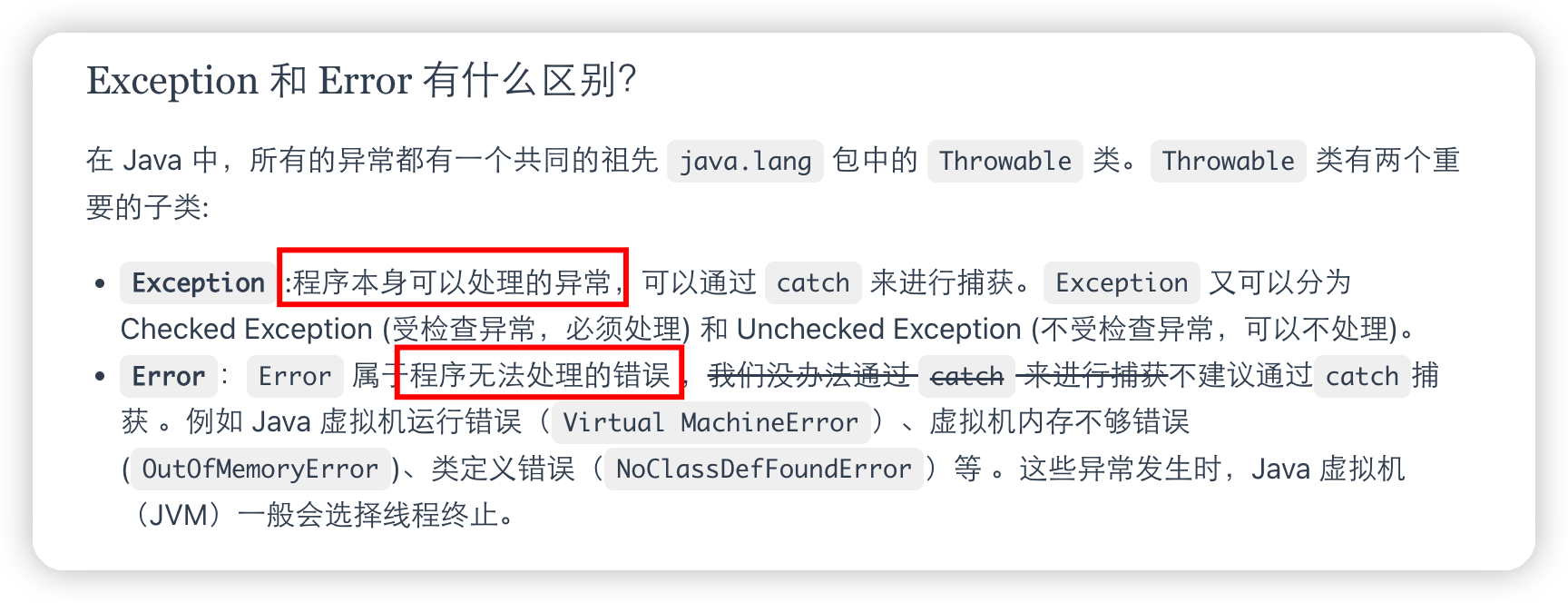
受检测异常和非受检测异常
Checked Exception 即 受检查异常 ,Java 代码在编译过程中,如果受检查异常没有被 catch或者throws 关键字处理的话,就没办法通过编译
Unchecked Exception 即 不受检查异常 ,Java 代码在编译过程中 ,我们即使不处理不受检查异常也可以正常通过编译
除了RuntimeException及其子类以外,其他的Exception类及其子类都属于受检查异常 。常见的受检查异常有:IO 相关的异常、ClassNotFoundException、SQLException…。
Throwable类常用方法
String getMessage(): 返回异常发生时的简要描述String toString(): 返回异常发生时的详细信息String getLocalizedMessage(): 返回异常对象的本地化信息。使用Throwable的子类覆盖这个方法,可以生成本地化信息。如果子类没有覆盖该方法,则该方法返回的信息与getMessage()返回的结果相同void printStackTrace(): 在控制台上打印Throwable对象封装的异常信息
try-catch-finally
try作用是捕获异常,catch是处理异常,finally是最后都是进入finally
当在 try 块或 catch 块中遇到 return 语句时,finally 语句块将在方法返回之前被执行。
因此注意:不要在 finally 语句块中使用 return! 当 try 语句和 finally 语句中都有 return 语句时,try 语句块中的 return 语句会被忽略。这是因为 try 语句中的 return 返回值会先被暂存在一个本地变量中,当执行到 finally 语句中的 return 之后,这个本地变量的值就变为了 finally 语句中的 return 返回值
并且finally中的代码也不是一定会执行,就比如说 finally 之前虚拟机被终止运行的话,finally 中的代码就不会被执行。或者程序所在的线程死亡,关闭 CPU。
try-with-resources
面对必须要关闭的资源,我们总是应该优先使用 try-with-resources 而不是try-finally。随之产生的代码更简短,更清晰,产生的异常对我们也更有用。try-with-resources语句让我们更容易编写必须要关闭的资源的代码,若采用try-finally则几乎做不到这点。
1
2
3
4
5
6
7
8
9
10
try (BufferedInputStream bin = new BufferedInputStream(new FileInputStream(new File("test.txt")));
BufferedOutputStream bout = new BufferedOutputStream(new FileOutputStream(new File("out.txt")))) {
int b;
while ((b = bin.read()) != -1) {
bout.write(b);
}
}
catch (IOException e) {
e.printStackTrace();
}
泛型
允许在类、接口和方法中使用类型参数。它提供了编译时类型安全检查的优点,这意味着您可以在编译时捕获到不正确的类型使用,而不是在运行时。泛型的引入减少了对强制类型转换的需求,并提供了更加抽象和通用的编程方式。
泛型一般使用有三种方式
-
泛型类
1 2 3 4 5 6 7 8 9 10 11 12 13 14
//此处T可以随便写为任意标识,常见的如T、E、K、V等形式的参数常用于表示泛型 //在实例化泛型类时,必须指定T的具体类型 public class Generic<T>{ private T key; public Generic(T key) { this.key = key; } public T getKey(){ return key; } }
-
泛型接口
1 2 3 4
public interface Generator<T> { public T method(); }
-
泛型方法
1 2 3 4 5 6 7
public static < E > void printArray( E[] inputArray ) { for ( E element : inputArray ){ System.out.printf( "%s ", element ); } System.out.println(); }
反射
在运行时分析类以及执行类中方法的能力,通过反射你可以获取任意一个类的所有属性和方法,你还可以调用这些方法和属性
其主要使用步骤:
- 在运行时获取类的信息: 反射可以用来在运行时获取类的信息,比如类的名称、方法、字段和注解等。这对于理解未知代码或动态生成代码非常有用。
- 动态创建对象和调用方法: 使用反射可以动态地创建对象和调用方法,即使在编译时这些类或方法是未知的。
- 修改字段值: 即使字段被声明为私有,反射也能够修改它们的值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
public class ReflectionExample {
private int number;
private String name;
public ReflectionExample(int number, String name) {
this.number = number;
this.name = name;
}
public void printInfo() {
System.out.println("Number: " + number + ", Name: " + name);
}
public static void main(String[] args) throws Exception {
// 使用反射创建对象
Class<?> clazz = ReflectionExample.class;
Constructor<?> constructor = clazz.getConstructor(int.class, String.class);
Object instance = constructor.newInstance(10, "Test");
// 调用方法
Method method = clazz.getMethod("printInfo");
method.invoke(instance);
// 访问字段
Field field = clazz.getDeclaredField("name");
field.setAccessible(true); // 对于私有字段需要这样做
field.set(instance, "New Name");
method.invoke(instance);
}
}
缺点:
- 反射操作通常比直接的 Java 代码执行要慢,因为涉及到动态类型检查和方法调用。
- 反射破坏了封装,可能会导致意外的副作用,尤其是在访问私有字段和方法时。
- 在受限的环境(如 Applet 或服务器应用程序)中,安全策略可能会限制反射的使用。
为什么使用 Spring 的时候 ,一个@Component注解就声明了一个类为 Spring Bean 呢?为什么通过一个 @Value注解就读取到配置文件中的值呢?究竟是怎么起作用的呢?
这些都是因为你可以基于反射分析类,然后获取到类/属性/方法/方法的参数上的注解。你获取到注解之后,就可以做进一步的处理。
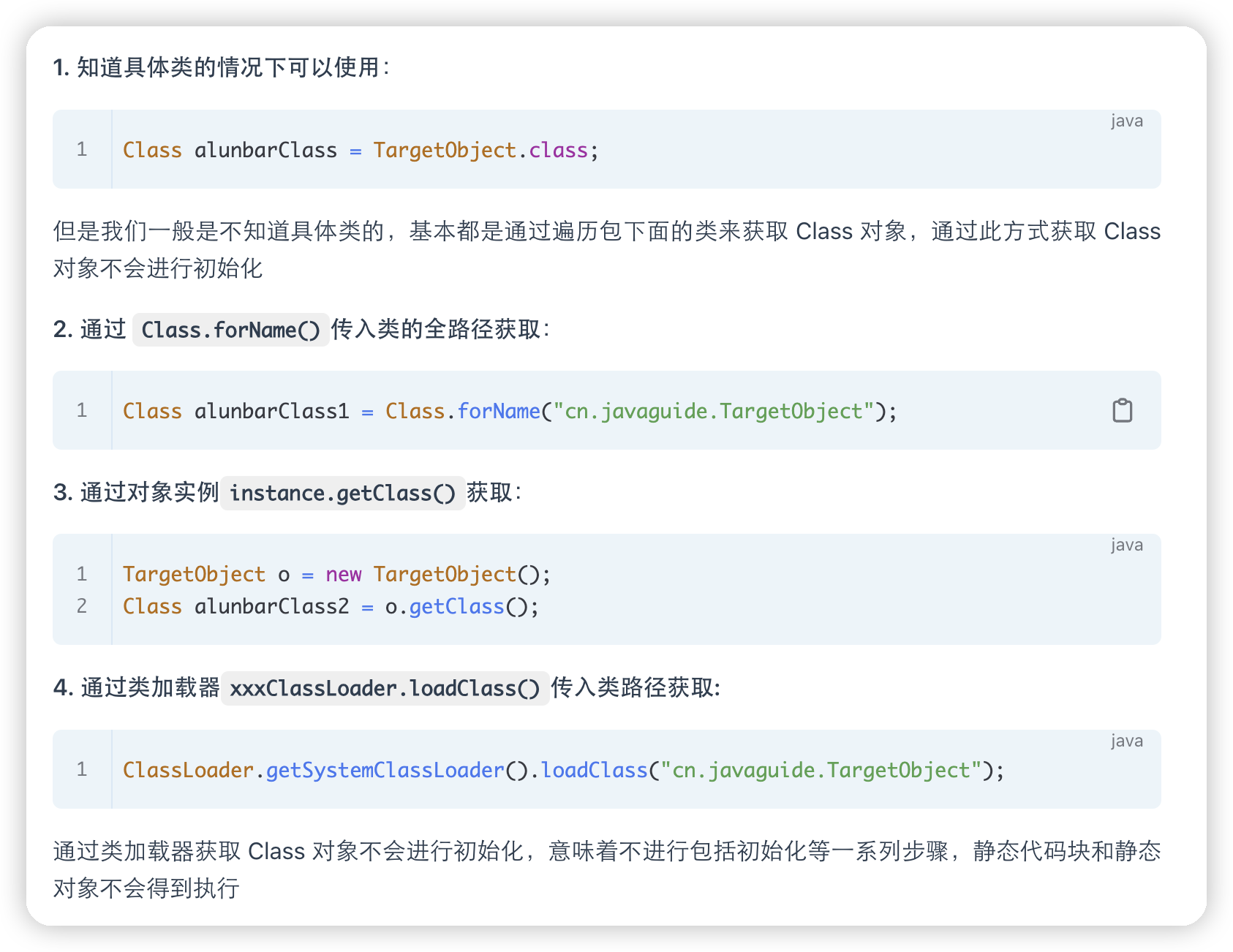
获取class对象的四种方式
代理模式
使用代理对象来代替对真实对象(real object)的访问,这样就可以在不修改原目标对象的前提下,提供额外的功能操作,扩展目标对象的功能
代理模式的主要作用是扩展目标对象的功能,比如说在目标对象的某个方法执行前后你可以增加一些自定义的操作
代理模式有静态代理和动态代理两种实现方式
静态代理
静态代理中,我们对目标对象的每个方法的增强都是手动完成的(后面会具体演示代码),非常不灵活(比如接口一旦新增加方法,目标对象和代理对象都要进行修改)且麻烦(需要对每个目标类都单独写一个代理类)
静态代理在编译时就将接口、实现类、代理类这些都变成了一个个实际的 class 文件。
静态代理的步骤:
- 定义一个接口及其实现类;
- 创建一个代理类同样实现这个接口
- 将目标对象注入进代理类,然后在代理类的对应方法调用目标类中的对应方法。这样的话,我们就可以通过代理类屏蔽对目标对象的访问,并且可以在目标方法执行前后做一些自己想做的事情。
动态代理
相比于静态代理来说,动态代理更加灵活。我们不需要针对每个目标类都单独创建一个代理类,并且也不需要我们必须实现接口,我们可以直接代理实现类
使用步骤:
- 定义一个接口,声明需要代理的方法。
- 创建一个实现了
InvocationHandler接口的类,并定义在方法调用时想要执行的逻辑。 - 使用
Proxy.newProxyInstance方法创建代理对象,这个方法需要三个参数:类加载器、一组接口以及InvocationHandler实例。
注解的分析方式
- 编译期直接扫描:编译器在编译 Java 代码的时候扫描对应的注解并处理,比如某个方法使用
@Override注解,编译器在编译的时候就会检测当前的方法是否重写了父类对应的方法。 - 运行期通过反射处理:像框架中自带的注解(比如 Spring 框架的
@Value、@Component)都是通过反射来进行处理的。
SPI
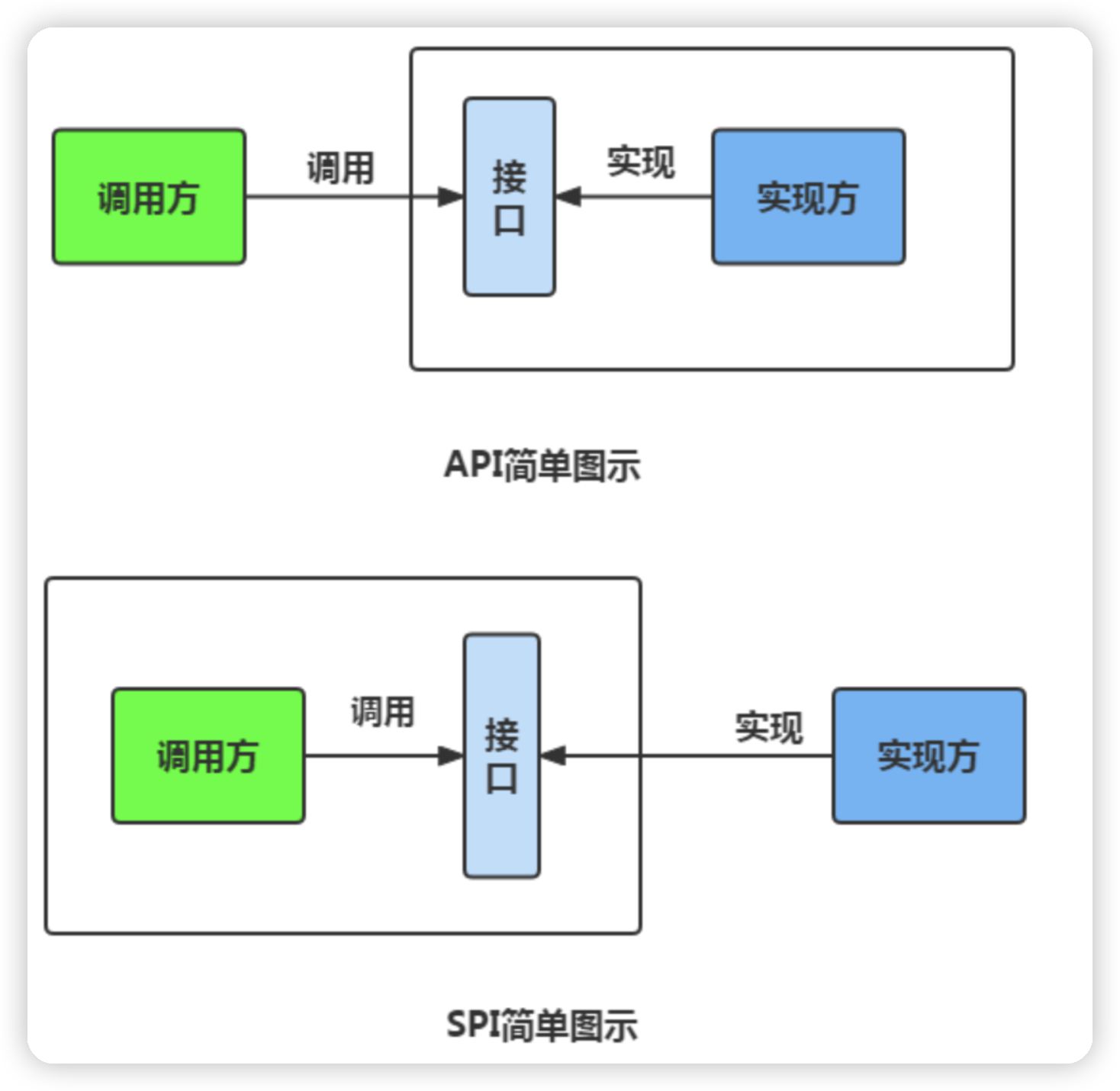
API是接口提供方提供方法实现,用户就可以直接调用接口进行使用
SPI是由接口调用方确定接口规则,然后由不同的厂商去根据这个规则对这个接口进行实现,从而提供服务。
SPI机制能够大大地提高接口设计的灵活性,但也有一些缺点
- 需要遍历加载所有的实现类,不能做到按需加载,这样效率还是相对较低的。
- 当多个
ServiceLoader同时load时,会有并发问题。
序列化和反序列化
- 序列化:将数据结构或对象转换成二进制字节流的过程
- 反序列化:将在序列化过程中所生成的二进制字节流转换成数据结构或者对象的过程
序列化的都是对象(Object)也就是实例化后的类(Class)
序列化的主要目的是通过网络传输对象或者说是将对象存储到文件系统、数据库、内存中。
序列化协议在osi七层协议中是表示层,在tcp/ip四层协议中就是应用层

对于不想进行序列化的变量,使用 transient 关键字修饰。
transient 关键字的作用是:阻止实例中那些用此关键字修饰的的变量序列化;当对象被反序列化时,被 transient 修饰的变量值不会被持久化和恢复。
关于 transient 还有几点注意:
transient只能修饰变量,不能修饰类和方法。transient修饰的变量,在反序列化后变量值将会被置成类型的默认值。例如,如果是修饰int类型,那么反序列后结果就是0。static变量因为不属于任何对象(Object),所以无论有没有transient关键字修饰,均不会被序列化。
JDK自带的也有序列化方式,但一般不使用,其原因是:
- 不支持跨语言调用 : 如果调用的是其他语言开发的服务的时候就不支持了。
- 性能差:相比于其他序列化框架性能更低,主要原因是序列化之后的字节数组体积较大,导致传输成本加大。
- 存在安全问题:序列化和反序列化本身并不存在问题。但当输入的反序列化的数据可被用户控制,那么攻击者即可通过构造恶意输入,让反序列化产生非预期的对象,在此过程中执行构造的任意代码。
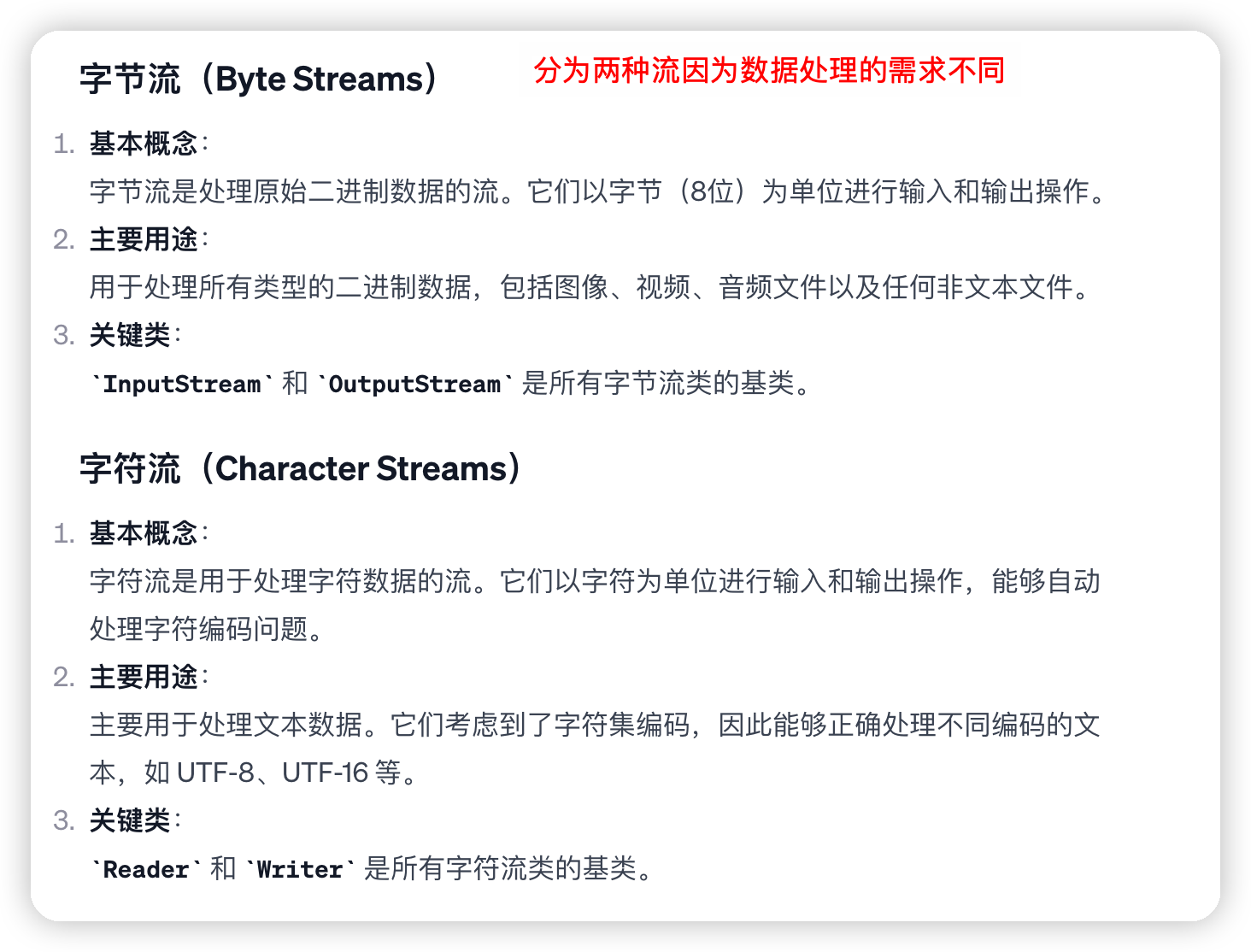
I/O
Java IO 流的 40 多个类都是从如下 4 个抽象类基类中派生出来的。
InputStream/Reader: 所有的输入流的基类,前者是字节输入流,后者是字符输入流。OutputStream/Writer: 所有输出流的基类,前者是字节输出流,后者是字符输出流。
语法糖
为了方便程序员开发程序而设计的一种特殊语法,这种语法对编程语言的功能并没有影响。实现相同的功能,基于语法糖写出来的代码往往更简单简洁且更易阅读,例如for-each
不过,JVM 其实并不能识别语法糖,Java 语法糖要想被正确执行,需要先通过编译器进行解糖,也就是在程序编译阶段将其转换成 JVM 认识的基本语法。这也侧面说明,Java 中真正支持语法糖的是 Java 编译器而不是 JVM
参数传递
在java中引用传递,传递的是引用类型的地址
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
public class Person {
private String name;
// 省略构造函数、Getter&Setter方法
}
public static void main(String[] args) {
Person xiaoZhang = new Person("小张");
Person xiaoLi = new Person("小李");
swap(xiaoZhang, xiaoLi);
System.out.println("xiaoZhang:" + xiaoZhang.getName());
System.out.println("xiaoLi:" + xiaoLi.getName());
}
public static void swap(Person person1, Person person2) {
Person temp = person1;
person1 = person2;
person2 = temp;
System.out.println("person1:" + person1.getName());
System.out.println("person2:" + person2.getName());
}
输出:
person1:小李
person2:小张
xiaoZhang:小张
xiaoLi:小李
像上面这种情况,记住传递的是地址,所以swap中进行交换,只是把这些对象指向的地址换了,在原方法中这些对象的地址是没变的
Unsafe
主要提供一些用于执行低级别、不安全操作的方法,如直接访问系统内存资源、自主管理内存资源等
集合面试题
List
ArrayList和Array的区别
ArrayList 内部基于动态数组实现,比 Array(静态数组) 使用起来更加灵活:
ArrayList会根据实际存储的元素动态地扩容或缩容,而Array被创建之后就不能改变它的长度了。ArrayList允许你使用泛型来确保类型安全,Array则不可以。ArrayList中只能存储对象。对于基本类型数据,需要使用其对应的包装类(如 Integer、Double 等)。Array可以直接存储基本类型数据,也可以存储对象。ArrayList支持插入、删除、遍历等常见操作,并且提供了丰富的 API 操作方法,比如add()、remove()等。Array只是一个固定长度的数组,只能按照下标访问其中的元素,不具备动态添加、删除元素的能力。
ArrayList创建时不需要指定大小,而Array创建时必须指定大小。

ArrayList插入和删除元素时间复杂度
对于插入:
- 头部插入:由于需要将所有元素都依次向后移动一个位置,因此时间复杂度是 O(n)。
- 尾部插入:当
ArrayList的容量未达到极限时,往列表末尾插入元素的时间复杂度是 O(1),因为它只需要在数组末尾添加一个元素即可;当容量已达到极限并且需要扩容时,则需要执行一次 O(n) 的操作将原数组复制到新的更大的数组中,然后再执行 O(1) 的操作添加元素。 - 指定位置插入:需要将目标位置之后的所有元素都向后移动一个位置,然后再把新元素放入指定位置。这个过程需要移动平均 n/2 个元素,因此时间复杂度为 O(n)。
对于删除:
- 头部删除:由于需要将所有元素依次向前移动一个位置,因此时间复杂度是 O(n)。
- 尾部删除:当删除的元素位于列表末尾时,时间复杂度为 O(1)。
- 指定位置删除:需要将目标元素之后的所有元素向前移动一个位置以填补被删除的空白位置,因此需要移动平均 n/2 个元素,时间复杂度为 O(n)。
LinkedList 插入和删除元素
头部插入/删除:只需要修改头结点的指针即可完成插入/删除操作,因此时间复杂度为 O(1)。
尾部插入/删除:只需要修改尾结点的指针即可完成插入/删除操作,因此时间复杂度为 O(1)。
指定位置插入/删除:需要先移动到指定位置,再修改指定节点的指针完成插入/删除,因此需要移动平均 n/2 个元素,时间复杂度为 O(n)
ArrayList 与 LinkedList 区别
- 是否保证线程安全:
ArrayList和LinkedList都是不同步的,也就是不保证线程安全; - 底层数据结构:
ArrayList底层使用的是Object数组;LinkedList底层使用的是 双向链表 数据结构(JDK1.6 之前为循环链表,JDK1.7 取消了循环) - 插入和删除是否受元素位置的影响:
ArrayList采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。 比如:执行add(E e)方法的时候,ArrayList会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是 O(1)。但是如果要在指定位置 i 插入和删除元素的话(add(int index, E element)),时间复杂度就为 O(n)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。LinkedList采用链表存储,所以在头尾插入或者删除元素不受元素位置的影响(add(E e)、addFirst(E e)、addLast(E e)、removeFirst()、removeLast()),时间复杂度为 O(1),如果是要在指定位置i插入和删除元素的话(add(int index, E element),remove(Object o),remove(int index)), 时间复杂度为 O(n) ,因为需要先移动到指定位置再插入和删除。
- 是否支持快速随机访问:
LinkedList不支持高效的随机元素访问,而ArrayList(实现了RandomAccess接口) 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于get(int index)方法)。 - 内存空间占用:
ArrayList的空间浪费主要体现在在 list 列表的结尾会预留一定的容量空间,而 LinkedList 的空间花费则体现在它的每一个元素都需要消耗比 ArrayList 更多的空间(因为要存放直接后继和直接前驱以及数据)
Set
Comparable 和 Comparator 的区别
Comparable 接口和 Comparator 接口都是 Java 中用于排序的接口,它们在实现类对象之间比较大小、排序等方面发挥了重要作用:
Comparable接口实际上是出自java.lang包,它有一个compareTo(Object obj)方法用来排序Comparator接口实际上是出自java.util包,它有一个compare(Object obj1, Object obj2)方法用来排序
比较 HashSet、LinkedHashSet 和 TreeSet 三者的异同
底层实现不同
HashSet、LinkedHashSet和TreeSet都是Set接口的实现类,都能保证元素唯一,并且都不是线程安全的。HashSet、LinkedHashSet和TreeSet的主要区别在于底层数据结构不同。HashSet的底层数据结构是哈希表(基于HashMap实现)。LinkedHashSet的底层数据结构是链表和哈希表,元素的插入和取出顺序满足 FIFO。TreeSet底层数据结构是红黑树,元素是有序的,排序的方式有自然排序和定制排序。- 底层数据结构不同又导致这三者的应用场景不同。
HashSet用于不需要保证元素插入和取出顺序的场景,LinkedHashSet用于保证元素的插入和取出顺序满足 FIFO 的场景,TreeSet用于支持对元素自定义排序规则的场景。
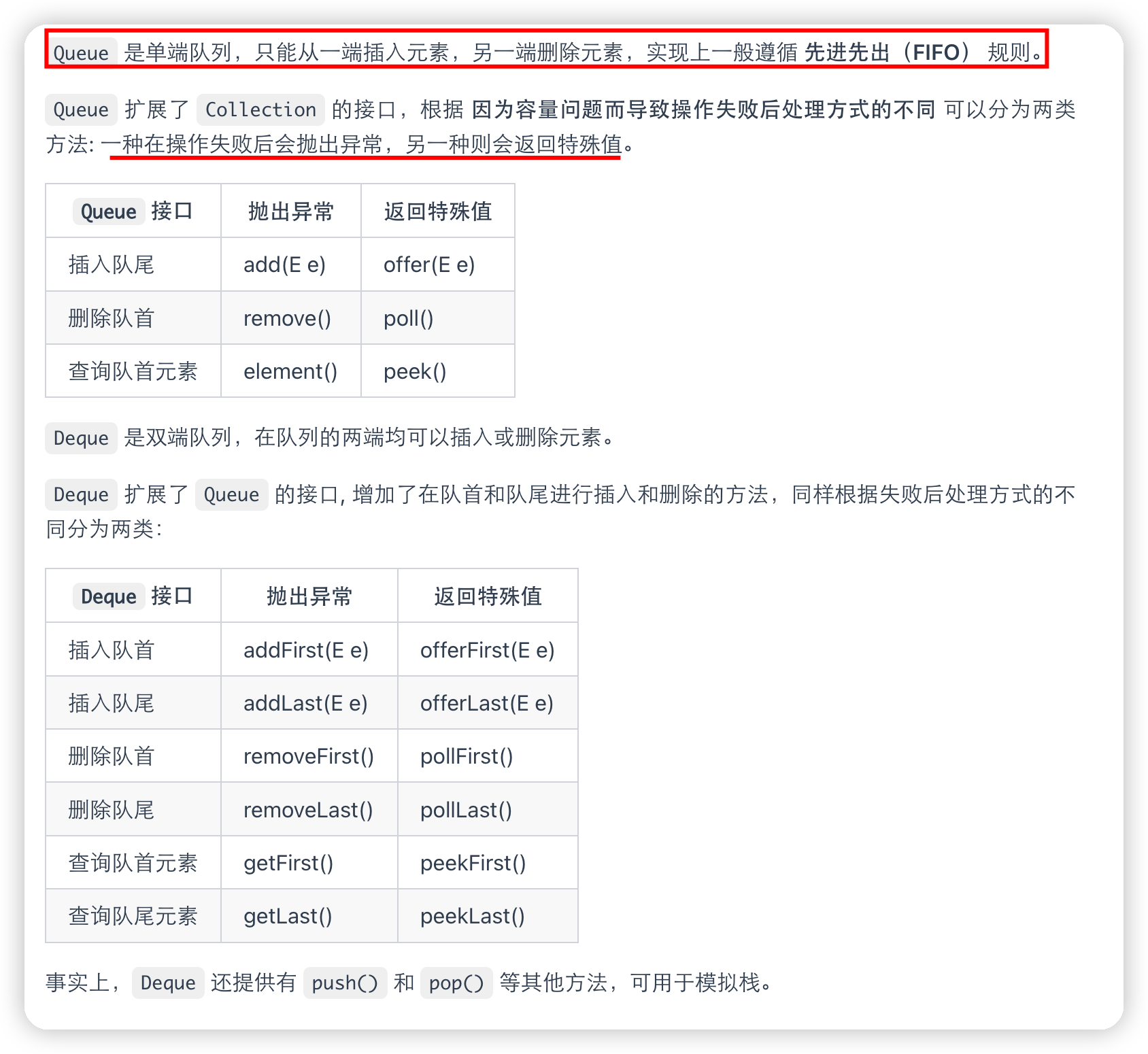
Queue
Queue 与 Deque 的区别
ArrayDeque 与 LinkedList 的区别
ArrayDeque是基于可变长的数组和双指针来实现,而LinkedList则通过链表来实现。ArrayDeque不支持存储NULL数据,但LinkedList支持。ArrayDeque是在 JDK1.6 才被引入的,而LinkedList早在 JDK1.2 时就已经存在。ArrayDeque插入时可能存在扩容过程, 不过均摊后的插入操作依然为 O(1)。虽然LinkedList不需要扩容,但是每次插入数据时均需要申请新的堆空间,均摊性能相比更慢。
从性能的角度上,选用 ArrayDeque 来实现队列要比 LinkedList 更好
PriorityQueue
其与 Queue 的区别在于元素出队顺序是与优先级相关的,即总是优先级最高的元素先出队。
-
PriorityQueue利用了二叉堆的数据结构来实现的,底层使用可变长的数组来存储数据 -
PriorityQueue通过堆元素的上浮和下沉,实现了在 O(logn) 的时间复杂度内插入元素和删除堆顶元素。 -
PriorityQueue是非线程安全的,且不支持存储NULL和non-comparable的对象。 -
PriorityQueue默认是小顶堆,但可以接收一个Comparator作为构造参数,从而来自定义元素优先级的先后。
BlockingQueue
BlockingQueue (阻塞队列)是一个接口,继承自 Queue。
BlockingQueue阻塞的原因是其支持当队列没有元素时一直阻塞,直到有元素;还支持如果队列已满,一直等到队列可以放入新元素时再放入。
BlockingQueue接口有很多实现类,包括ArrayBlockingQueue、LinkedBlockingQueue等
ArrayBlockingQueue 和 LinkedBlockingQueue 有什么区别
- 底层实现:
ArrayBlockingQueue基于数组实现,而LinkedBlockingQueue基于链表实现。 - 是否有界:
ArrayBlockingQueue是有界队列,必须在创建时指定容量大小。LinkedBlockingQueue创建时可以不指定容量大小,默认是Integer.MAX_VALUE,也就是无界的。但也可以指定队列大小,从而成为有界的。 - 锁是否分离:
ArrayBlockingQueue中的锁是没有分离的,即生产和消费用的是同一个锁;LinkedBlockingQueue中的锁是分离的,即生产用的是putLock,消费是takeLock,这样可以防止生产者和消费者线程之间的锁争夺。 - 内存占用:
ArrayBlockingQueue需要提前分配数组内存,而LinkedBlockingQueue则是动态分配链表节点内存。这意味着,ArrayBlockingQueue在创建时就会占用一定的内存空间,且往往申请的内存比实际所用的内存更大,而LinkedBlockingQueue则是根据元素的增加而逐渐占用内存空间。
Map
HashMap 和 Hashtable 的区别
-
线程是否安全:
HashMap是非线程安全的,Hashtable是线程安全的因为
Hashtable内部的方法基本都经过synchronized修饰。(如果你要保证线程安全的话就使用ConcurrentHashMap吧!); -
效率: 因为线程安全的问题,
HashMap要比Hashtable效率高一点另外,
Hashtable基本被淘汰,不要在代码中使用它; -
对 Null key 和 Null value 的支持:
HashMap可以存储 null 的 key 和 value,但 null 作为键只能有一个,null 作为值可以有多个;Hashtable 不允许有 null 键和 null 值,否则会抛出
NullPointerException。 -
初始容量大小和每次扩充容量大小的不同:
① 创建时如果不指定容量初始值,
Hashtable默认的初始大小为 11,之后每次扩充,容量变为原来的 2n+1。HashMap默认的初始化大小为 16。之后每次扩充,容量变为原来的 2 倍。② 创建时如果给定了容量初始值,那么
Hashtable会直接使用你给定的大小,而HashMap会将其扩充为 2 的幂次方大小(HashMap中的tableSizeFor()方法保证)。也就是说HashMap总是使用 2 的幂作为哈希表的大小原因是:希望哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的,用之前还要先做对数组的长度取模运算,得到的余数才能用来要存放的位置也就是对应的数组下标。这个数组下标的计算方法是“
(n - 1) & hash” -
底层数据结构: JDK1.8 以后的
HashMap在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树),以减少搜索时间(后文中我会结合源码对这一过程进行分析)。Hashtable没有这样的机制。
hashmap设置初始容量时的源码,这段代码通过位运算确定最接近并大于等于给定容量 cap 的 2 的幂的值
1
2
3
4
5
6
7
8
9
10
11
12
/**
* Returns a power of two size for the given target capacity.
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
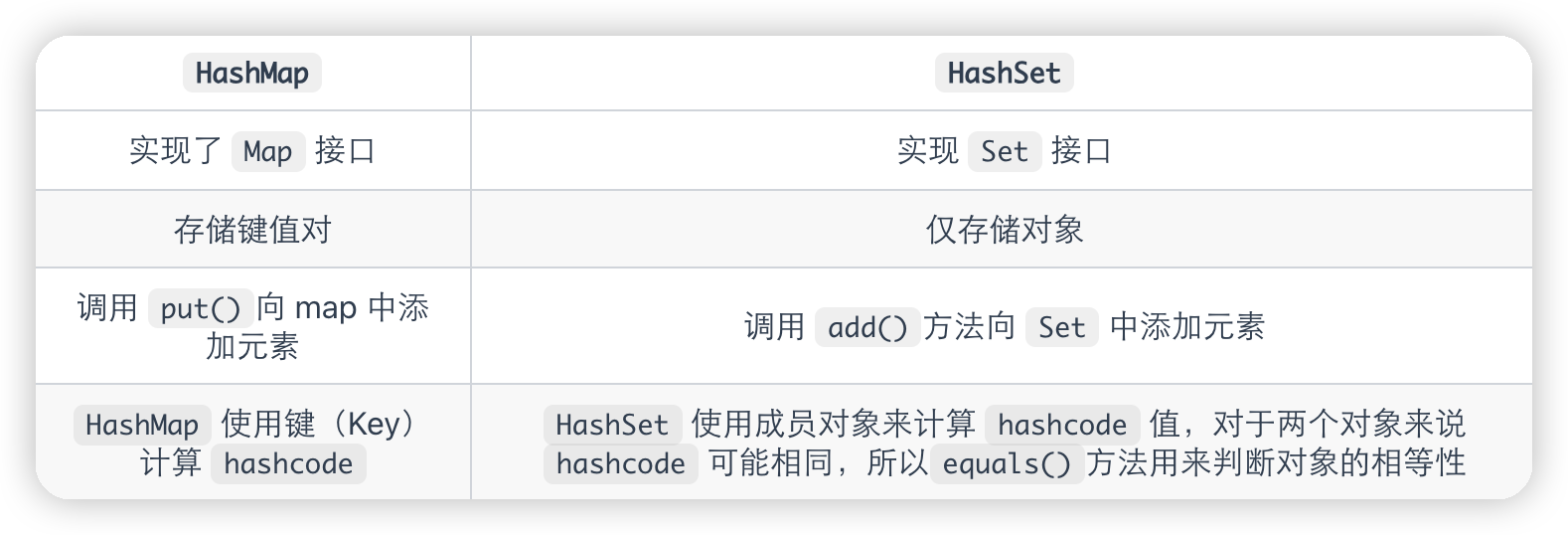
HashMap 和 HashSet 区别
HashSet 底层就是基于 HashMap 实现的。(HashSet 的源码非常非常少,因为除了 clone()、writeObject()、readObject()是 HashSet 自己不得不实现之外,其他方法都是直接调用 HashMap 中的方法
HashMap 和 TreeMap 区别
TreeMap它还实现了NavigableMap接口和SortedMap 接口,因此多了对集合中的元素根据键排序的能力以及对集合内元素的搜索的能力
HashSet 如何检查重复
当你把对象加入HashSet时,HashSet 会先计算对象的hashcode值来判断对象加入的位置,同时也会与其他加入的对象的 hashcode 值作比较,如果没有相符的 hashcode,HashSet 会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调用equals()方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让加入操作成功
HashMap 的底层实现
JDK1.8 之前 HashMap 底层是 数组和链表 结合在一起使用也就是 链表散列。HashMap 通过 key 的 hashcode 经过扰动函数处理过后得到 hash 值,然后通过 (n - 1) & hash (取余)判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。
扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。
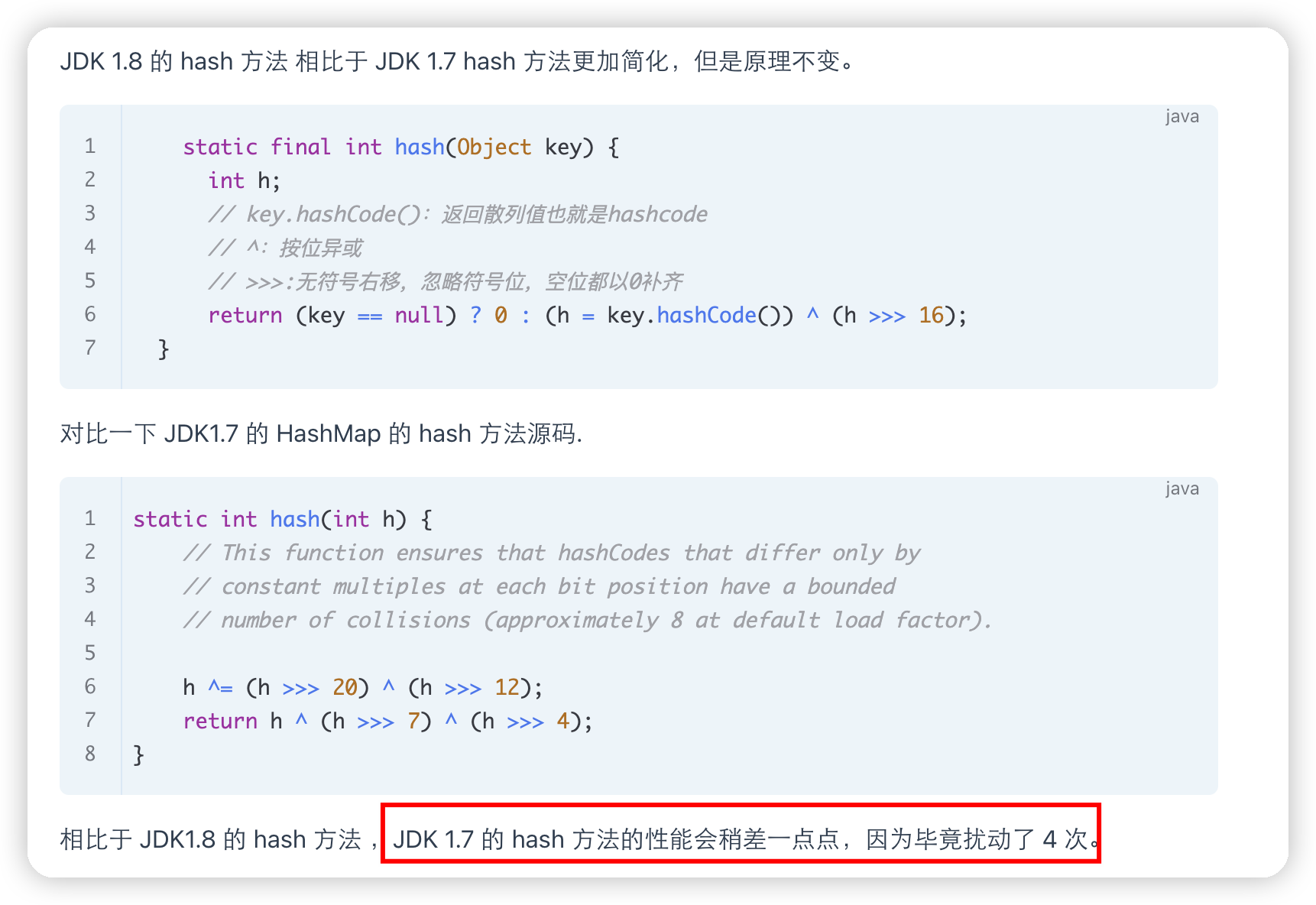
JDK1.8 之后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间
红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。
HashMap 多线程操作导致死循环问题
JDK1.7 及之前版本的 HashMap 在多线程环境下扩容操作可能存在死循环问题,其原因是当一个桶位中有多个元素需要进行扩容时,多个线程同时对链表进行操作,头插法可能会导致链表中的节点指向错误的位置,从而形成一个环形链表,进而使得查询元素的操作陷入死循环无法结束。

JDK1.8 版本的 HashMap 采用了尾插法而不是头插法来避免链表倒置,使得插入的节点永远都是放在链表的末尾,保持了节点原来的相对顺序,避免了链表中的环形结构。但是还是不建议在多线程下使用 HashMap,因为多线程下使用 HashMap 还是会存在数据覆盖的问题。并发环境下,推荐使用 ConcurrentHashMap 。
HashMap 为什么线程不安全
JDK1.7 及之前版本,在多线程环境下,HashMap 扩容时会造成死循环和数据丢失的问题。
数据丢失这个在 JDK1.7 和 JDK 1.8 中都存在,这里以 JDK 1.8 为例进行介绍。
JDK 1.8 后,在 HashMap 中,多个键值对可能会被分配到同一个桶(bucket),并以链表或红黑树的形式存储。多个线程对 HashMap 的 put 操作会导致线程不安全,具体来说会有数据覆盖的风险
发生数据丢失的情况:
- 两个线程 1,2 同时进行 put 操作,并且发生了哈希冲突(hash 函数计算出的插入下标是相同的)。
- 不同的线程可能在不同的时间片获得 CPU 执行的机会,当前线程 1 执行完哈希冲突判断后,由于时间片耗尽挂起。线程 2 先完成了插入操作。
- 随后,线程 1 获得时间片,由于之前已经进行过 hash 碰撞的判断,所有此时会直接进行插入,这就导致线程 2 插入的数据被线程 1 覆盖了
HashMap 常见的遍历方式
-
使用
entrySet()遍历1 2 3 4 5
Map<String, Integer> map = new HashMap<>(); // ...添加元素到map中 for (Map.Entry<String, Integer> entry : map.entrySet()) { System.out.println("Key = " + entry.getKey() + ", Value = " + entry.getValue()); }
-
使用
keySet()遍历1 2 3
for (String key : map.keySet()) { System.out.println("Key = " + key + ", Value = " + map.get(key)); }
-
使用
values()遍历1 2 3
for (Integer value : map.values()) { System.out.println("Value = " + value); }
-
使用 Java 8 的
forEach1
map.forEach((key, value) -> System.out.println("Key = " + key + ", Value = " + value));
-
使用迭代器
1 2 3 4 5
Iterator<Map.Entry<String, Integer>> iterator = map.entrySet().iterator(); while (iterator.hasNext()) { Map.Entry<String, Integer> entry = iterator.next(); System.out.println("Key = " + entry.getKey() + ", Value = " + entry.getValue()); }
ConcurrentHashMap 和 Hashtable 的区别
-
底层数据结构
ConcurrentHashMap:在JDK1.7之前分段的数组+链表 ,在JDK1.8后数组+链表/红黑二叉树
HashTable:在JDK1.7之前数组+链表,
-
实现线程安全的方式
ConcurrentMap:
JDK1.7之前,对整个桶数组进行了分割分段(
Segment,分段锁),即 Segment 数组 + HashEntry 数组 + 链表,每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。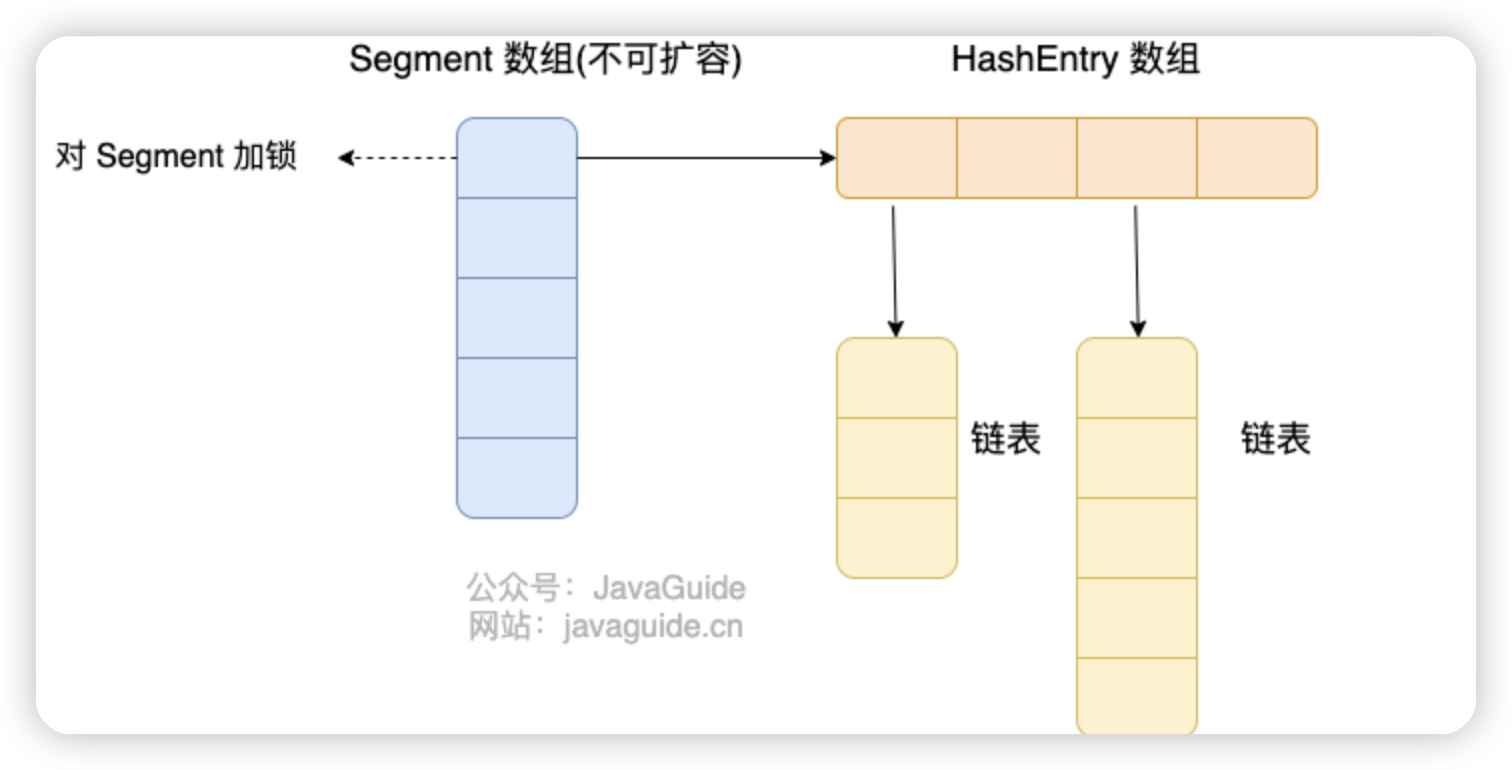
JDK1.8之后 ,已经摒弃了
Segment的概念,而是直接用Node数组+链表+红黑树的数据结构来实现,并发控制使用synchronized和 CAS 来操作。(JDK1.6 以后synchronized锁做了很多优化) 整个看起来就像是优化过且线程安全的HashMap,虽然在 JDK1.8 中还能看到Segment的数据结构,但是已经简化了属性,只是为了兼容旧版本;Hashtable:
使用
synchronized来保证线程安全,效率非常低下
ConcurrentHashMap 线程安全的具体实现方式/底层具体实现
JDK1.8 之前
首先将数据分为一段一段(这个“段”就是 Segment)的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问,参照上图
ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成
一个 ConcurrentHashMap 里包含一个 Segment 数组,Segment 的个数一旦初始化就不能改变。 Segment 数组的大小默认是 16,也就是说默认可以同时支持 16 个线程并发写
每个 Segment 守护着一个 HashEntry 数组里的元素,当对 HashEntry 数组的数据进行修改时,必须首先获得对应的 Segment 的锁。也就是说,对同一 Segment 的并发写入会被阻塞,不同 Segment 的写入是可以并发执行的
JDK1.8 之后
ConcurrentHashMap 取消了 Segment 分段锁,采用 Node + CAS + synchronized 来保证并发安全。数据结构跟 HashMap 1.8 的结构类似,数组+链表/红黑二叉树。Java 8 在链表长度超过一定阈值(8)时将链表(寻址时间复杂度为 O(N))转换为红黑树(寻址时间复杂度为 O(log(N)))。
Java 8 中,锁粒度更细,synchronized 只锁定当前链表或红黑二叉树的首节点,这样只要 hash 不冲突,就不会产生并发,就不会影响其他 Node 的读写,效率大幅提升
ConcurrentHashMap 为什么 key 和 value 不能为 null
key 和 value 不能为 null 主要是为了避免二义性。null 是一个特殊的值,表示没有对象或没有引用。如果你用 null 作为键,那么你就无法区分这个键是否存在于 ConcurrentHashMap 中,还是根本没有这个键。同样,如果你用 null 作为值,那么你就无法区分这个值是否是真正存储在 ConcurrentHashMap 中的,还是因为找不到对应的键而返回的。
但HashMap可以存储,可以通过containsKey来查找,而ConcurrentHashMap,存在一个线程操作该 ConcurrentHashMap 时,其他的线程将该 ConcurrentHashMap 修改的情况,所以无法通过 containsKey(key) 来判断否存在这个键值对,也就没办法解决二义性问题了
多线程下无法正确判定键值对是否存在(存在其他线程修改的情况),单线程是可以的(不存在其他线程修改的情况)
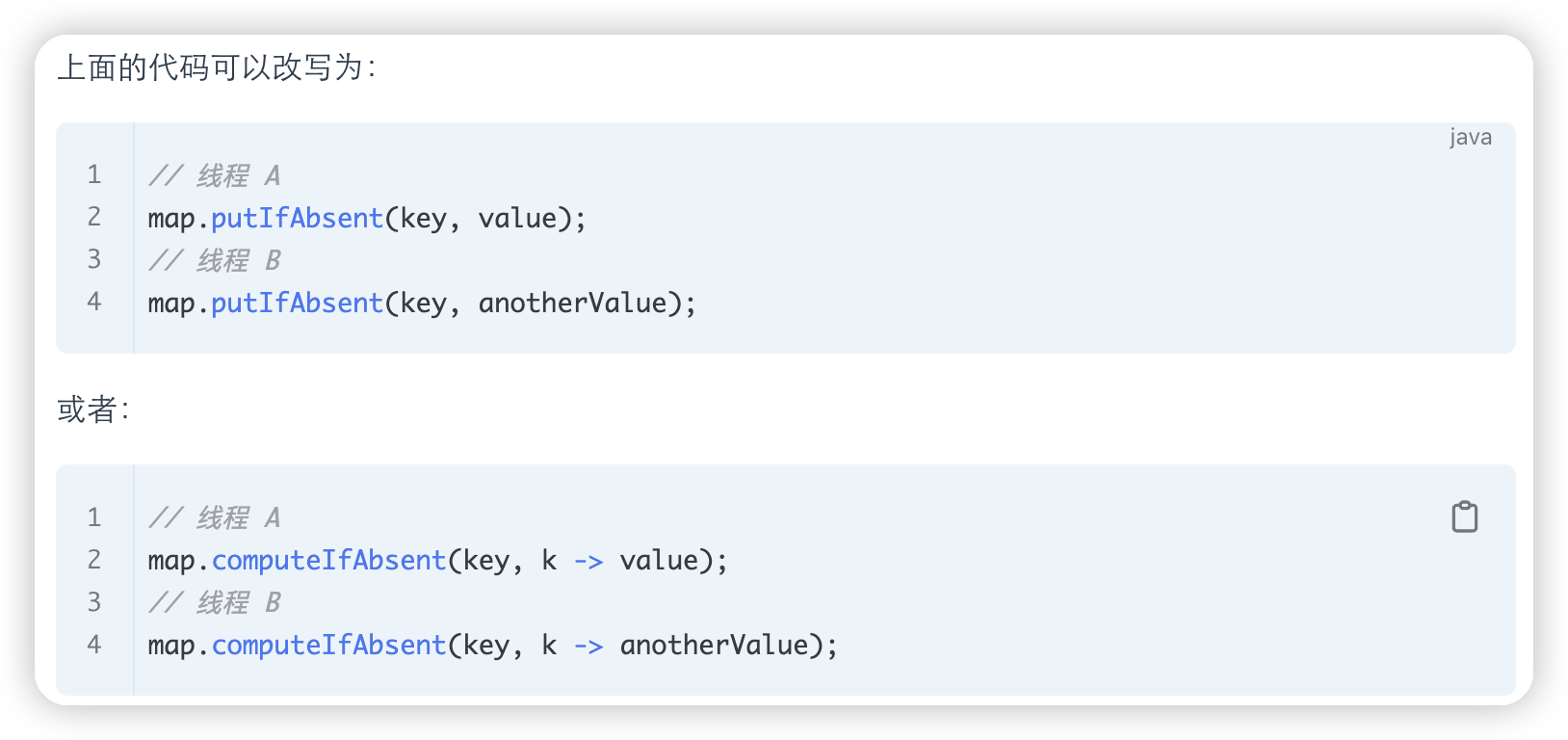
ConcurrentHashMap 能保证复合操作的原子性吗
复合操作是指由多个基本操作(如put、get、remove、containsKey等)组成的操作,例如先判断某个键是否存在containsKey(key),然后根据结果进行插入或更新put(key, value)。这种操作在执行过程中可能会被其他线程打断,导致结果不符合预期
ConcurrentHashMap 提供了一些原子性的复合操作,如 putIfAbsent、compute、computeIfAbsent 、computeIfPresent、merge等。这些方法都可以接受一个函数作为参数,根据给定的 key 和 value 来计算一个新的 value,并且将其更新到 map 中
集合操作的注意事项
集合判空
判断所有集合内部的元素是否为空,使用 isEmpty() 方法,而不是 size()==0 的方式
这是因为 isEmpty() 方法的可读性更好,并且时间复杂度为 O(1),而ConcurrentLinkedQueue、ConcurrentHashMap的size( )的时间复杂度就不是O(1)
集合转 Map
在使用 java.util.stream.Collectors 类的 toMap() 方法转为 Map 集合时,一定要注意当 value 为 null 时会抛 NPE 异常
1
2
3
4
5
6
7
8
9
10
11
12
class Person {
private String name;
private String phoneNumber;
// getters and setters
}
List<Person> bookList = new ArrayList<>();
bookList.add(new Person("jack","18163138123"));
bookList.add(new Person("martin",null));
// 空指针异常
bookList.stream().collect(Collectors.toMap(Person::getName, Person::getPhoneNumber));
因为toMap方法会调用Map 接口的 merge() 方法,merge() 方法会先调用 Objects.requireNonNull() 方法判断 value 是否为空。
集合遍历
不要在 foreach 循环里进行元素的 remove/add 操作。remove 元素请使用 Iterator 方式,如果并发操作,需要对 Iterator 对象加锁
这是因为使用 foreach 循环(或 Java 中的增强型 for 循环)遍历集合时,底层用的是集合的迭代器实现,而集合迭代器在遍历过程中要求集合结构保持不变,所以会抛出ConcurrentModificationException 异常
而使用可以使用迭代器(Iterator)的 remove 方法。这种方式允许你在遍历时修改集合,而不会抛出 ConcurrentModificationException。
1
2
3
4
5
6
7
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
String element = iterator.next();
if (someCondition(element)) {
iterator.remove(); // 安全移除元素
}
}
并且如果在多线程环境中,多个线程同时遍历和修改同一个集合,即使是使用迭代器的 remove 方法,也可能会遇到并发问题
所以在并发操作时,需要对迭代器或集合对象加锁,以保证在一个线程遍历和修改集合时,其他线程不能进行修改。这可以通过同步代码块或使用并发集合来实现,可以使用 synchronized 关键字来实现加锁
集合去重
可以利用 Set 元素唯一的特性,可以快速对一个集合进行去重操作,避免使用 List 的 contains() 进行遍历去重或者判断包含操作
下面是Set和List去重的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
// Set 去重代码示例
public static <T> Set<T> removeDuplicateBySet(List<T> data) {
if (CollectionUtils.isEmpty(data)) {
return new HashSet<>();
}
return new HashSet<>(data);
}
// List 去重代码示例
public static <T> List<T> removeDuplicateByList(List<T> data) {
if (CollectionUtils.isEmpty(data)) {
return new ArrayList<>();
}
List<T> result = new ArrayList<>(data.size());
for (T current : data) {
if (!result.contains(current)) {
result.add(current);
}
}
return result;
}
两者的区别在于HashSet 的 contains() 方法底部依赖的 HashMap 的 containsKey() 方法,时间复杂度接近于 O(1),而ArrayList 的 contains() 方法是通过遍历所有元素的方法来做的,时间复杂度接近是 O(n)
集合转数组
使用集合转数组的方法,必须使用集合的 toArray(T[] array),传入的是类型完全一致、长度为 0 的空数组。
例如下面代码,传入new String[0]表示类型
下面的Arrays.asList方法,对list进行反转,同样的s数组也会反转
1
2
3
4
5
6
7
8
String [] s= new String[]{
"dog", "lazy", "a", "over", "jumps", "fox", "brown", "quick", "A"
};
List<String> list = Arrays.asList(s);
Collections.reverse(list);
//没有指定类型的话会报错
s=list.toArray(new String[0]);
最后一行虽然传入了一个长度为 0 的数组,但 Java 会根据列表的大小创建一个新的、合适大小的数组。
数组转集合
使用工具类 Arrays.asList() 把数组转换成集合时,不能使用其修改集合相关的方法, 它的 add/remove/clear 方法会抛出 UnsupportedOperationException 异常
这里使用asList将数组转化为集合,只是传入了一个元素,list里面只有一个元素
1
2
3
4
5
6
7
int[] myArray = {1, 2, 3};
List myList = Arrays.asList(myArray);
System.out.println(myList.size());//1
System.out.println(myList.get(0));//数组地址值
System.out.println(myList.get(1));//报错:ArrayIndexOutOfBoundsException
int[] array = (int[]) myList.get(0);
System.out.println(array[0]);//1
同时,使用集合的方法也会报错
1
2
3
4
List myList = Arrays.asList(1, 2, 3);
myList.add(4);//运行时报错:UnsupportedOperationException
myList.remove(1);//运行时报错:UnsupportedOperationException
myList.clear();//运行时报错:UnsupportedOperationException
所以要将数组转化为ArrayList可以用以下方法
1
List list = new ArrayList<>(Arrays.asList("a", "b", "c"))
1
2
3
4
5
6
Integer [] myArray = { 1, 2, 3 };
List myList = Arrays.stream(myArray).collect(Collectors.toList());
//基本类型也可以实现转换(依赖boxed的装箱操作)
int [] myArray2 = { 1, 2, 3 };
List myList = Arrays.stream(myArray2).boxed().collect(Collectors.toList());
1
2
Integer[] array = {1, 2, 3};
List<Integer> list = List.of(array);
集合源码分析
ArrayList源码分析
数组队列,相当于动态数组,其容量能动态增长
在添加大量元素前,应用程序可以使用ensureCapacity操作来增加 ArrayList 实例的容量
1
2
3
4
5
6
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable{
}
从这个继承关系可以看出
List: 表明它是一个列表,支持添加、删除、查找等操作,并且可以通过下标进行访问。RandomAccess:这是一个标志接口,表明实现这个接口的List集合是支持 快速随机访问 的。在ArrayList中,我们即可以通过元素的序号快速获取元素对象,这就是快速随机访问。Cloneable:表明它具有拷贝能力,可以进行深拷贝或浅拷贝操作。Serializable: 表明它可以进行序列化操作,也就是可以将对象转换为字节流进行持久化存储或网络传输,非常方便。
ArrayList和vector的区别在于:
- ArrayList是List的主要实现类,vector是以前的实现类
- ArrayList线程不安全,vector线程安全
ArrayList扩容机制
- 初始容量: 当创建
ArrayList时,你可以指定一个初始容量。如果没有指定,ArrayList将使用默认容量大小(在 Java 8 中,默认为 10)。 - 添加元素: 当向
ArrayList添加元素且内部数组无法容纳更多元素时,ArrayList需要扩容。 - 新容量计算: 新容量的计算公式取决于
ArrayList的版本。在大多数实现中,新容量是旧容量的 1.5 倍。例如,如果当前容量为 10,扩容后将变为 15。这个增长率是一个折中的选择,旨在平衡内存使用和性能。 - 创建新数组并复制元素:
ArrayList会创建一个新的、更大的数组。然后,它将旧数组中的所有元素复制到新数组中。 - 废弃旧数组: 一旦旧数组中的元素被复制到新数组中,旧数组就会被废弃,以便垃圾收集器回收。
LinkedList源码分析
并发
线程和进程概念
进程是程序的一次执行过程,是系统运行程序的基本单位,因此进程是动态的。系统运行一个程序即是一个进程从创建,运行到消亡的过程
在 Java 中,当我们启动 main 函数时其实就是启动了一个 JVM 的进程,而 main 函数所在的线程就是这个进程中的一个线程,也称主线程
线程是一个比进程更小的执行单位。一个进程在其执行的过程中可以产生多个线程。与进程不同的是同类的多个线程共享进程的堆和方法区资源,但每个线程有自己的程序计数器、虚拟机栈和本地方法栈,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。
一个 Java 程序的运行是 main 线程和多个其他线程同时运行
线程和进程的关系、区别及优缺点
一个进程中可以有多个线程,多个线程共享进程的堆和方法区 (JDK1.8 之后的元空间)资源,但是每个线程有自己的程序计数器、虚拟机栈 和 本地方法栈
线程是进程划分成的更小的运行单位。线程和进程最大的不同在于基本上各进程是独立的,而各线程则不一定,因为同一进程中的线程极有可能会相互影响。线程执行开销小,但不利于资源的管理和保护;而进程正相反。
程序计数器为什么是私有的
程序计数器的作用:
- 字节码解释器通过程序计数器来依次读取指令,从而实现代码的流程控制,如顺序执行,选择等
- 在多线程的情况下,通过程序计数器来记录当前线程执行的位置,从而当线程被切换回来的时候能够知道该线程上次运行到哪了
如果执行的是 native 方法,那么程序计数器记录的是 undefined 地址,只有执行的是 Java 代码时程序计数器记录的才是下一条指令的地址
native 关键字在 Java 中用于标识一个方法,表明该方法是用非 Java 语言(如 C 或 C++)编写的,并且在运行时由本地方法接口(JNI, Java Native Interface)调用。这些方法通常用于执行不能直接用 Java 实现的操作,如与操作系统交互、调用系统级别的库函数等。
程序计数器私有主要是为了线程切换后能恢复到正确的执行位置
虚拟机栈和本地方法栈为什么是私有的
虚拟机栈:每个java方法在执行前会创建一个栈帧用于存储局部变量表、操作数栈、常量池引用等信息。从方法调用直至执行完成的过程,就对应着一个栈帧在 Java 虚拟机栈中入栈和出栈的过程。
本地方法栈:和虚拟机栈的作用类似,从名字可以看出本地方法栈是为虚拟机使用到的Native方法服务
所以为了保证线程中的局部变量不被其他线程访问到,将其设置为私有的
堆和方法区
堆和方法区是所有线程共享的资源,其中堆是进程中最大的一块内存,主要用于存放新创建的对象(几乎所有对象都在这里分配内存),方法区主要用于存放已被加载的类信息,常量,静态变量,编译后的代码等数据。
Java 线程和操作系统的线程有啥区别
JDK1.2之前:Java线程是基于绿色线程实现的,这是一种用户级线程(用户线程),和原生线程比起来在使用时有一些限制(比如绿色线程不能直接使用操作系统提供的功能如异步 I/O、只能在一个内核线程上运行,无法利用多核)
JDK1.2之后:Java 线程改为基于原生线程实现,现在的 Java 线程的本质其实就是操作系统的线程
用户线程与内核线程
- 用户线程:由用户空间程序管理和调度的线程,运行在用户空间(专门给应用程序使用)
- 内核线程:由操作系统内核管理和调度的线程,运行在内核空间(只有内核程序可以访问)
即用户线程创建和切换成本低,但不可以利用多核。内核态线程,创建和切换成本高,可以利用多核
线程模型是用户线程和内核线程之间的关联方式,共有下面三种方式:
- 一对一(一个用户线程对应一个内核线程)
- 多对一(多个用户线程映射到一个内核线程)
- 多对多(多个用户线程映射到多个内核线程)
Java 线程采用的是一对一的线程模型,也就是一个 Java 线程对应一个系统内核线程。
并发和并行
并发:两个及以上的作业在同一时间段内工作
并行:两个及以上的作用在同一时刻工作
同步和异步
同步:发布一个调用之后,在没有得到结果之前,该调用就不可以返回,需要一直等待
异步:调用发布之后,不用等待结果,直接返回
为什么使用多线程
从总体而言:
- 线程的轻量级:从计算机底层而言线程可以比作轻量级的进程,是程序执行的最小单位,线程间的切换和调度的成本远远小于进程。另外多核CPU时代意味着多个线程可以同时运行,这减少了线程上下文切换的花销
- 多线程并发编程正是开发高并发系统的基础,利用多线程机制可以大大提高整体的并发能力和性能
从计算机底层而言:
-
单核时代:在单核时代利用多线程主要是为了提高单线程利用CPU和IO的效率,比如说当一个线程在进行io操作时阻塞的时候,就可以使用其他的线程,从而提高CPU的利用率
-
多核时代:在多核时代利用多线程主要是为了提高多线程利用多核CPU的能力,
从资源分配和调度的角度,进程是操作系统的基本单位,从执行和任务处理的角度,线程是 CPU 调度和执行的基本单位
多线程可能带来的问题:内存泄漏、死锁、线程不安全
线程安全和不安全
线程安全和不安全是在多线程环境下对于同一份数据的访问是否能够保证其正确性和一致性的描述
- 线程安全:对于同一份数据,不管有多少线程同时访问,都能保证数据的一致性和准确性
- 线程不安全:对于同一份数据,多个线程同时访问,可能会导致数据混乱、错误丢失等
单核CPU运行多线程效率一定高吗
取决于线程的类型和任务的性质,一般来说,有两种类型的线程:CPU 密集型和 IO 密集型。
CPU 密集型的线程主要进行计算和逻辑处理,需要占用大量的 CPU 资源。
IO 密集型的线程主要进行输入输出操作,如读写文件、网络通信等,需要等待 IO 设备的响应,而不占用太多的 CPU 资源。
所以如果是CPU 密集型的线程在单核上运行的话,多个线程不断切换,增加了系统的开销,降低了效率。如果线程是 IO 密集型的,那么多个线程同时运行可以利用 CPU 在等待 IO 时的空闲时间,提高了效率
线程的生命周期和状态
-
NEW:初始状态,线程被创建出来但是还没有被调用
-
RUNNABLE:运行状态,线程被调用start()等待运行状态
-
BLOCKED:阻塞状态,需要等待锁的释放
当线程进入
synchronized方法/块或者调用wait后(被notify)重新进入synchronized方法/块,但是锁被其它线程占有,这个时候线程就会进入 BLOCKED(阻塞) 状态 -
WAITING:等待状态,表示该进程需要等待其他进程做一些特定的动作
进入等待状态的线程需要依靠其他线程的通知才能够返回到运行状态。
-
TIME_WAITING:超时等待状态,可以在指定的时间后自行返回而不是像 WAITING 那样一直等待
比如通过
sleep(long millis)方法或wait(long millis)方法可以将线程置于 TIMED_WAITING 状态。当超时时间结束后,线程将会返回到 RUNNABLE 状态。 -
TERMINATED:终止状态,表示该线程已经运行完毕
run()方法之后将会进入到该状态
线程在生命周期中并不是固定处于某一个状态而是随着代码的执行在不同状态之间切换
线程创建之后它将处于 NEW(新建) 状态,调用 start() 方法后开始运行,线程这时候处于 READY(可运行) 状态。可运行状态的线程获得了 CPU 时间片(timeslice)后就处于 RUNNING(运行) 状态。
在操作系统层面,线程有 READY 和 RUNNING 状态,但在 JVM 层面,只能看到 RUNNABLE 状态,所以 Java 系统一般将这两个状态统称为 RUNNABLE(运行中) 状态
在JVM中没有区分READY和RUNNING状态的原因是:现在的时分多任务操作系统架构采用的是抢占式轮转调度,这种方式时间分片通常很小,每个线程一次只在CPU上执行很短的时间,就被换下去继续去排队了,所以区分两个状态没太大意义
什么是线程上下文切换
线程在执行过程中会有自己的运行条件和状态,遇到下面情况会从运行状态退出
- 主动让出 CPU,比如调用了
sleep(),wait()等 - 时间片用完,因为操作系统要防止一个线程或者进程长时间占用 CPU 导致其他线程或者进程饿死
- 调用了阻塞类型的系统中断,比如请求 IO,线程被阻塞
- 被终止或结束运行
这其中前三种都会发生线程切换,线程切换意味着需要保存当前线程的上下文,留待线程下次占用 CPU 的时候恢复现场。并加载下一个将要占用 CPU 的线程上下文
线程死锁
多个线程同时被阻塞,它们中的一个或者全部都在等待其中某个资源被释放。由于线程被无限期地阻塞,因此程序不可能正常终止。
下面是一个死锁的代码:
线程 A 通过 synchronized (resource1) 获得 resource1 的监视器锁,然后通过Thread.sleep(1000)让线程 A 休眠 1s 为的是让线程 B 得到执行然后获取到 resource2 的监视器锁。线程 A 和线程 B 休眠结束了都开始企图请求获取对方的资源,然后这两个线程就会陷入互相等待的状态,这也就产生了死锁。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
public class DeadLockDemo {
private static Object resource1 = new Object();//资源 1
private static Object resource2 = new Object();//资源 2
public static void main(String[] args) {
new Thread(() -> {
synchronized (resource1) {
System.out.println(Thread.currentThread() + "get resource1");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread() + "waiting get resource2");
synchronized (resource2) {
System.out.println(Thread.currentThread() + "get resource2");
}
}
}, "线程 1").start();
new Thread(() -> {
synchronized (resource2) {
System.out.println(Thread.currentThread() + "get resource2");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread() + "waiting get resource1");
synchronized (resource1) {
System.out.println(Thread.currentThread() + "get resource1");
}
}
}, "线程 2").start();
}
}
产生死锁的四个必要条件:
- 互斥条件:该资源任意一个时刻只由一个线程占用。
- 请求与保持条件:一个线程因请求资源而阻塞时,对已获得的资源保持不放。
- 不剥夺条件:线程已获得的资源在未使用完之前不能被其他线程强行剥夺,只有自己使用完毕后才释放资源。
- 循环等待条件:若干线程之间形成一种头尾相接的循环等待资源关系
因此预防死锁就是破坏上面的必要条件
- 破坏请求与保持条件:一次性申请所有的资源。
- 破坏不剥夺条件:占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占有的资源。
- 破坏循环等待条件:靠按序申请资源来预防。按某一顺序申请资源,释放资源则反序释放。破坏循环等待条件。
避免死锁
借助于算法(比如银行家算法)对资源分配进行计算评估,使其进入安全状态
安全状态 指的是系统能够按照某种线程推进顺序(P1、P2、P3……Pn)来为每个线程分配所需资源,直到满足每个线程对资源的最大需求,使每个线程都可顺利完成。称 <P1、P2、P3.....Pn> 序列为安全序列。
sleep方法和wait方法
共同点:两者都可以暂停线程的执行
不同点:
-
sleep()方法没有释放锁,而wait()方法释放了锁即sleep的时候,其他线程仍无法调用该线程锁的对象
-
wait()通常被用于线程间交互/通信,sleep()通常被用于暂停执行因为wait释放了锁
-
wait()方法被调用后,线程不会自动苏醒,需要别的线程调用同一个对象上的notify()或者notifyAll()方法。sleep()方法执行完成后,线程会自动苏醒,或者也可以使用wait(long timeout)超时后线程会自动苏醒。wait操作后被唤醒状态进入就绪状态后,仍然需要等待获取对象的锁才能继续执行
-
sleep()是Thread类的静态本地方法,wait()则是Object类的本地方法
为什么 wait() 方法不定义在 Thread 中
wait() 是让获得对象锁的线程实现等待,会自动释放当前线程占有的对象锁。
每个对象(Object)都拥有对象锁,既然要释放当前线程占有的对象锁并让其进入 WAITING 状态,自然是要操作对应的对象(Object)而非当前的线程(Thread)。
因此同样的为什么 sleep() 方法定义在 Thread 中是因为:sleep() 是让当前线程暂停执行,不涉及到对象类,也不需要获得对象锁
可以直接调用 Thread 类的 run 方法吗
直接run意味着没有start方法,start方法会启动一个线程并让其进入就绪状态,如果没有这个步骤直接run的话,就只能当成一个 main 线程下的普通方法去执行,并不会在某个线程中执行它,所以这并不是多线程工作
volatile 关键字
volatile 关键字可以保证变量的可见性,如果我们将变量声明为 volatile ,这就指示 JVM,这个变量是共享且不稳定的,每次使用它都到主存中进行读取
即声明该变量在主存中,在 C 语言里也有,它最原始的意义就是禁用 CPU 缓存
volatile关键字可以用于确保被修饰的变量对所有线程的可见性,即当一个线程修改了该变量的值后,其他线程能够立即看到最新的值。但volatile不能保证多个线程同时对该变量进行读取和写入的操作是原子性的,所以当多个线程同时操作的时候,那么就有可能出现数据不一致的情况

synchronized关键字既可以保证数据的可见性,也可以保证数据的原子性。当某个线程进入synchronized代码块时,它会锁定该对象或类,并且在执行完代码块后会释放锁,这样其他线程才能获取锁并执行相应的代码。在synchronized代码块中对共享变量的读取和写入操作都是原子的,即一个线程正在执行synchronized代码块时,其他线程无法同时访问该代码块中的共享变量,从而保证了数据的一致性和原子性。
并且volatile 关键字除了可以保证变量的可见性,还有一个重要的作用就是防止 JVM 的指令重排序。将变量声明为 volatile ,在对这个变量进行读写操作的时候,会通过插入特定的 内存屏障 的方式来禁止指令重排序
双重校验锁实现对象单例
当第一次调用getInstance()方法时,由于instance为null,两个线程可能同时进入第一个if语句块。在synchronized关键字的作用下,只有一个线程能够进入同步块,另一个线程会被阻塞。
在进入同步块后,再次检查instance是否为null。这是因为当两个线程都通过了第一次检查时,如果没有第二次检查,就会创建两个实例。所以,在第二次检查前,只有一个线程能够创建实例。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public class Singleton {
private volatile static Singleton instance;
private Singleton() {
// 私有化构造函数防止外部实例化
}
public static Singleton getInstance() {
if (instance == null) { // 第一次检查
synchronized (Singleton.class) {
if (instance == null) { // 第二次检查
instance = new Singleton();
}
}
}
return instance;
}
}
乐观锁和悲观锁
悲观锁:每次假设最坏的情况,认为资源每次被访问的时候都会出现问题,所以每次获取资源的时候都会上锁,共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程
synchronized和ReentrantLock等独占锁就是悲观锁思想的实现
高并发的场景下,激烈的锁竞争会造成线程阻塞,大量阻塞线程会导致系统的上下文切换,增加系统的性能开销。并且,悲观锁还可能会存在死锁问题,影响代码的正常运行
乐观锁:总是假设最好的情况,认为共享资源每次被访问的时候不会出现问题,线程可以不停地执行,无需加锁也无需等待,只是在提交修改的时候去验证对应的资源是否被其它线程修改了
乐观锁的一种实现方式 CAS 实现
高并发的场景下,乐观锁相比悲观锁来说,不存在锁竞争造成线程阻塞,也不会有死锁的问题,在性能上往往会更胜一筹
理论上来说:
- 悲观锁通常多用于写比较多的情况(多写场景,竞争激烈),这样可以避免频繁失败和重试影响性能,悲观锁的开销是固定的。不过,如果乐观锁解决了频繁失败和重试这个问题的话(比如
LongAdder),也是可以考虑使用乐观锁的,要视实际情况而定。 - 乐观锁通常多用于写比较少的情况(多读场景,竞争较少),这样可以避免频繁加锁影响性能。不过,乐观锁主要针对的对象是单个共享变量(参考
java.util.concurrent.atomic包下面的原子变量类)
实现乐观锁
乐观锁一般会使用版本号机制或 CAS 算法实现
版本号机制
在数据表中加上一个数据版本号 version 字段,表示数据被修改的次数。当数据被修改时,version 值会加一。当线程 A 要更新数据值时,在读取数据的同时也会读取 version 值,在提交更新时,若刚才读取到的 version 值为当前数据库中的 version 值相等时才更新,否则重试更新操作,直到更新成功。
CAS 算法
全称是 Compare And Swap(比较与交换),用一个预期值和要更新的变量值进行比较,两值相等才会进行更新
CAS 涉及到三个操作数:
- V:要更新的变量值(Var)
- E:预期值(Expected)
- N:拟写入的新值(New)
当且仅当 V 的值等于 E 时,CAS 通过原子方式用新值 N 来更新 V 的值。如果不等,说明已经有其它线程更新了 V,则当前线程放弃更新
Java 语言并没有直接实现 CAS,CAS 相关的实现是通过 C++ 内联汇编的形式实现的
乐观锁存在的问题
-
ABA问题
如果一个变量 V 初次读取的时候是 A 值,并且在准备赋值的时候检查到它仍然是 A 值,但可能在这段时间它的值可能被改为其他值,然后又改回 A
ABA 问题的解决思路是在变量前面追加上版本号或者时间戳
-
循环时间长开销大
CAS 经常会用到自旋操作来进行重试,也就是不成功就一直循环执行直到成功。如果长时间不成功,会给 CPU 带来非常大的执行开销
-
只能保证一个共享变量的原子操作
CAS 只对单个共享变量有效,当操作涉及跨多个共享变量时 CAS 无效
synchronized 关键字
synchronized 是 Java 中的一个关键字,主要解决的是多个线程之间访问资源的同步性,可以保证被它修饰的方法或者代码块在任意时刻只能有一个线程执行
在Java早期,synchronized属于重量级锁,效率低下。这是因为监视器锁(monitor)依赖于底层的操作系统的 Mutex Lock 来实现的,Java 的线程是映射到操作系统的原生线程之上的。如果要挂起或者唤醒一个线程,都需要操作系统帮忙完成,而操作系统实现线程之间的切换时需要从用户态转换到内核态,这个状态之间的转换需要相对比较长的时间,时间成本相对较高
在Java6之后,synchronized 引入了大量的优化如自旋锁、适应性自旋锁、锁消除、锁粗化、偏向锁、轻量级锁等技术来减少锁操作的开销,这些优化让 synchronized 锁的效率提升了很多
如何使用 synchronized
synchronized主要修饰下面三种情况
- 修饰实例方法
- 修饰静态方法
- 修饰代码块
-
修饰实例方法
给当前对象实例加锁,进入同步代码前要获得 当前对象实例的锁
1
2
3
synchronized void method() {
//业务代码
}
-
修饰静态方法
给当前类加锁,会作用于类的所有对象实例 ,进入同步代码前要获得 当前 class 的锁
因为静态成员不属于任何一个实例对象,归整个类所有,不依赖于类的特定实例,被类的所有实例共享
1
2
3
synchronized static void method() {
//业务代码
}
静态 synchronized 方法和非静态 synchronized 方法之间的调用互斥么?
如果一个线程 A 调用一个实例对象的非静态 synchronized 方法,而线程 B 需要调用这个实例对象所属类的静态 synchronized 方法,是允许的,不会发生互斥现象
因为访问静态 synchronized 方法占用的锁是当前类的锁,而访问非静态 synchronized 方法占用的锁是当前实例对象锁
- 修饰代码块
synchronized(object)表示进入同步代码库前要获得 给定对象的锁。synchronized(类.class)表示进入同步代码前要获得 给定 Class 的锁
1
2
3
synchronized(this) {
//业务代码
}
总结:
synchronized关键字加到static静态方法和synchronized(class)代码块上都是是给 Class 类上锁;synchronized关键字加到实例方法上是给对象实例上锁;- 尽量不要使用
synchronized(String a)因为 JVM 中,字符串常量池具有缓存功能。
构造方法可以用 synchronized 修饰么
构造方法不能使用 synchronized 关键字修饰,因为构造方法本就线程安全,也不需要加锁
synchronized 底层原理
-
synchronized 同步语句块的情况
1 2 3 4 5 6 7
public class SynchronizedDemo { public void method() { synchronized (this) { System.out.println("synchronized 代码块"); } } }
synchronized同步语句块的实现使用的是monitorenter和monitorexit指令,其中monitorenter指令指向同步代码块的开始位置,monitorexit指令则指明同步代码块的结束位置。当执行
monitorenter指令时,线程试图获取锁也就是获取 对象监视器monitor的持有权,在执行monitorenter时,会尝试获取对象的锁,如果锁的计数器为 0 则表示锁可以被获取,获取后将锁计数器设为 1 也就是加 1对象锁的的拥有者线程才可以执行
monitorexit指令来释放锁。在执行monitorexit指令后,将锁计数器设为 0,表明锁被释放,其他线程可以尝试获取锁。 -
synchronized 修饰方法的的情况
1 2 3 4 5 6
public class SynchronizedDemo2 { public synchronized void method() { System.out.println("synchronized 方法"); } }
synchronized修饰的方法并没有monitorenter指令和monitorexit指令,取得代之的确实是ACC_SYNCHRONIZED标识,该标识指明了该方法是一个同步方法。JVM 通过该ACC_SYNCHRONIZED访问标志来辨别一个方法是否声明为同步方法,从而执行相应的同步调用如果是实例方法,JVM 会尝试获取实例对象的锁。如果是静态方法,JVM 会尝试获取当前 class 的锁
不过两者的本质都是对对象监视器 monitor 的获取
JDK1.6 之后的 synchronized 底层做的优化
JDK1.6 对锁的实现引入了大量的优化,如偏向锁、轻量级锁、自旋锁、适应性自旋锁、锁消除、锁粗化等技术来减少锁操作的开销。
- 自旋锁:在获取锁失败时,线程不会立即阻塞,而是进行一定次数的自旋尝试,期望在短时间内其他线程会释放锁。这样可以减少线程切换的开销,提高性能。
- 适应性自旋锁:根据当前线程在临界区的等待时间和其他线程的情况动态调整自旋的次数,以平衡性能和资源的利用。
- 锁消除:通过逃逸分析,JVM 可以判断某些锁是不可能被其他线程访问到的,从而可以安全地消除这些锁,减少不必要的同步操作。
- 锁粗化:当连续的对同一对象进行加锁和解锁操作时,JVM 可以将这些操作合并成一次更大范围的锁,从而减少锁操作的次数。
锁主要存在四种状态,依次是:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态,他们会随着竞争的激烈而逐渐升级。注意锁可以升级不可降级,这种策略是为了提高获得锁和释放锁的效率。
- 无锁状态(Unlocked):在无竞争的情况下,对象的锁处于无锁状态。当一个线程尝试获取对象的锁时,如果对象处于无锁状态,可以直接将对象标记为自己所持有的锁,并继续执行,无需进行额外的操作。
- 偏向锁状态(Biased Locking):偏向锁是JDK 1.6 引入的一项优化技术,旨在解决只有一个线程访问同步块的场景。当一个线程第一次进入同步块时,对象的标记被该线程所偏向,并记录下该线程的ID。之后,该线程再次进入同步块时,无需进行任何同步操作,因为对象已经偏向于该线程。
- 轻量级锁状态(Lightweight Locking):当多个线程竞争同一个锁时,偏向锁会升级为轻量级锁。轻量级锁使用CAS操作来避免使用互斥量,尝试在用户态下使用自旋锁来避免线程的切换,从而减少对操作系统的调用。
- 重量级锁状态(Heavyweight Locking):如果轻量级锁无法解决竞争问题,锁就会膨胀为重量级锁,此时涉及到操作系统的互斥量,线程会被阻塞,陷入内核态,这会引起较大的性能开销。
synchronized 和 volatile 有什么区别
volatile关键字是线程同步的轻量级实现,所以volatile性能肯定比synchronized关键字要好 。但是volatile关键字只能用于变量而synchronized关键字可以修饰方法以及代码块 。volatile关键字能保证数据的可见性,但不能保证数据的原子性。synchronized关键字两者都能保证。volatile关键字主要用于解决变量在多个线程之间的可见性,而synchronized关键字解决的是多个线程之间访问资源的同步性。
ReentrantLock
ReentrantLock 实现了 Lock 接口,是一个可重入且独占式的锁,和 synchronized 关键字类似。不过,ReentrantLock 更灵活、更强大,增加了轮询、超时、中断、公平锁和非公平锁等高级功能。
ReentrantLock 里面有一个内部类 Sync,Sync 继承 AQS(AbstractQueuedSynchronizer),添加锁和释放锁的大部分操作实际上都是在 Sync 中实现的。
Sync 有公平锁 FairSync 和非公平锁 NonfairSync 两个子类。
ReentrantLock 默认使用非公平锁,也可以通过构造器来显式的指定使用公平锁
1
2
3
4
5
// 传入一个 boolean 值,true 时为公平锁,false 时为非公平锁
public ReentrantLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
}
公平锁和非公平锁有什么区别
- 公平锁 : 锁被释放之后,先申请的线程先得到锁。性能较差一些,因为公平锁为了保证时间上的绝对顺序,上下文切换更频繁。
- 非公平锁:锁被释放之后,后申请的线程可能会先获取到锁,是随机或者按照其他优先级排序的。性能更好,但可能会导致某些线程永远无法获取到锁。
synchronized 和 ReentrantLock 有什么区别
-
两者都是可重入锁
可重入锁 也叫递归锁,指的是线程可以再次获取自己的内部锁。比如一个线程获得了某个对象的锁,此时这个对象锁还没有释放,当其再次想要获取这个对象的锁的时候还是可以获取的,如果是不可重入锁的话,就会造成死锁,因为一直在等待获取这个资源才释放
JDK 提供的所有现成的 Lock 实现类,包括 synchronized 关键字锁都是可重入的
-
synchronized 依赖于 JVM 而 ReentrantLock 依赖于 API
synchronized是依赖于 JVM 实现的,前面我们也讲到了 虚拟机团队在 JDK1.6 为synchronized关键字进行了很多优化,但是这些优化都是在虚拟机层面实现的,并没有直接暴露给我们。ReentrantLock是 JDK 层面实现的(也就是 API 层面,需要 lock() 和 unlock() 方法配合 try/finally 语句块来完成),所以我们可以通过查看它的源代码,来看它是如何实现的 -
ReentrantLock 比 synchronized 增加了一些高级功能
- 等待可中断:正在等待的线程可以选择放弃等待,改为处理其他事情
- 可实现公平锁
- 可实现选择性通知:
synchronized关键字与wait()和notify()/notifyAll()方法相结合可以实现等待/通知机制。ReentrantLock类当然也可以实现,但是需要借助于Condition接口与newCondition()方法
可中断锁和不可中断锁有什么区别
- 可中断锁:获取锁的过程中可以被中断,不需要一直等到获取锁之后 才能进行其他逻辑处理。
ReentrantLock就属于是可中断锁。 - 不可中断锁:一旦线程申请了锁,就只能等到拿到锁以后才能进行其他的逻辑处理。
synchronized就属于是不可中断锁。
ReentrantReadWriteLock
ReentrantReadWriteLock 实现了 ReadWriteLock ,是一个可重入的读写锁,既可以保证多个线程同时读的效率,同时又可以保证有写入操作时的线程安全
ReentrantReadWriteLock 其实是两把锁,一把是 WriteLock (写锁),一把是 ReadLock(读锁)
读锁是共享锁,写锁是独占锁。读锁可以被同时读,可以同时被多个线程持有,而写锁最多只能同时被一个线程持有
ReentrantReadWriteLock 也支持公平锁和非公平锁,默认使用非公平锁,可以通过构造器来显示的指定
因此:由于 ReentrantReadWriteLock 既可以保证多个线程同时读的效率,同时又可以保证有写入操作时的线程安全。因此,在读多写少的情况下,使用 ReentrantReadWriteLock 能够明显提升系统性能
线程持有读锁还能获取写锁吗
- 在线程持有读锁的情况下,该线程不能取得写锁
- 在线程持有写锁的情况下,该线程可以继续获取读锁
StampedLock
StampedLock 是 JDK 1.8 引入的性能更好的读写锁,不可重入且不支持条件变量 Conditon
StampedLock 并不是直接实现 Lock或 ReadWriteLock接口,而是基于 CLH 锁 独立实现的(AQS 也是基于这玩意)
- 写锁:独占锁,一把锁只能被一个线程获得。当一个线程获取写锁后,其他请求读锁和写锁的线程必须等待。类似于
ReentrantReadWriteLock的写锁,不过这里的写锁是不可重入的。 - 读锁 (悲观读):共享锁,没有线程获取写锁的情况下,多个线程可以同时持有读锁。如果己经有线程持有写锁,则其他线程请求获取该读锁会被阻塞。类似于
ReentrantReadWriteLock的读锁,不过这里的读锁是不可重入的 - 乐观读:允许多个线程获取乐观读以及读锁。同时允许一个写线程获取写锁。
性能更好的原因:StampedLock 的乐观读允许一个写线程获取写锁,所以不会导致所有写线程阻塞,也就是当读多写少的时候,写线程有机会获取写锁,减少了线程饥饿的问题,吞吐量大大提高。
ThreadLocal
我们创建的变量是可以被任何一个线程访问并修改的。如果想实现每一个线程都有自己的专属本地变量该如何解决呢?
JDK 中自带的ThreadLocal类正是为了解决这样的问题,ThreadLocal类主要解决的就是让每个线程绑定自己的值,可以将ThreadLocal类形象的比喻成存放数据的盒子,盒子中可以存储每个线程的私有数据
如果你创建了一个ThreadLocal变量,那么访问这个变量的每个线程都会有这个变量的本地副本,这也是ThreadLocal变量名的由来。他们可以使用 get() 和 set() 方法来获取默认值或将其值更改为当前线程所存的副本的值,从而避免了线程安全问题
样例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
import java.text.SimpleDateFormat;
import java.util.Random;
public class ThreadLocalExample implements Runnable{
// SimpleDateFormat 不是线程安全的,所以每个线程都要有自己独立的副本
private static final ThreadLocal<SimpleDateFormat> formatter = ThreadLocal.withInitial(() -> new SimpleDateFormat("yyyyMMdd HHmm"));
public static void main(String[] args) throws InterruptedException {
ThreadLocalExample obj = new ThreadLocalExample();
for(int i=0 ; i<10; i++){
Thread t = new Thread(obj, ""+i);
Thread.sleep(new Random().nextInt(1000));
t.start();
}
}
@Override
public void run() {
System.out.println("Thread Name= "+Thread.currentThread().getName()+" default Formatter = "+formatter.get().toPattern());
try {
Thread.sleep(new Random().nextInt(1000));
} catch (InterruptedException e) {
e.printStackTrace();
}
//formatter pattern is changed here by thread, but it won't reflect to other threads
formatter.set(new SimpleDateFormat());
System.out.println("Thread Name= "+Thread.currentThread().getName()+" formatter = "+formatter.get().toPattern());
}
}
这段代码展示了如何在多线程环境下使用 ThreadLocal 来实现线程安全的 SimpleDateFormat 对象
- 在
ThreadLocalExample类中,我们定义了一个静态变量formatter,它的类型是ThreadLocal<SimpleDateFormat>。这意味着每个线程都可以拥有自己独立的SimpleDateFormat对象,而不需要担心线程安全性。 - 在
main方法中,我们创建了一个ThreadLocalExample对象,并启动了 10 个线程。每个线程都会输出当前线程的名称以及默认的SimpleDateFormat格式。 - 在
run方法中,每个线程首先输出当前线程名称和默认的日期格式。然后线程会随机休眠一段时间,模拟不同线程的执行速度不同。 - 接着,每个线程会尝试修改
SimpleDateFormat对象的格式。虽然每个线程都调用了formatter.set(new SimpleDateFormat())来更改日期格式,但由于使用了ThreadLocal,所以这个更改只会作用于当前线程的SimpleDateFormat对象,不会影响其他线程的对象。
通过这段代码,我们可以清楚地看到 ThreadLocal 的作用:它能够为每个线程提供独立的、线程安全的对象副本,从而避免了多线程环境下的竞争和同步问题。这在需要使用非线程安全对象的情况下非常有用,比如 SimpleDateFormat
ThreadLocal 原理
1
2
3
4
5
6
7
8
9
public class Thread implements Runnable {
//......
//与此线程有关的ThreadLocal值。由ThreadLocal类维护
ThreadLocal.ThreadLocalMap threadLocals = null;
//与此线程有关的InheritableThreadLocal值。由InheritableThreadLocal类维护
ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
//......
}
从上面Thread类 源代码可以看出Thread 类中有一个 threadLocals 和 一个 inheritableThreadLocals 变量,这两个变量ThreadLocalMap类型变量,可以理解为定制的HashMap,默认情况下为null,当前线程调用 ThreadLocal 类的 set或get方法时才创建它们
ThreadLocal类的set()方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
public void set(T value) {
//获取当前请求的线程
Thread t = Thread.currentThread();
//取出 Thread 类内部的 threadLocals 变量(哈希表结构)
ThreadLocalMap map = getMap(t);
if (map != null)
// 将需要存储的值放入到这个哈希表中
map.set(this, value);
else
createMap(t, value);
}
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
最终的变量是放在了当前线程的 ThreadLocalMap 中,并不是存在 ThreadLocal 上,ThreadLocal 可以理解为只是ThreadLocalMap的封装,传递了变量值。ThrealLocal 类中可以通过Thread.currentThread()获取到当前线程对象后,直接通过getMap(Thread t)可以访问到该线程的ThreadLocalMap对象。
每个Thread中都具备一个ThreadLocalMap,而ThreadLocalMap可以存储以ThreadLocal为 key ,Object 对象为 value 的键值对。
即每个线程有个一个hashmap,这个hashmap存储了很多键值对,键是ThreadLocal,值是设置的值
比如我们在同一个线程中声明了两个 ThreadLocal 对象的话, Thread内部都是使用仅有的那个ThreadLocalMap 存放数据的,ThreadLocalMap的 key 就是 ThreadLocal对象,value 就是 ThreadLocal 对象调用set方法设置的值。
ThreadLocal 内存泄露问题是怎么导致的
ThreadLocalMap 中使用的 key 为 ThreadLocal 的弱引用,而 value 是强引用。所以,如果 ThreadLocal 没有被外部强引用的情况下,在垃圾回收的时候,key 会被清理掉,而 value 不会被清理掉。
这样一来,ThreadLocalMap 中就会出现 key 为 null 的 Entry。假如我们不做任何措施的话,value 永远无法被 GC 回收,这个时候就可能会产生内存泄露。ThreadLocalMap 实现中已经考虑了这种情况,在调用 set()、get()、remove() 方法的时候,会清理掉 key 为 null 的记录。使用完 ThreadLocal方法后最好手动调用remove()方法
弱引用:如果一个对象只具有弱引用,那就类似于可有可无的生活用品。
弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它 所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程, 因此不一定会很快发现那些只具有弱引用的对象。
Java的四种引用类型
强引用:我们常常 new 出来的对象就是强引用类型,只要强引用存在,垃圾回收器将永远不会回收被引用的对象,哪怕内存不足的时候
软引用:使用 SoftReference 修饰的对象被称为软引用,软引用指向的对象在内存要溢出的时候被回收
弱引用:使用 WeakReference 修饰的对象被称为弱引用,只要发生垃圾回收,若这个对象只被弱引用指向,那么就会被回收
虚引用:虚引用是最弱的引用,在 Java 中使用 PhantomReference 进行定义。虚引用中唯一的作用就是用队列接收对象即将死亡的通知
线程池
线程池就是管理一系列线程的资源池。当有任务要处理时,直接从线程池中获取线程来处理,处理完之后线程并不会立即被销毁,而是等待下一个任务
池化技术的思想主要是为了减少每次获取资源的消耗,提高对资源的利用率。
线程池使用的好处
-
降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
-
提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
-
提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
创建线程池
方式一:通过ThreadPoolExecutor构造函数来创建
方式二:通过 Executor 框架的工具类 Executors 来创建
并且可以创建多种类型的 ThreadPoolExecutor:
-
FixedThreadPool:该方法返回一个固定线程数量的线程池。该线程池中的线程数量始终不变。当有一个新的任务提交时,线程池中若有空闲线程,则立即执行。若没有,则新的任务会被暂存在一个任务队列中,待有线程空闲时,便处理在任务队列中的任务。 -
SingleThreadExecutor: 该方法返回一个只有一个线程的线程池。若多余一个任务被提交到该线程池,任务会被保存在一个任务队列中,待线程空闲,按先入先出的顺序执行队列中的任务。 -
CachedThreadPool: 该方法返回一个可根据实际情况调整线程数量的线程池。初始大小为 0。当有新任务提交时,如果当前线程池中没有线程可用,它会创建一个新的线程来处理该任务。如果在一段时间内(默认为 60 秒)没有新任务提交,核心线程会超时并被销毁,从而缩小线程池的大小。 -
ScheduledThreadPool:该方法返回一个用来在给定的延迟后运行任务或者定期执行任务的线程池。
《阿里巴巴 Java 开发手册》中强制线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 构造函数的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险
Executors 返回线程池对象的弊端如下(即使用默认方式创建线程池的坏处):
-
FixedThreadPool和SingleThreadExecutor:使用的是无界的LinkedBlockingQueue,任务队列最大长度为Integer.MAX_VALUE,可能堆积大量的请求,从而导致 OOM。 -
CachedThreadPool:使用的是同步队列SynchronousQueue, 允许创建的线程数量为Integer.MAX_VALUE,如果任务数量过多且执行速度较慢,可能会创建大量的线程,从而导致 OOM。 -
ScheduledThreadPool和SingleThreadScheduledExecutor: 使用的无界的延迟阻塞队列DelayedWorkQueue,任务队列最大长度为Integer.MAX_VALUE,可能堆积大量的请求,从而导致 OOM。
Executor 框架介绍
通过 Executor 来启动线程比使用 Thread 的 start 方法更好,除了更易管理,效率更好(用线程池实现,节约开销)外,还有关键的一点:有助于避免 this 逃逸问题
this 逃逸是指在构造函数返回之前其他线程就持有该对象的引用,调用尚未构造完全的对象的方法可能引发令人疑惑的错误。
Executor 框架不仅包括了线程池的管理,还提供了线程工厂、队列以及拒绝策略等,Executor 框架让并发编程变得更加简单
- Executor 接口
- 这是最基本的接口,定义了一个方法
execute(Runnable command),用于提交执行任务。 - 它提供了一种将任务提交和任务如何运行(如在哪个线程或线程池中)分离开来的方式。
- 这是最基本的接口,定义了一个方法
- Executors 类
- 提供了工厂方法来创建不同类型的线程池,如
newFixedThreadPool、newCachedThreadPool、newSingleThreadExecutor等。 - 这些工厂方法提供了线程池的常见配置,简化了线程池的创建过程。
- 提供了工厂方法来创建不同类型的线程池,如
- ExecutorService 接口
- 扩展了
Executor,添加了一些用于生命周期管理(如关闭线程池)和任务提交(返回Future以获取结果和状态)的方法。 - 常用方法包括
submit、invokeAll、invokeAny、shutdown和shutdownNow。
- 扩展了
- ScheduledExecutorService 接口
- 扩展了
ExecutorService,增加了对任务的定时执行和周期性执行的支持。 - 允许使用
schedule、scheduleAtFixedRate和scheduleWithFixedDelay等方法安排任务执行。
- 扩展了
- ThreadPoolExecutor 和 ScheduledThreadPoolExecutor
- 这两个类是
ExecutorService和ScheduledExecutorService的具体实现。 - 提供了丰富的配置选项,如核心线程数、最大线程数、存活时间、工作队列等,使得线程池的行为可以高度定制。
- 这两个类是
线程池常见参数有哪些
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
/**
* 用给定的初始参数创建一个新的ThreadPoolExecutor。
*/
public ThreadPoolExecutor(int corePoolSize,//线程池的核心线程数量
int maximumPoolSize,//线程池的最大线程数
long keepAliveTime,//当线程数大于核心线程数时,多余的空闲线程存活的最长时间
TimeUnit unit,//时间单位
BlockingQueue<Runnable> workQueue,//任务队列,用来储存等待执行任务的队列
ThreadFactory threadFactory,//线程工厂,用来创建线程,一般默认即可
RejectedExecutionHandler handler//拒绝策略,当提交的任务过多而不能及时处理时,我们可以定制策略来处理任务
) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
其中最重要的三个参数是:
-
corePoolSize: 任务队列未达到队列容量时,最大可以同时运行的线程数量。 -
maximumPoolSize: 任务队列中存放的任务达到队列容量的时候,当前可以同时运行的线程数量变为最大线程数。 -
workQueue: 新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,新任务就会被存放在队列中。
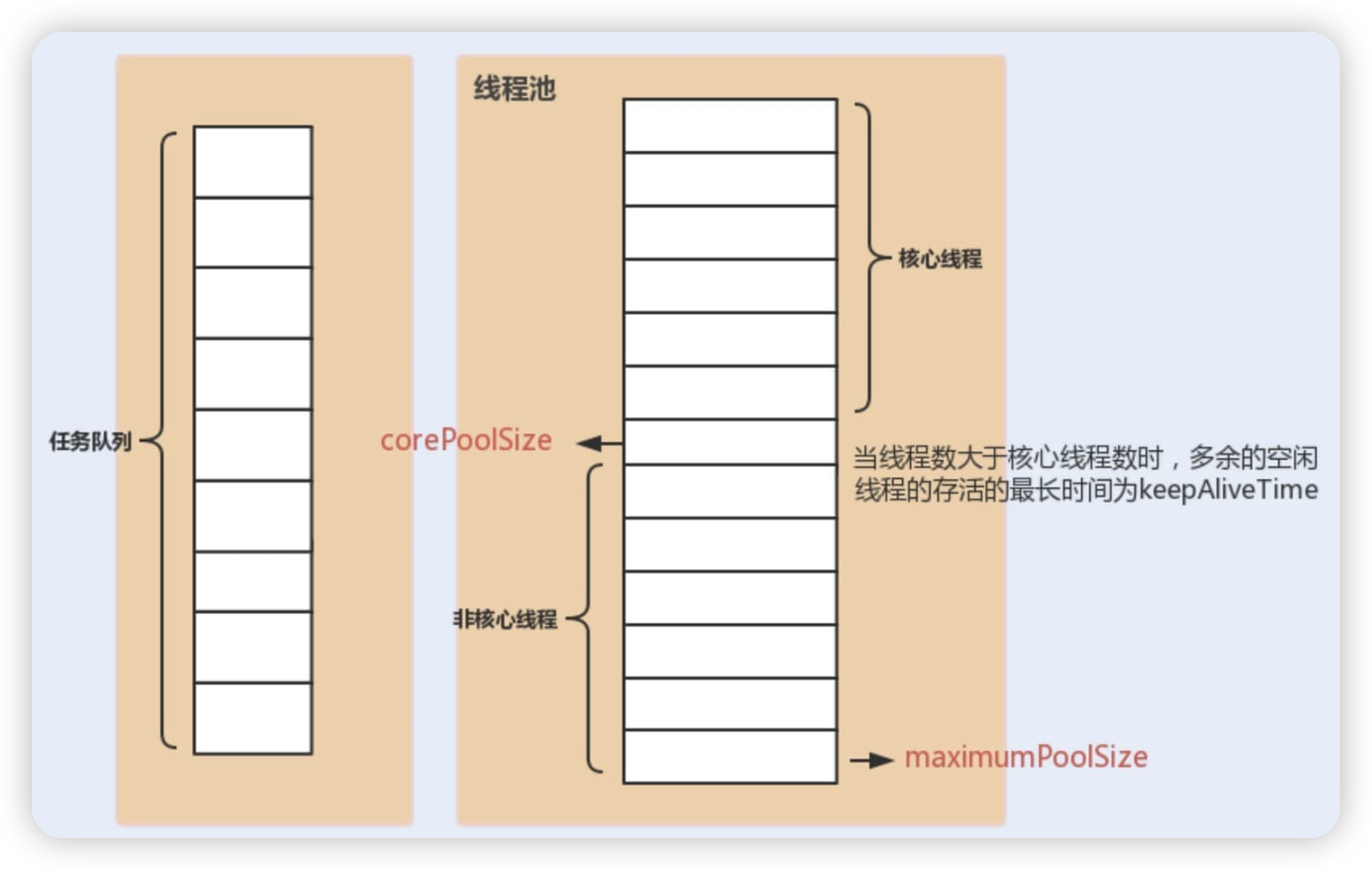
当使用线程池执行新任务时,通常会经历以下流程:
-
如果线程池当前的工作线程数小于核心线程数(通过
corePoolSize参数配置),则会创建一个新的工作线程来执行任务。这是因为核心线程会一直保持存活状态,即使没有任务需要执行。 -
如果线程池当前的工作线程数已经达到核心线程数,但任务队列(通过
BlockingQueue实现)还有空间可以接受新的任务,那么新任务会被添加到队列中等待执行。任务队列的大小可以通过workQueue参数进行配置。 -
如果线程池当前的工作线程数已经达到核心线程数,并且任务队列已经满了,但线程池的最大线程数(通过
maximumPoolSize参数配置)还未达到,那么会创建一个新的非核心线程来执行任务。 -
如果线程池的最大线程数已经达到,无法再创建新的线程,并且任务队列也已满,则根据所选择的拒绝策略(通过
RejectedExecutionHandler实现)来处理新任务的提交。常见的拒绝策略有:抛出异常、丢弃任务、丢弃队列中最旧的任务或者在调用者线程中直接执行。 -
一旦有空闲的工作线程,它将从任务队列中获取下一个任务进行执行。这是通过使用任务队列的出队操作来实现的。
-
当线程执行完任务后,如果线程池中的线程数多于核心线程数,且在指定的时间内没有新的任务到达(通过
keepAliveTime参数配置),那么这些多余的非核心线程将被终止并移出线程池,以减少资源消耗。
这个流程可以保证线程池高效地处理新任务,并根据负载情况动态地调整工作线程的数量。同时,任务队列的存在可以缓解瞬时的任务突发,避免线程过度增长或因线程频繁创建销毁而引起的性能问题。
线程池的饱和策略
如果当前同时运行的线程数量达到最大线程数量并且队列也已经被放满了任务时
即当来的任务数量>maximumPoolSize+workQueue时,就会采用饱和策略
ThreadPoolTaskExecutor 定义一些策略
-
ThreadPoolExecutor.AbortPolicy: 抛出RejectedExecutionException来拒绝新任务的处理。 -
ThreadPoolExecutor.CallerRunsPolicy: 调用执行自己的线程运行任务,也就是直接在调用execute方法的线程中运行(run)被拒绝的任务,如果执行程序已关闭,则会丢弃该任务。因此这种策略会降低对于新任务提交速度,影响程序的整体性能。如果您的应用程序可以承受此延迟并且你要求任何一个任务请求都要被执行的话,你可以选择这个策略。 -
ThreadPoolExecutor.DiscardPolicy: 不处理新任务,直接丢弃掉。 -
ThreadPoolExecutor.DiscardOldestPolicy: 此策略将丢弃最早的未处理的任务请求。
线程池常用的阻塞队列
新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,新任务就会被存放在队列中
不同的线程池会选用不同的阻塞队列
-
容量为
Integer.MAX_VALUE的LinkedBlockingQueue(无界队列):FixedThreadPool和SingleThreadExector。FixedThreadPool最多只能创建核心线程数的线程(核心线程数和最大线程数相等),SingleThreadExector只能创建一个线程(核心线程数和最大线程数都是 1),二者的任务队列永远不会被放满。 -
SynchronousQueue(同步队列):CachedThreadPool。SynchronousQueue没有容量,不存储元素,目的是保证对于提交的任务,如果有空闲线程,则使用空闲线程来处理;否则新建一个线程来处理任务。也就是说,CachedThreadPool的最大线程数是Integer.MAX_VALUE,可以理解为线程数是可以无限扩展的,可能会创建大量线程,从而导致 OOM。 -
DelayedWorkQueue(延迟阻塞队列):ScheduledThreadPool和SingleThreadScheduledExecutor。DelayedWorkQueue的内部元素并不是按照放入的时间排序,而是会按照延迟的时间长短对任务进行排序,内部采用的是“堆”的数据结构,可以保证每次出队的任务都是当前队列中执行时间最靠前的。DelayedWorkQueue添加元素满了之后会自动扩容原来容量的 1/2,即永远不会阻塞,最大扩容可达Integer.MAX_VALUE,所以最多只能创建核心线程数的线程
ThreadPoolExecutor 示例代码
首先创建一个 Runnable 接口的实现类,用于定义任务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
import java.util.Date;
/**
* 这是一个简单的Runnable类,需要大约5秒钟来执行其任务。
* @author shuang.kou
*/
public class MyRunnable implements Runnable {
private String command;
public MyRunnable(String s) {
this.command = s;
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " Start. Time = " + new Date());
processCommand();
System.out.println(Thread.currentThread().getName() + " End. Time = " + new Date());
}
private void processCommand() {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
@Override
public String toString() {
return this.command;
}
}
ThreadPoolExecutor 构造函数自定义参数的方式来创建线程池。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class ThreadPoolExecutorDemo {
private static final int CORE_POOL_SIZE = 5;
private static final int MAX_POOL_SIZE = 10;
private static final int QUEUE_CAPACITY = 100;
private static final Long KEEP_ALIVE_TIME = 1L;
public static void main(String[] args) {
//使用阿里巴巴推荐的创建线程池的方式
//通过ThreadPoolExecutor构造函数自定义参数创建
ThreadPoolExecutor executor = new ThreadPoolExecutor(
CORE_POOL_SIZE,
MAX_POOL_SIZE,
KEEP_ALIVE_TIME,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(QUEUE_CAPACITY),
new ThreadPoolExecutor.CallerRunsPolicy());
for (int i = 0; i < 10; i++) {
//创建WorkerThread对象(WorkerThread类实现了Runnable 接口)
Runnable worker = new MyRunnable("" + i);
//执行Runnable
executor.execute(worker);
}
//终止线程池
executor.shutdown();
while (!executor.isTerminated()) {
}
System.out.println("Finished all threads");
}
}
为了搞懂线程池的原理,我们需要首先分析一下 execute方法。 在示例代码中,我们使用 executor.execute(worker)来提交一个任务到线程池中去,下面是execute方法源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
// 存放线程池的运行状态 (runState) 和线程池内有效线程的数量 (workerCount)
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static int workerCountOf(int c) {
return c & CAPACITY;
}
//任务队列
private final BlockingQueue<Runnable> workQueue;
public void execute(Runnable command) {
// 如果任务为null,则抛出异常。
if (command == null)
throw new NullPointerException();
// ctl 中保存的线程池当前的一些状态信息
int c = ctl.get();
// 下面会涉及到 3 步 操作
// 1.首先判断当前线程池中执行的任务数量是否小于 corePoolSize
// 如果小于的话,通过addWorker(command, true)新建一个线程,并将任务(command)添加到该线程中;然后,启动该线程从而执行任务。
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
// 2.如果当前执行的任务数量大于等于 corePoolSize 的时候就会走到这里,表明创建新的线程失败。
// 通过 isRunning 方法判断线程池状态,线程池处于 RUNNING 状态并且队列可以加入任务,该任务才会被加入进去
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
// 再次获取线程池状态,如果线程池状态不是 RUNNING 状态就需要从任务队列中移除任务,并尝试判断线程是否全部执行完毕。同时执行拒绝策略。
if (!isRunning(recheck) && remove(command))
reject(command);
// 如果当前工作线程数量为0,新创建一个线程并执行。
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
//3. 通过addWorker(command, false)新建一个线程,并将任务(command)添加到该线程中;然后,启动该线程从而执行任务。
// 传入 false 代表增加线程时判断当前线程数是否少于 maxPoolSize
//如果addWorker(command, false)执行失败,则通过reject()执行相应的拒绝策略的内容。
else if (!addWorker(command, false))
reject(command);
}
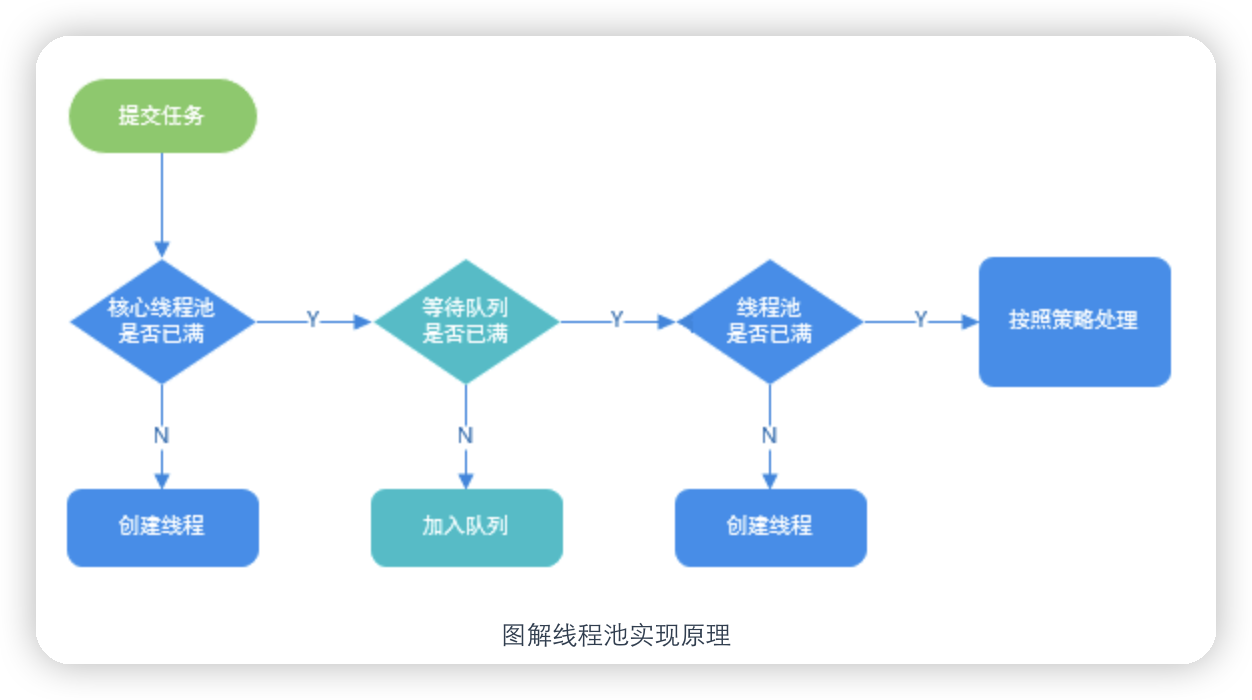
源码的大致思路是:
- 如果当前运行的线程数小于核心线程数,那么就会新建一个线程来执行任务。
- 如果当前运行的线程数等于或大于核心线程数,但是小于最大线程数,那么就把该任务放入到任务队列里等待执行。
- 如果向任务队列投放任务失败(任务队列已经满了),但是当前运行的线程数是小于最大线程数的,就新建一个线程来执行任务。
- 如果当前运行的线程数已经等同于最大线程数了,新建线程将会使当前运行的线程超出最大线程数,那么当前任务会被拒绝,饱和策略会调用
RejectedExecutionHandler.rejectedExecution()方法
runnable和callable的区别
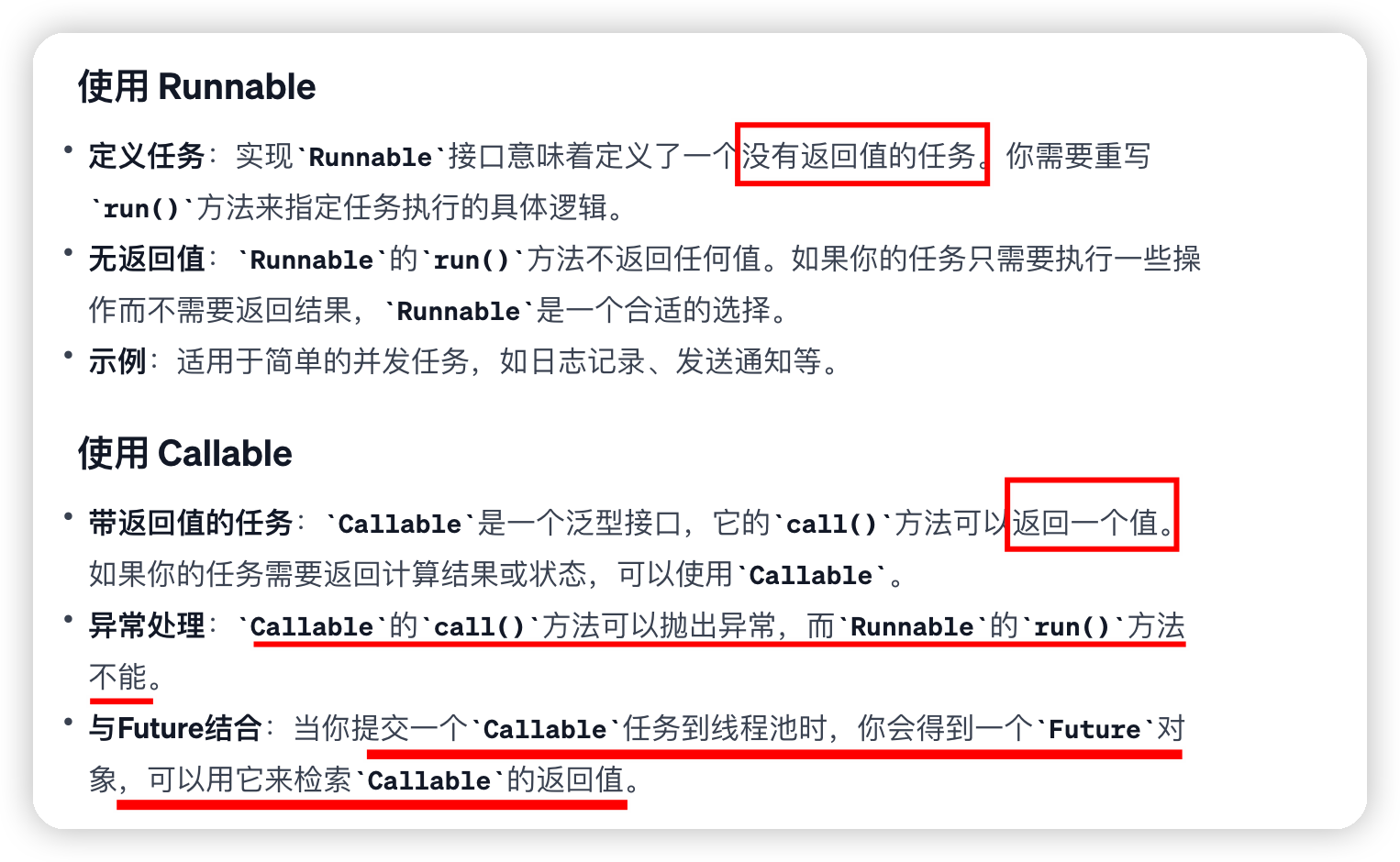
需要从任务中获取结果或者需要处理任务执行过程中抛出的异常,使用Callable会更合适
excute和submit的区别
在Java的Executor框架中,execute()和submit()是两个用于启动任务的关键方法,它们有一些重要的区别:
-
execute(Runnable command),定义于
Executor接口,参数是一个实现了Runnable接口的对象,无返回值 -
**submit(Callable
task) 或 submit(Runnable task)**,定义于`ExecutorService`接口,这是`Executor`接口的子接口,可以接受`Callable`或`Runnable`对象,返回一个`Future `对象,用于获取任务的结果和状态
shutdown()和shutdownNow()区别
shutdown():关闭线程池,线程池的状态变为SHUTDOWN。线程池不再接受新任务了,但是队列里的任务得执行完毕。shutdownNow():关闭线程池,线程池的状态变为STOP。线程池会终止当前正在运行的任务,并停止处理排队的任务并返回正在等待执行的 List。
isTerminated()和isShutdown()的区别
isShutDown当调用shutdown()方法后返回为 true。isTerminated当调用shutdown()方法后,并且所有提交的任务完成后返回为 true
线程池命名
1、利用 guava 的 ThreadFactoryBuilder
1
2
3
4
ThreadFactory threadFactory = new ThreadFactoryBuilder()
.setNameFormat(threadNamePrefix + "-%d")
.setDaemon(true).build();
ExecutorService threadPool = new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime, TimeUnit.MINUTES, workQueue, threadFactory);
2、自己实现 ThreadFactory
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
import java.util.concurrent.Executors;
import java.util.concurrent.ThreadFactory;
import java.util.concurrent.atomic.AtomicInteger;
/**
* 线程工厂,它设置线程名称,有利于我们定位问题。
*/
public final class NamingThreadFactory implements ThreadFactory {
private final AtomicInteger threadNum = new AtomicInteger();
private final ThreadFactory delegate;
private final String name;
/**
* 创建一个带名字的线程池生产工厂
*/
public NamingThreadFactory(ThreadFactory delegate, String name) {
this.delegate = delegate;
this.name = name; // TODO consider uniquifying this
}
@Override
public Thread newThread(Runnable r) {
Thread t = delegate.newThread(r);
t.setName(name + " [#" + threadNum.incrementAndGet() + "]");
return t;
}
}
如何设定线程池的大小
线程池设置的过大,增加了上下文切换的成本,过小又容易导致大量任务堵塞,所以需要合适的大小
-
有一个简单并且适用面比较广的公式:
CPU 密集型任务(N+1): 这种任务消耗的主要是 CPU 资源,可以将线程数设置为 N(CPU 核心数)+1。比 CPU 核心数多出来的一个线程是为了防止线程偶发的缺页中断,或者其它原因导致的任务暂停而带来的影响。一旦任务暂停,CPU 就会处于空闲状态,而在这种情况下多出来的一个线程就可以充分利用 CPU 的空闲时间。
I/O 密集型任务(2N): 这种任务应用起来,系统会用大部分的时间来处理 I/O 交互,而线程在处理 I/O 的时间段内不会占用 CPU 来处理,这时就可以将 CPU 交出给其它线程使用。因此在 I/O 密集型任务的应用中,我们可以多配置一些线程,具体的计算方法是 2N。

如何判断是 CPU 密集任务还是 IO 密集任务
CPU 密集型简单理解就是利用 CPU 计算能力的任务比如你在内存中对大量数据进行排序。但凡涉及到网络读取,文件读取这类都是 IO 密集型,这类任务的特点是 CPU 计算耗费时间相比于等待 IO 操作完成的时间来说很少,大部分时间都花在了等待 IO 操作完成上。
-
动态修改参数值 参考
那在什么时候修改呢,美团考虑的是在运行的时候修改,具体操作如下:
在运行期,线程池使用方调用setcorePoolSize方法设置corePoolSize之后,线程池会直接覆盖原来的corePoolSize值,并且基于当前值和原始值的比较结果采取不同的处理策略。
- 对于当前值小于当前工作线程数的情况,说明有多余的worker线程,此时会向当前idle的worker线程发起中断请求以实现回收,多余的worker在下次idel的时候也会被回收
- 对于当前值大于原始值且当前队列中有待执行任务,则线程池会创建新的worker线程来执行队列任务
流程图如下:
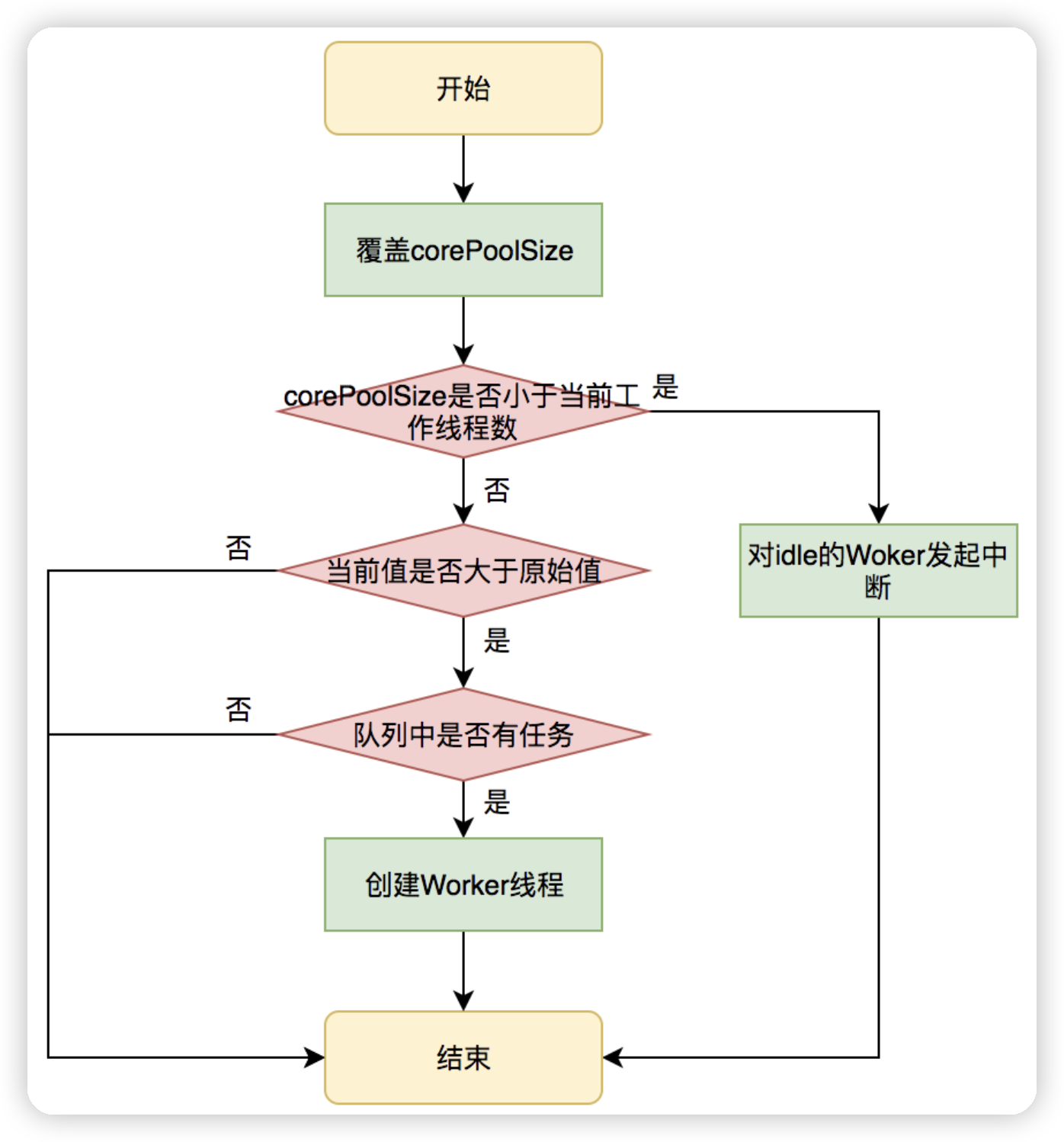
再设置maximumPoolSize,按照下面逻辑
- 首先是参数合法性校验。
- 然后用传递进来的值,覆盖原来的值。
- 判断工作线程是否是大于最大线程数,如果大于,则对空闲线程发起中断请求。

最后就是workQueue的设置,从工作队列的源码可以看出其capcity这个变量被设置为了final,所以是不能修改的,所以考虑自己创建一个工作队列,直接将LinkedBlockingQueue的源码复制一份,然后把capcity的fnal去掉即可
如何设计一个能够根据任务的优先级来执行的线程池
假如我们需要实现一个优先级任务线程池的话,那可以考虑使用 PriorityBlockingQueue (优先级阻塞队列)作为任务队列(ThreadPoolExecutor 的构造函数有一个 workQueue 参数可以传入任务队列)。
不过要想让 PriorityBlockingQueue 实现对任务的排序,传入其中的任务必须是具备排序能力的,方式有两种:
-
提交到线程池的任务实现
Comparable接口,并重写compareTo方法来指定任务之间的优先级比较规则。 -
创建
PriorityBlockingQueue时传入一个Comparator对象来指定任务之间的排序规则(推荐)。
不过也存在一些问题
-
PriorityBlockingQueue是无界的,可能堆积大量的请求,从而导致 OOM。 -
可能会导致饥饿问题,即低优先级的任务长时间得不到执行。
-
由于需要对队列中的元素进行排序操作以及保证线程安全(并发控制采用的是可重入锁
ReentrantLock),因此会降低性能。
一些相关的面试题
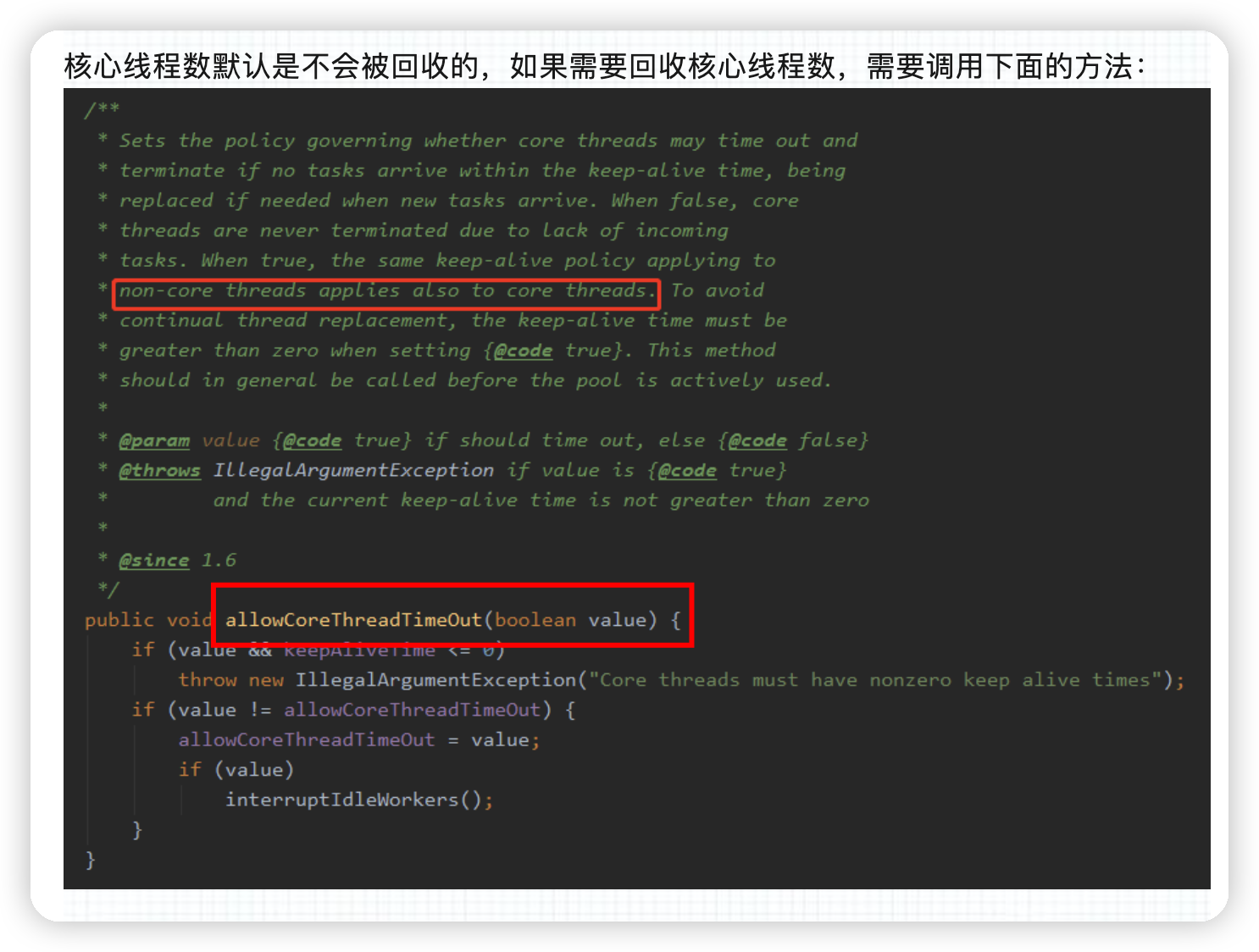
线程池被创建后里面有线程吗?如果没有的话,你知道有什么方法对线程池进行预热吗?
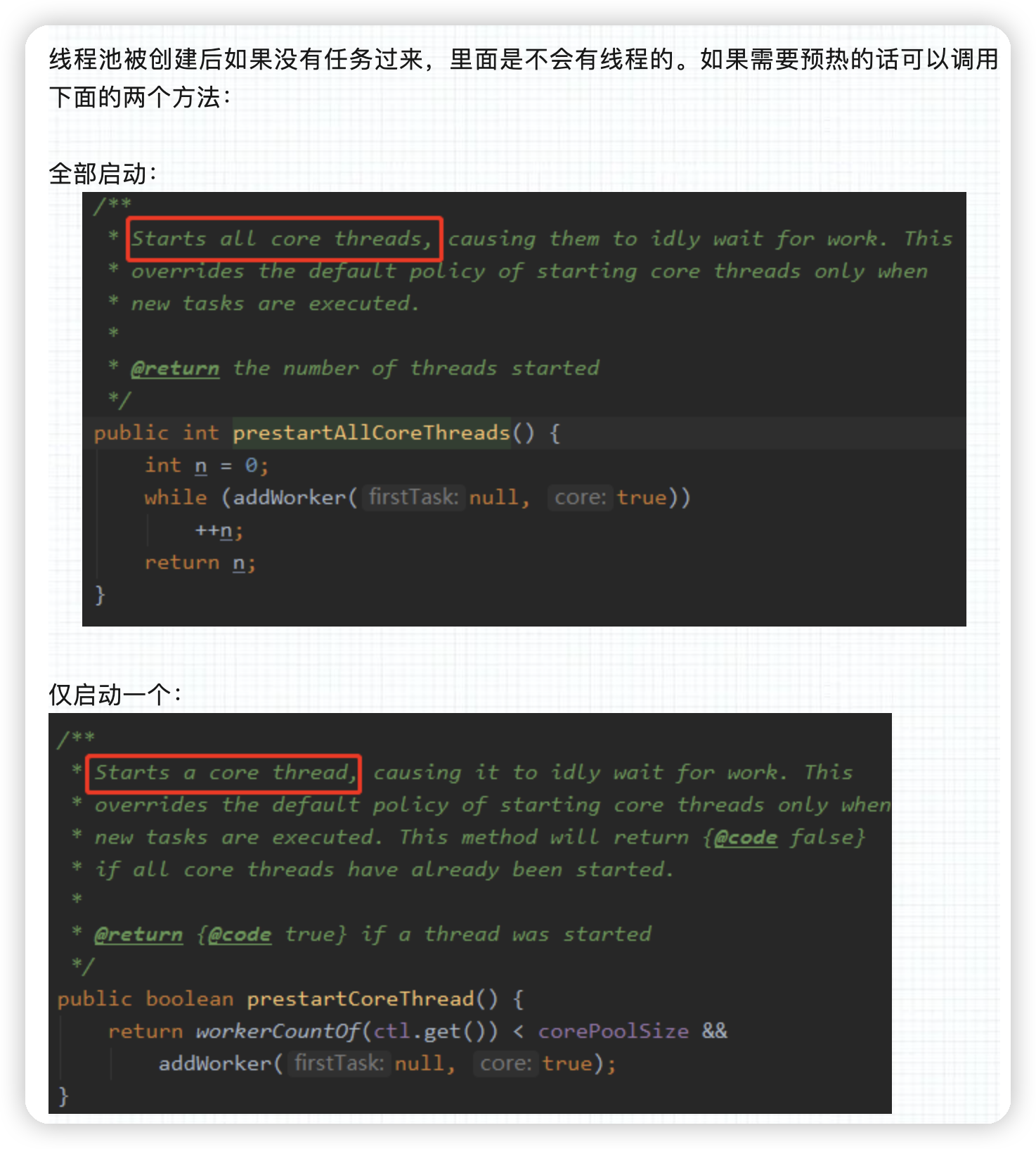
核心线程数会被回收吗?需要什么设置?
Future
是异步思想的典型运用
当我们执行某一耗时的任务时,可以将这个耗时任务交给一个子线程去异步执行,同时我们可以干点其他事情,不用傻傻等待耗时任务执行完成。等我们的事情干完后,我们再通过 Future 类获取到耗时任务的执行结果。这样一来,程序的执行效率就明显提高了
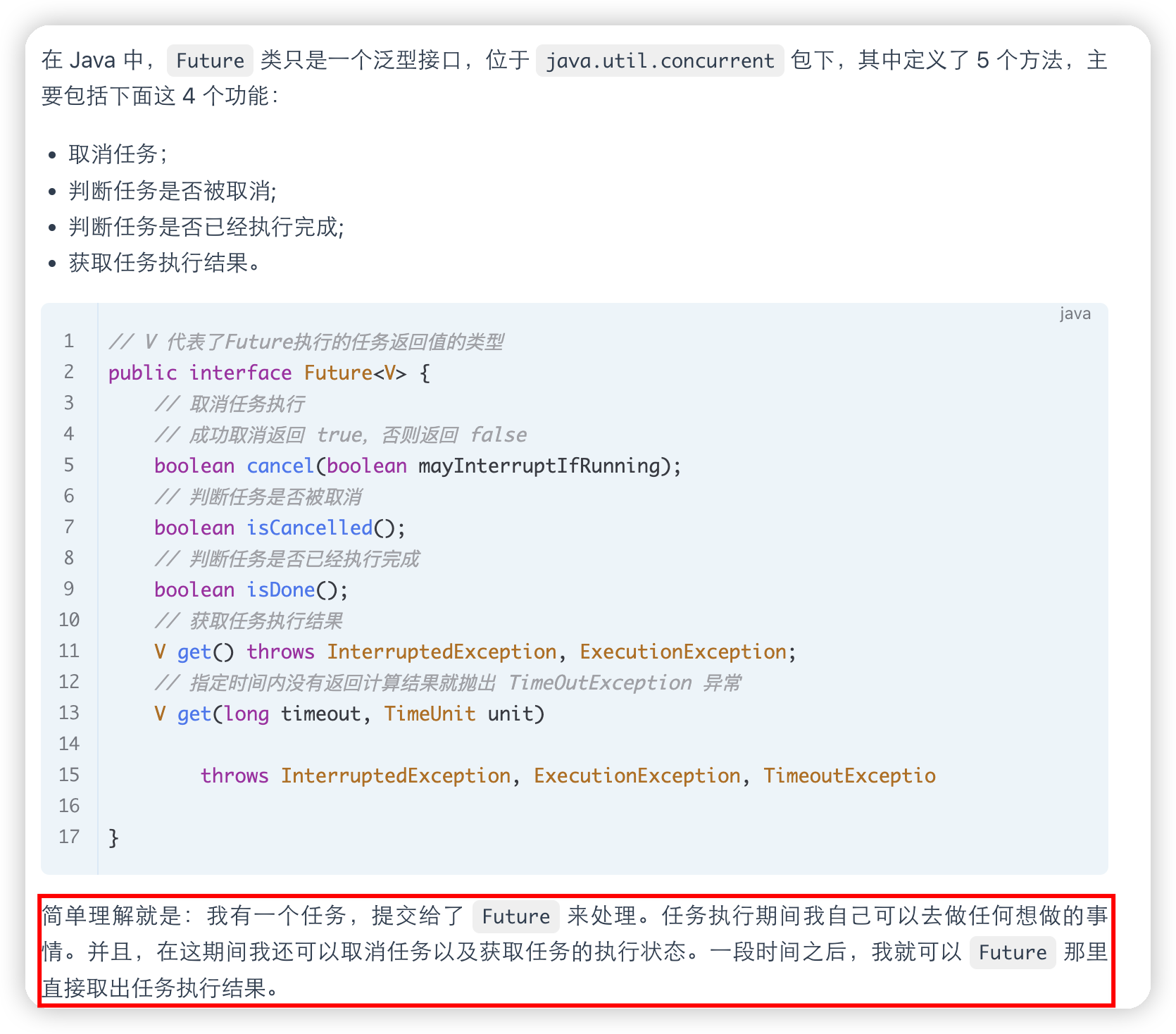
Callable 和 Future 有什么关系
Callable:
Callable是一个具有泛型参数的接口,它类似于Runnable,但是可以返回结果并抛出异常。Callable接口定义了一个名为call的方法,该方法可以在不同的线程中执行任务,并且可以返回一个结果,或者在任务执行过程中抛出异常。
Callable 和 Future 之间的关系在于,当我们使用线程池执行任务时,可以将任务封装为 Callable 对象,然后通过线程池提交执行,并且会返回一个 Future 对象来表示任务的执行情况。
CompletableFuture类
将多个任务进行编排,来执行任务,得到好的效果
Future是异步思想的经典运用,遇到耗时任务是分配一个子线程去做,最后用Future来获取结果即可, Future 在实际使用过程中存在一些局限性比如不支持异步任务的编排组合、获取计算结果的 get() 方法为阻塞调用。
1
2
public class CompletableFuture<T> implements Future<T>, CompletionStage<T> {
}
CompletionStage 接口描述了一个异步计算的阶段。很多计算可以分成多个阶段或步骤,此时可以通过它将所有步骤组合起来,形成异步计算的流水线
CompletableFuture 常见操作
常见的创建 CompletableFuture 对象的方法如下:
-
通过 new 关键字。
获取异步计算的结果也非常简单,直接调用
get()方法即可。调用get()方法的线程会阻塞直到CompletableFuture完成运算 -
基于
CompletableFuture自带的静态工厂方法:runAsync()、supplyAsync()需要异步操作且不关心返回结果的时候可以使用
runAsync()方法,异步操作且关心返回结果的时候,可以使用supplyAsync()方法
处理异步结果
thenApply()thenAccept()thenRun()whenComplete()
如果你不需要从回调函数中获取返回结果,可以使用 thenAccept() 或者 thenRun()。这两个方法的区别在于 thenRun() 不能访问异步计算的结果
异常处理
可以通过 handle() 方法来处理任务执行过程中可能出现的抛出异常的情况
1
2
3
4
5
6
7
8
9
10
11
12
13
CompletableFuture<String> future
= CompletableFuture.supplyAsync(() -> {
if (true) {
throw new RuntimeException("Computation error!");
}
return "hello!";
}).handle((res, ex) -> {
// res 代表返回的结果
// ex 的类型为 Throwable ,代表抛出的异常
return res != null ? res : "world!";
});
assertEquals("world!", future.get());
组合CompletableFuture
你可以使用 thenCompose() 按顺序链接两个 CompletableFuture 对象,实现异步的任务链。它的作用是将前一个任务的返回结果作为下一个任务的输入参数,从而形成一个依赖关系
1
2
3
4
5
CompletableFuture<String> future
= CompletableFuture.supplyAsync(() -> "hello!")
.thenCompose(s -> CompletableFuture.supplyAsync(() -> s + "world!"));
assertEquals("hello!world!", future.get());
那 thenCompose() 和 thenCombine() 有什么区别呢?
thenCompose()可以链接两个CompletableFuture对象,并将前一个任务的返回结果作为下一个任务的参数,它们之间存在着先后顺序。thenCombine()会在两个任务都执行完成后,把两个任务的结果合并。两个任务是并行执行的,它们之间并没有先后依赖顺序
并行运行多个 CompletableFuture
你可以通过 CompletableFuture 的 allOf()这个静态方法来并行运行多个 CompletableFuture
比说我们要读取处理 6 个文件,这 6 个任务都是没有执行顺序依赖的任务,但是我们需要返回给用户的时候将这几个文件的处理的结果进行统计整理。像这种情况我们就可以使用并行运行多个 CompletableFuture 来处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
CompletableFuture<Void> task1 =
CompletableFuture.supplyAsync(()->{
//自定义业务操作
});
......
CompletableFuture<Void> task6 =
CompletableFuture.supplyAsync(()->{
//自定义业务操作
});
......
CompletableFuture<Void> headerFuture=CompletableFuture.allOf(task1,.....,task6);
try {
//调用 join() 可以让程序等future1 和 future2 都运行完了之后再继续执行。
headerFuture.join();
} catch (Exception ex) {
......
}
System.out.println("all done. ");
一般建议配置自定义线程池使用
1
2
3
4
5
6
7
8
private ThreadPoolExecutor executor = new ThreadPoolExecutor(10, 10,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
CompletableFuture.runAsync(() -> {
//...
}, executor);
AQS
AQS 的全称为 AbstractQueuedSynchronizer ,翻译过来的意思就是抽象队列同步器
AQS 就是一个抽象类,主要用来构建锁和同步器
AQS 核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制 AQS 是用 CLH 队列锁 实现的,即将暂时获取不到锁的线程加入到队列中。
CLH队列锁:虚拟的双向队列(虚拟的双向队列即不存在队列实例,仅存在结点之间的关联关系)

AQS 是将每条请求共享资源的线程封装成一个 CLH 锁队列的一个结点(Node)来实现锁的分配。在 CLH 同步队列中,一个节点表示一个线程,它保存着线程的引用(thread)、 当前节点在队列中的状态(waitStatus)、前驱节点(prev)、后继节点(next)
AQS利用一个int变量state来表示资源的状态,通过内置的 线程等待队列 来完成获取资源线程的排队工作
state用volatile修饰,保证其可见性
1
2
// 共享变量,使用volatile修饰保证线程可见性
private volatile int state;
state通过下面几个方法进行操作,并且,这几个方法都是 final 修饰的,在子类中无法被重写
1
2
3
4
5
6
7
8
9
10
11
12
//返回同步状态的当前值
protected final int getState() {
return state;
}
// 设置同步状态的值
protected final void setState(int newState) {
state = newState;
}
//原子地(CAS操作)将同步状态值设置为给定值update如果当前同步状态的值等于expect(期望值)
protected final boolean compareAndSetState(int expect, int update) {
return unsafe.compareAndSwapInt(this, stateOffset, expect, update);
}
以 ReentrantLock 为例,state 初始值为 0,表示未锁定状态。A 线程 lock() 时,会调用 tryAcquire() 独占该锁并将 state+1 。此后,其他线程再 tryAcquire() 时就会失败,直到 A 线程 unlock() 到 state=0(即释放锁)为止,其它线程才有机会获取该锁。当然,释放锁之前,A 线程自己是可以重复获取此锁的(state 会累加),这就是可重入的概念。但要注意,获取多少次就要释放多少次,这样才能保证 state 是能回到零态的
AQS支持自定义实现同步器,AQS 使用了模板方法模式,自定义同步器时需要重写下面几个 AQS 提供的钩子方法:
1
2
3
4
5
6
7
8
9
10
11
//独占方式。尝试获取资源,成功则返回true,失败则返回false。
protected boolean tryAcquire(int)
//独占方式。尝试释放资源,成功则返回true,失败则返回false。
protected boolean tryRelease(int)
//共享方式。尝试获取资源。负数表示失败;0表示成功,但没有剩余可用资源;正数表示成功,且有剩余资源。
protected int tryAcquireShared(int)
//共享方式。尝试释放资源,成功则返回true,失败则返回false。
protected boolean tryReleaseShared(int)
//该线程是否正在独占资源。只有用到condition才需要去实现它。
protected boolean isHeldExclusively()
常见的同步工具
Semaphore(信号量)
synchronized 和 ReentrantLock 都是一次只允许一个线程访问某个资源,而Semaphore(信号量)可以用来控制同时访问特定资源的线程数量
Semaphore 有什么用
Semaphore(信号量)可以用来控制同时访问特定资源的线程数量。
1
2
3
4
5
6
7
// 初始共享资源数量
final Semaphore semaphore = new Semaphore(5);
// 获取1个许可
semaphore.acquire();
// 释放1个许可
semaphore.release();
Semaphore 有两种模式:。
- 公平模式: 调用
acquire()方法的顺序就是获取许可证的顺序,遵循 FIFO; - 非公平模式: 抢占式的。
这两个构造方法,都必须提供许可的数量,第二个构造方法可以指定是公平模式还是非公平模式,默认非公平模式
Semaphore 的原理是什么
Semaphore 是共享锁的一种实现,它默认构造 AQS 的 state 值为 permits,你可以将 permits 的值理解为许可证的数量,只有拿到许可证的线程才能执行。
获取资源
调用semaphore.acquire() ,线程尝试获取许可证,如果 state >= 0 的话,则表示可以获取成功。如果获取成功的话,使用 CAS 操作去修改 state 的值 state=state-1。如果 state<0 的话,则表示许可证数量不足。此时会创建一个 Node 节点加入阻塞队列,挂起当前线程。
释放资源
调用semaphore.release(); ,线程尝试释放许可证,并使用 CAS 操作去修改 state 的值 state=state+1。释放许可证成功之后,同时会唤醒同步队列中的一个线程。被唤醒的线程会重新尝试去修改 state 的值 state=state-1 ,如果 state>=0 则获取令牌成功,否则重新进入阻塞队列,挂起线程。
下面就是信号量的运用semaphore.acquire(),获取一个许可。如果信号量的许可数不足(即已有20个线程在运行),这个调用会阻塞,直到某个线程释放一个许可。test(threadnum)调用模拟一个耗时操作。完成操作后,调用semaphore.release()释放许可,允许其他等待的线程进入。
- 代码中的信号量初始有20个许可,这意味着最多有20个线程可以同时进入
test(threadnum)方法进行处理。 - 这个机制确保了即使有550个任务被提交到拥有300个线程的线程池中,也只有20个任务会同时执行。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
public class SemaphoreExample {
// 请求的数量
private static final int threadCount = 550;
public static void main(String[] args) throws InterruptedException {
// 创建一个具有固定线程数量的线程池对象(如果这里线程池的线程数量给太少的话你会发现执行的很慢)
ExecutorService threadPool = Executors.newFixedThreadPool(300);
// 初始许可证数量
final Semaphore semaphore = new Semaphore(20);
for (int i = 0; i < threadCount; i++) {
final int threadnum = i;
threadPool.execute(() -> {// Lambda 表达式的运用
try {
semaphore.acquire();// 获取一个许可,所以可运行线程数量为20/1=20
test(threadnum);
semaphore.release();// 释放一个许可
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
});
}
threadPool.shutdown();
System.out.println("finish");
}
public static void test(int threadnum) throws InterruptedException {
Thread.sleep(1000);// 模拟请求的耗时操作
System.out.println("threadnum:" + threadnum);
Thread.sleep(1000);// 模拟请求的耗时操作
}
}
CountDownLatch 有什么用
CountDownLatch 允许 count 个线程阻塞在同一个地方,直至所有线程的任务都执行完毕,就是所有线程任务都完成了,才都唤醒执行后面的任务
CountDownLatch 内部维护了一个计数器,该计数器初始化为一个正整数,表示需要等待的线程数目。每当一个线程完成自己的任务后,计数器就会减一,直到计数器的值减至零,所有等待的线程将被唤醒
其原理也是默认构造 AQS 的 state 值为 count,使用了tryReleaseShared方法以 CAS 的操作来减少 state,直至 state 为 0 。
运用场景
允许 count 个线程阻塞在一个地方,直至所有线程的任务都执行完毕。
比如说要读取处理 6 个文件,这 6 个任务都是没有执行顺序依赖的任务,但是我们需要返回给用户的时候将这几个文件的处理的结果进行统计整理
为此我们定义了一个线程池和 count 为 6 的CountDownLatch对象 。使用线程池处理读取任务,每一个线程处理完之后就将 count-1,调用CountDownLatch对象的 await()方法,直到所有文件读取完之后,才会接着执行后面的逻辑。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class FileProcessorWithThreadPool {
public static void main(String[] args) throws InterruptedException {
int numberOfFiles = 6; // 处理的文件数量
CountDownLatch latch = new CountDownLatch(numberOfFiles);
// 线程池配置
int corePoolSize = 5; // 核心线程数
int maximumPoolSize = 10; // 最大线程数
long keepAliveTime = 5000; // 空闲线程的存活时间(毫秒)
int queueCapacity = 100; // 工作队列的容量
ThreadPoolExecutor executor = new ThreadPoolExecutor(
corePoolSize,
maximumPoolSize,
keepAliveTime,
TimeUnit.MILLISECONDS,
new ArrayBlockingQueue<>(queueCapacity),
new ThreadPoolExecutor.CallerRunsPolicy() // 拒绝策略
);
for (int i = 0; i < numberOfFiles; i++) {
int fileIndex = i;
executor.submit(() -> {
try {
// 在这里处理文件读取和相关逻辑
System.out.println("Processing file " + fileIndex);
// 模拟文件处理时间
Thread.sleep(1000); // 假设每个文件处理需要1秒
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} finally {
// 处理完毕后,减少latch计数
latch.countDown();
}
});
}
// 等待直到所有文件都被处理
latch.await();
System.out.println("All files have been processed. Continue with the remaining logic.");
// 关闭线程池
executor.shutdown();
}
}
CyclicBarrier 有什么用
CyclicBarrier 和 CountDownLatch 非常类似,它也可以实现线程间的技术等待,但是它的功能比 CountDownLatch 更加复杂和强大。主要应用场景和 CountDownLatch 类似。
CountDownLatch的实现是基于 AQS 的,而CycliBarrier是基于ReentrantLock(ReentrantLock也属于 AQS 同步器)和Condition的。
CyclicBarrier 的字面意思是可循环使用(Cyclic)的屏障(Barrier)。它要做的事情是:让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续干活。
特点
- 可重用:与
CountDownLatch不同,CyclicBarrier是可重用的。一旦所有等待线程都到达屏障点,它就可以重置并再次使用。 - 屏障操作:你可以提供一个屏障操作,这是一个在所有线程到达屏障后执行的Runnable任务。这可以用于更新共享状态或合并结果。
- 灵活性:线程可以随时告知
CyclicBarrier它们已经到达了屏障点。这意味着线程不需要同时启动,它们可以在准备好后到达屏障点。 - 异常处理:如果一个线程在到达屏障前被中断或超时,
CyclicBarrier会进入损坏状态,这将导致所有等待的线程接收到BrokenBarrierException。这允许线程处理异常情况并且可以选择重新尝试或做其他处理。
基本原理
- 初始化屏障点:当创建一个
CyclicBarrier实例时,你需要指定一个整数N,它表示需要到达屏障点的线程数量。你还可以(可选地)提供一个Runnable任务,当所有线程都到达屏障时,这个任务会被执行。 - 等待屏障:线程通过调用
CyclicBarrier的await()方法来告知它们已经到达屏障点。调用await()方法的线程将会被阻塞,直到所有线程都达到了屏障。 - 屏障操作执行:当最后一个线程到达屏障点时,如果提供了屏障操作(Runnable任务),它将首先被执行。这通常用于在所有线程继续之前执行一些集体的更新操作。
- 释放等待的线程:屏障操作完成后,所有等待在
CyclicBarrier上的线程都将被释放,可以继续它们各自的执行。 - 重用:一旦所有线程都被释放,
CyclicBarrier就被重置,可以再次使用。这意味着它可以在多阶段的计算过程中反复使用。
JMM
Java内存模型(Java Memory Model,简称JMM)是一种抽象的概念,它描述了Java虚拟机(JVM)在计算机内存中的工作方式。
JMM定义了Java程序中各个变量(包括实例字段、静态字段和数组元素)的访问规则,以及线程之间如何通过内存进行交互。
主要目的是为了解决多线程环境中的可见性、原子性和有序性问题,确保程序在多核处理器上的正确执行。
- 可见性(Visibility)
可见性是指当一个线程修改了共享变量的值,其他线程能够立即得知这个修改。在没有使用合适的同步机制的情况下,一个线程对共享变量的修改可能对其他线程不可见。JMM通过内存屏障和volatile关键字来保证可见性。
- 原子性(Atomicity)
原子性是指一个操作要么全部执行成功,要么完全不执行,不会出现执行了一半的情况。在Java中,对基本数据类型的变量赋值(除了long和double类型的变量)是原子操作,但是对于其他操作(比如i++)则不是原子操作。JMM通过锁和synchronized关键字来保证操作的原子性。
- 有序性(Ordering)
有序性是指程序执行的顺序按照代码的先后顺序执行。在多线程环境中,由于编译器优化和处理器优化,指令重排序可能会发生,导致执行顺序与代码顺序不一致。JMM通过内存屏障和volatile关键字来保证有序性。
- 内存屏障(Memory Barrier)
内存屏障是一种CPU指令,用于实现可见性和有序性。它可以阻止特定类型的处理器重排序,并确保某些操作的执行顺序。
- volatile关键字
volatile是Java提供的一种轻量级的同步机制。声明为volatile的变量可以保证其对所有线程的可见性,同时还可以防止指令重排序。
- happens-before原则
JMM定义了一组happens-before关系,用于确定程序中两个操作之间的顺序。如果一个操作happens-before另一个操作,那么第一个操作的结果对第二个操作是可见的,并且第一个操作在第二个操作之前发生。
CPU缓存模型
CPU 缓存则是为了解决 CPU 处理速度和内存处理速度不对等的问题。
可以把 内存看作外存的高速缓存,程序运行的时候我们把外存的数据复制到内存,由于内存的处理速度远远高于外存,这样提高了处理速度
CPU Cache 缓存的是内存数据用于解决 CPU 处理速度和内存不匹配的问题,内存缓存的是硬盘数据用于解决硬盘访问速度过慢的问题
CPU Cache 的工作方式: 先复制一份数据到 CPU Cache 中,当 CPU 需要用到的时候就可以直接从 CPU Cache 中读取数据,当运算完成后,再将运算得到的数据写回 Main Memory 中。
但是,这样存在 内存缓存不一致性的问题 !比如我执行一个 i++ 操作的话,如果两个线程同时执行的话,假设两个线程从 CPU Cache 中读取的 i=1,两个线程做了 i++ 运算完之后再写回 Main Memory 之后 i=2,而正确结果应该是 i=3。
为此CPU 为了解决内存缓存不一致性问题可以通过制定缓存一致协议(比如 MESI 协议open in new window)或者其他手段来解决。
我们的程序运行在操作系统之上,操作系统屏蔽了底层硬件的操作细节,将各种硬件资源虚拟化。于是,操作系统也就同样需要解决内存缓存不一致性问题,因此操作系统通过 内存模型(Memory Model) 定义一系列规范来解决这个问题。无论是 Windows 系统,还是 Linux 系统,它们都有特定的内存模型
指令重排序
为了提升执行速度/性能,系统在执行代码的时候并不一定是按照你写的代码的顺序依次执行
一般有下面两种情况:
- 编译器优化重排:编译器(包括 JVM、JIT 编译器等)在不改变单线程程序语义的前提下,重新安排语句的执行顺序。
- 指令并行重排:现代处理器采用了指令级并行技术(Instruction-Level Parallelism,ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序
Java 源代码会经历 编译器优化重排 —> 指令并行重排 —> 内存系统重排的过程,最终才变成操作系统可执行的指令序列
在多线程的情况下,指令重排序可能会导致一些问题
编译器和处理器的指令重排序的处理方式不一样。
- 对于编译器,通过禁止特定类型的编译器重排序的方式来禁止重排序。
- 对于处理器,通过插入内存屏障(Memory Barrier,或有时叫做内存栅栏,Memory Fence)的方式来禁止特定类型的处理器重排序。指令并行重排和内存系统重排都属于是处理器级别的指令重排序
JMM
需要JMM的原因
- 对于一般的编程语言而言,其实是可以直接复用操作系统层面的内存模型,不过不同的操作系统其内存模型是不一样的,java语言是跨平台的,所以需要自己提供一套内存模型以屏蔽系统差异
- JMM 可以看作是 Java 定义的并发编程相关的一组规范,除了抽象了线程和主内存之间的关系之外,其还规定了从 Java 源代码到 CPU 可执行指令的这个转化过程要遵守哪些和并发相关的原则和规范
JMM如何抽象线程和主内存之间的关系
比如说线程之间的共享变量必须存储在主内存中
-
主内存:所有线程创建的实例对象都存放在主内存中,不管该实例对象是成员变量,还是局部变量,类信息、常量、静态变量都是放在主内存中。为了获取更好的运行速度,虚拟机及硬件系统可能会让工作内存优先存储于寄存器和高速缓存中。
-
本地内存:每个线程都有一个私有的本地内存,本地内存存储了该线程以读 / 写共享变量的副本。每个线程只能操作自己本地内存中的变量,无法直接访问其他线程的本地内存。如果线程间需要通信,必须通过主内存来进行。
本地内存是 JMM 抽象出来的一个概念,并不真实存在,它涵盖了缓存、写缓冲区、寄存器以及其他的硬件和编译器优化。每个线程都有自己的工作内存,它是主内存的私有拷贝。线程对变量的所有操作(读取、赋值等)都必须在工作内存中进行,然后再同步回主内存。
主内存和本地内存相互交互通过以下8个同步操作进行

除了这 8 种同步操作之外,还规定了下面这些同步规则来保证这些同步操作的正确执行

java内存区域和内存模型是两个概念
- JVM 内存区域和 Java 虚拟机的运行时区域相关,定义了 JVM 在运行时如何分区存储程序数据,就比如说堆主要用于存放对象实例
- Java 内存模型和 Java 的并发编程相关,抽象了线程和主内存之间的关系就比如说线程之间的共享变量必须存储在主内存中,规定了从 Java 源代码到 CPU 可执行指令的这个转化过程要遵守哪些和并发相关的原则和规范,其主要目的是为了简化多线程编程,增强程序可移植性的
happens-before 原则是什么
Happens-Before规则:这是JMM中最核心的部分,它为程序员提供了判断数据是否安全发布(Safe Publication)、线程间的操作是否可以无需同步等问题的指导。如果一个操作A happens-before操作B,那么操作A的结果对操作B是可见的
核心思想:
-
为了对编译器和处理器的约束尽可能少,只要不改变程序的执行结果(单线程程序和正确执行的多线程程序),编译器和处理器怎么进行重排序优化都行。
-
对于会改变程序执行结果的重排序,JMM 要求编译器和处理器必须禁止这种重排序
具体规则:
- 如果一个操作 happens-before 另一个操作,那么第一个操作的执行结果将对第二个操作可见,并且第一个操作的执行顺序排在第二个操作之前。
- 两个操作之间存在 happens-before 关系,并不意味着 Java 平台的具体实现必须要按照 happens-before 关系指定的顺序来执行。如果重排序之后的执行结果,与按 happens-before 关系来执行的结果一致,那么 JMM 也允许这样的重排序。
JMM常用规则
- 程序顺序规则:一个线程内,按照代码顺序,书写在前面的操作 happens-before 于书写在后面的操作;
- 解锁规则:解锁 happens-before 于加锁;
- volatile 变量规则:对一个 volatile 变量的写操作 happens-before 于后面对这个 volatile 变量的读操作。说白了就是对 volatile 变量的写操作的结果对于发生于其后的任何操作都是可见的。
- 传递规则:如果 A happens-before B,且 B happens-before C,那么 A happens-before C;
- 线程启动规则:Thread 对象的
start()方法 happens-before 于此线程的每一个动作。
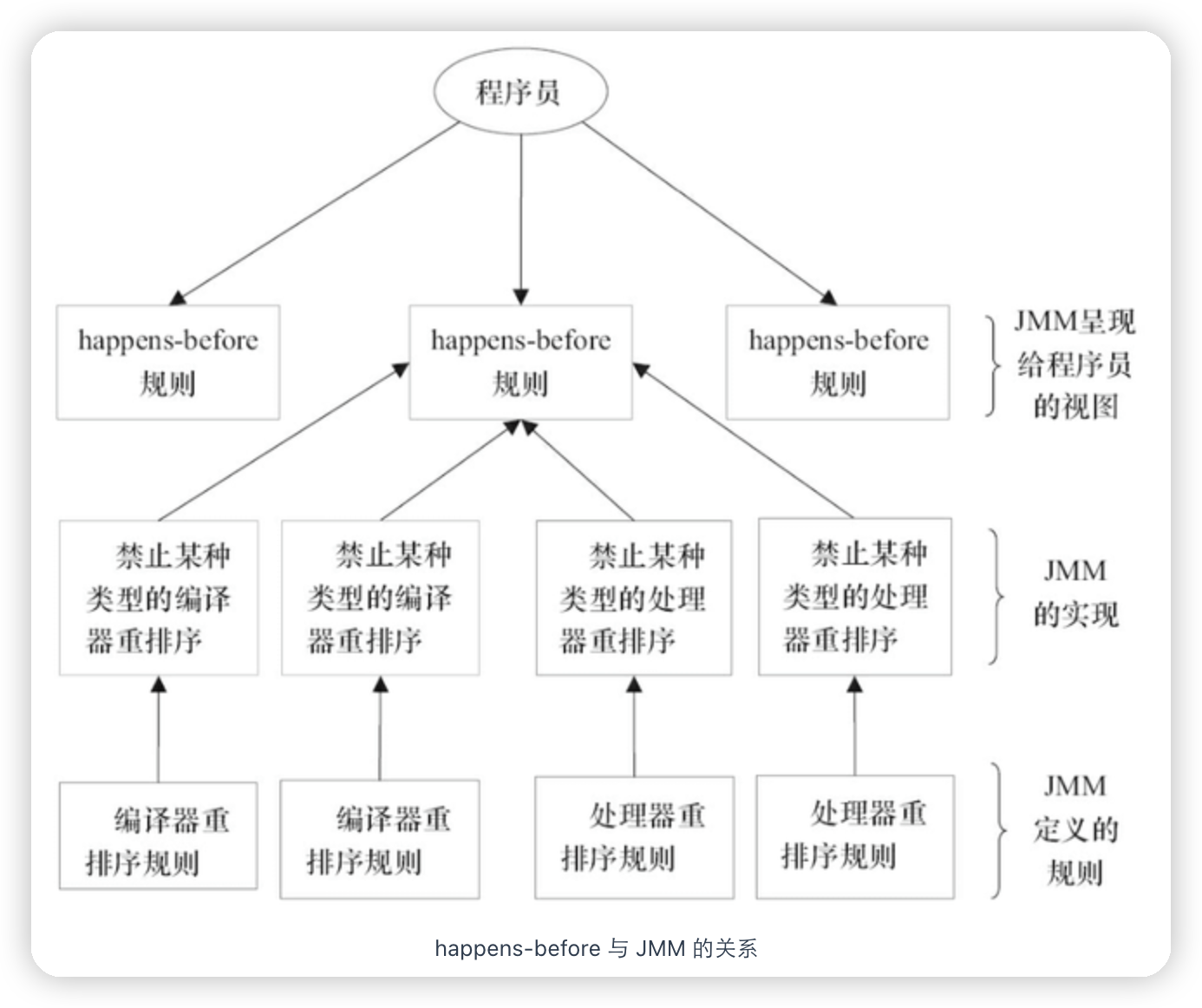
并发编程三个重要特性
-
原子性
一次操作或者多次操作,要么所有的操作全部都得到执行并且不会受到任何因素的干扰而中断,要么都不执行,可以借助
synchronized、各种Lock以及各种原子类实现原子性 -
可见性
当一个线程对共享变量进行了修改,那么另外的线程都是立即可以看到修改后的最新值,可以借助
synchronized、volatile以及各种Lock实现可见性 -
有序性
由于指令重排序问题,代码的执行顺序未必就是编写代码时候的顺序,
volatile关键字可以禁止指令进行重排序优化
Java 常见并发容器
-
ConcurrentHashMap: 线程安全的HashMapHashMap不是线程安全的,所以就有了HashMap的线程安全版本——ConcurrentHashMap的诞生 -
CopyOnWriteArrayList: 线程安全的List,在读多写少的场合性能非常好,远远好于Vector。以前想要并发的List就只有vector,但vector太旧了,已经被舍弃了并且对于增删改查等方法基本都加了
synchronized,所以性能十分低下,CopyOnWriteArrayList中的读取操作是完全无需加锁的。更加厉害的是,写入操作也不会阻塞读取操作,只有写写才会互斥。这样一来,读操作的性能就可以大幅度提升当需要修改(
add,set、remove等操作)CopyOnWriteArrayList的内容时,不会直接修改原数组,而是会先创建底层数组的副本,对副本数组进行修改,修改完之后再将修改后的数组赋值回去,这样就可以保证写操作不会影响读操作了 -
ConcurrentLinkedQueue: 高效的并发队列,使用链表实现。可以看做一个线程安全的LinkedList,这是一个非阻塞队列。Java 提供的线程安全的
Queue可以分为阻塞队列和非阻塞队列,其中阻塞队列的典型例子是BlockingQueue,非阻塞队列的典型例子是ConcurrentLinkedQueue阻塞队列可以通过加锁来实现,非阻塞队列可以通过 CAS 操作实现
对性能要求相对较高,同时对队列的读写存在多个线程同时进行的场景,即如果对队列加锁的成本较高则适合使用无锁的
ConcurrentLinkedQueue来替代 -
BlockingQueue: 这是一个接口,JDK 内部通过链表、数组等方式实现了这个接口。表示阻塞队列,非常适合用于作为数据共享的通道。阻塞队列(
BlockingQueue)被广泛使用在“生产者-消费者”问题中,其原因是BlockingQueue提供了可阻塞的插入和移除的方法。当队列容器已满,生产者线程会被阻塞,直到队列未满;当队列容器为空时,消费者线程会被阻塞,直至队列非空时为止BlockingQueue是一个接口,下面主要介绍一下 3 个常见的BlockingQueue的实现类:ArrayBlockingQueue、LinkedBlockingQueue、PriorityBlockingQueue-
ArrayBlockingQueueArrayBlockingQueue是BlockingQueue接口的有界队列实现类,底层采用数组来实现一旦创建,容量不能改变。其并发控制采用可重入锁
ReentrantLock,不管是插入操作还是读取操作,都需要获取到锁才能进行操作。当队列容量满时,尝试将元素放入队列将导致操作阻塞;尝试从一个空队列中取一个元素也会同样阻塞默认情况下不能保证线程访问队列的公平性
-
LinkedBlockingQueueLinkedBlockingQueue底层基于单向链表实现的阻塞队列,可以当做无界队列也可以当做有界队列来使用为了防止
LinkedBlockingQueue容量迅速增,损耗大量内存。通常在创建LinkedBlockingQueue对象时,会指定其大小,如果未指定,容量等于Integer.MAX_VALUE。 -
PriorityBlockingQueue支持优先级的无界阻塞队列,采用的是可重入锁
ReentrantLock,队列为无界队列,不可以插入 null 值,插入队列的对象必须是可比较大小的
-
-
ConcurrentSkipListMap: 跳表的实现。这是一个 Map,使用跳表的数据结构进行快速查找跳表:跳表是一种可以用来快速查找的数据结构,有点类似于平衡树。它们都可以对元素进行快速的查找,但一个重要的区别是:对平衡树的插入和删除往往很可能导致平衡树进行一次全局的调整。而对跳表的插入和删除只需要对整个数据结构的局部进行操作即可。这样带来的好处是:在高并发的情况下,你会需要一个全局锁来保证整个平衡树的线程安全。而对于跳表,你只需要部分锁即可。这样,在高并发环境下,你就可以拥有更好的性能。而就查询的性能而言,跳表的时间复杂度也是 O(logn) 所以在并发数据结构中,JDK 使用跳表来实现一个 Map。
其本质就是维护多个链表
原子类总结
基本类型原子类
AtomicInteger:整型原子类AtomicLong:长整型原子类AtomicBoolean:布尔型原子类
1
2
3
4
5
6
7
8
public final int get() //获取当前的值
public final int getAndSet(int newValue)//获取当前的值,并设置新的值
public final int getAndIncrement()//获取当前的值,并自增
public final int getAndDecrement() //获取当前的值,并自减
public final int getAndAdd(int delta) //获取当前的值,并加上预期的值
boolean compareAndSet(int expect, int update) //如果输入的数值等于预期值,则以原子方式将该值设置为输入值(update)
public final void lazySet(int newValue)//最终设置为newValue,使用 lazySet 设置之后可能导致其他线程在之后的一小段时间内还是可以读到旧的值。
使用基本类型原子类的好处
- 多线程环境不使用原子类保证线程安全(基本数据类型)
1
2
3
4
5
6
7
8
9
10
11
12
class Test {
private volatile int count = 0;
//若要线程安全执行执行count++,需要加锁
public synchronized void increment() {
count++;
}
public int getCount() {
return count;
}
}
- 多线程环境使用原子类保证线程安全(基本数据类型)
1
2
3
4
5
6
7
8
9
10
11
12
13
class Test2 {
private AtomicInteger count = new AtomicInteger();
public void increment() {
count.incrementAndGet();
}
//使用AtomicInteger之后,不需要加锁,也可以实现线程安全。
public int getCount() {
return count.get();
}
}
AtomicInteger 类主要利用 CAS (compare and swap) + volatile 和 native 方法来保证原子操作,从而避免 synchronized 的高开销,执行效率大为提升。
数组类型原子类
AtomicIntegerArray:整形数组原子类AtomicLongArray:长整形数组原子类AtomicReferenceArray:引用类型数组原子类
1
2
3
4
5
6
7
public final int get(int i) //获取 index=i 位置元素的值
public final int getAndSet(int i, int newValue)//返回 index=i 位置的当前的值,并将其设置为新值:newValue
public final int getAndIncrement(int i)//获取 index=i 位置元素的值,并让该位置的元素自增
public final int getAndDecrement(int i) //获取 index=i 位置元素的值,并让该位置的元素自减
public final int getAndAdd(int i, int delta) //获取 index=i 位置元素的值,并加上预期的值
boolean compareAndSet(int i, int expect, int update) //如果输入的数值等于预期值,则以原子方式将 index=i 位置的元素值设置为输入值(update)
public final void lazySet(int i, int newValue)//最终 将index=i 位置的元素设置为newValue,使用 lazySet 设置之后可能导致其他线程在之后的一小段时间内还是可以读到旧的值。
使用事例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
import java.util.concurrent.atomic.AtomicIntegerArray;
public class AtomicIntegerArrayTest {
public static void main(String[] args) {
int temvalue = 0;
int[] nums = { 1, 2, 3, 4, 5, 6 };
AtomicIntegerArray i = new AtomicIntegerArray(nums);
for (int j = 0; j < nums.length; j++) {
System.out.println(i.get(j));
}
temvalue = i.getAndSet(0, 2);
System.out.println("temvalue:" + temvalue + "; i:" + i);
temvalue = i.getAndIncrement(0);
System.out.println("temvalue:" + temvalue + "; i:" + i);
temvalue = i.getAndAdd(0, 5);
System.out.println("temvalue:" + temvalue + "; i:" + i);
}
}
引用类型原子类
基本类型原子类只能更新一个变量,如果需要原子更新多个变量,需要使用 引用类型原子类
-
AtomicReference:引用类型原子类 -
AtomicStampedReference:原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于解决原子的更新数据和数据的版本号,可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。 -
AtomicMarkableReference:原子更新带有标记的引用类型。该类将 boolean 标记与引用关联起来
AtomicReference 类使用示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
import java.util.concurrent.atomic.AtomicReference;
public class AtomicReferenceTest {
public static void main(String[] args) {
AtomicReference < Person > ar = new AtomicReference < Person > ();
Person person = new Person("SnailClimb", 22);
ar.set(person);
Person updatePerson = new Person("Daisy", 20);
ar.compareAndSet(person, updatePerson);
System.out.println(ar.get().getName());
System.out.println(ar.get().getAge());
}
}
class Person {
private String name;
private int age;
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
对象的属性修改类型原子类
如果需要原子更新某个类里的某个字段时,需要用到对象的属性修改类型原子类
-
AtomicIntegerFieldUpdater:原子更新整形字段的更新器 -
AtomicLongFieldUpdater:原子更新长整形字段的更新器 -
AtomicReferenceFieldUpdater:原子更新引用类型里的字段的更新器
操作规则
- 每次使用都必须使用静态方法 newUpdater()创建一个更新器,并且需要设置想要更新的类和属性
- 更新的对象属性必须使用 public volatile 修饰符
样例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
import java.util.concurrent.atomic.AtomicIntegerFieldUpdater;
public class AtomicIntegerFieldUpdaterTest {
public static void main(String[] args) {
AtomicIntegerFieldUpdater<User> a = AtomicIntegerFieldUpdater.newUpdater(User.class, "age");
User user = new User("Java", 22);
System.out.println(a.getAndIncrement(user));// 22
System.out.println(a.get(user));// 23
}
}
class User {
private String name;
public volatile int age;
public User(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
虚拟线程
虚拟线程(Virtual Thread)是 JDK 而不是 OS 实现的轻量级线程(Lightweight Process,LWP),由 JVM 调度。许多虚拟线程共享同一个操作系统线程,虚拟线程的数量可以远大于操作系统线程的数量

Spring
Spring,Spring MVC,Spring Boot 之间什么关系
Spring MVC 是 Spring 中的一个很重要的模块,主要赋予 Spring 快速构建 MVC 架构的 Web 程序的能力。
MVC 是模型(Model)、视图(View)、控制器(Controller)的简写,其核心思想是通过将业务逻辑、数据、显示分离来组织代码
使用 Spring 进行开发各种配置过于麻烦比如开启某些 Spring 特性时,需要用 XML 或 Java 进行显式配置,因此springboot由此诞生
Spring IoC
IoC是一种设计思想,而不是一个具体的技术实现。IoC 的思想就是将原本在程序中手动创建对象的控制权,交由 Spring 框架来管理。不过, IoC 并非 Spring 特有,在其他语言中也有应用。
什么叫控制反转
- 控制:指的是对象创建(实例化、管理)的权力
- 反转:控制权交给外部环境(Spring 框架、IoC 容器)
将对象之间的相互依赖关系交给 IoC 容器来管理,并由 IoC 容器完成对象的注入,把应用从复杂的依赖关系中解放出来,解耦
在 Spring 中, IoC 容器是 Spring 用来实现 IoC 的载体, IoC 容器实际上就是个 Map(key,value),Map 中存放的是各种对象
Spring Bean
Bean 代指的就是那些被 IoC 容器所管理的对象
告诉 IoC 容器帮助我们管理哪些对象,这个是通过配置元数据来定义的。配置元数据可以是 XML 文件、注解或者 Java 配置类
1
2
3
4
5
<!-- Constructor-arg with 'value' attribute -->
<bean id="..." class="...">
<constructor-arg value="..."/>
</bean>
将一个类声明成Bean的注解有
@Component:通用的注解,可标注任意类为Spring组件。如果一个 Bean 不知道属于哪个层,可以使用@Component注解标注。@Repository: 对应持久层即 Dao 层,主要用于数据库相关操作。@Service: 对应服务层,主要涉及一些复杂的逻辑,需要用到 Dao 层。@Controller: 对应 Spring MVC 控制层,主要用于接受用户请求并调用Service层返回数据给前端页面。
@Component 和 @Bean 的区别是什么
@Component 注解作用于类,而@Bean注解作用于方法。
@Component通常是通过类路径扫描来自动侦测以及自动装配到 Spring 容器中(我们可以使用 @ComponentScan 注解定义要扫描的路径从中找出标识了需要装配的类自动装配到 Spring 的 bean 容器中)。
@Bean 注解通常是我们在标有该注解的方法中定义产生这个 bean,@Bean告诉了 Spring 这是某个类的实例,当我需要用它的时候还给我。
@Bean 注解比 @Component 注解的自定义性更强,而且很多地方我们只能通过 @Bean 注解来注册 bean。
比如当我们引用第三方库中的类需要装配到 Spring容器时(但这个类不在你的控制之下,即你无法在它的类定义上添加@Component或其他类似的注解),则只能通过 @Bean来实现。
一般是首先创建一个配置类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import com.thirdparty.ThirdPartyClass; // 假设这是第三方库中的类
@Configuration
public class AppConfig {
@Bean
public ThirdPartyClass thirdPartyClass() {
// 创建ThirdPartyClass的实例
ThirdPartyClass thirdPartyClass = new ThirdPartyClass();
// 配置实例(如果需要)
// thirdPartyClass.setSomeProperty(value);
return thirdPartyClass;
}
}
在Spring应用程序的其他部分通过依赖注入使用这个bean
1
2
3
4
5
6
7
8
9
10
11
12
13
import org.springframework.beans.factory.annotation.Autowired;
import com.thirdparty.ThirdPartyClass;
public class SomeService {
private final ThirdPartyClass thirdPartyClass;
@Autowired
public SomeService(ThirdPartyClass thirdPartyClass) {
this.thirdPartyClass = thirdPartyClass;
}
// 使用thirdPartyClass实例的方法...
}
Spring 内置的 @Autowired 以及 JDK 内置的 @Resource 和 @Inject 都可以用于注入 Bean。
@Autowired 和 @Resource 的区别是什么
Autowired 属于 Spring 内置的注解,默认的注入方式为byType(根据类型进行匹配),也就是说会优先根据接口类型去匹配并注入 Bean,这种方式存在的问题是如果一个接口存在多个实现类的话,这个时候就不知道注入哪个类了,就需要通过 @Qualifier 注解来显式指定名称而不是依赖变量的名称
1
2
3
4
5
6
7
8
9
10
11
// 报错,byName 和 byType 都无法匹配到 bean
@Autowired
private SmsService smsService;
// 正确注入 SmsServiceImpl1 对象对应的 bean
@Autowired
private SmsService smsServiceImpl1;
// 正确注入 SmsServiceImpl1 对象对应的 bean
// smsServiceImpl1 就是我们上面所说的名称
@Autowired
@Qualifier(value = "smsServiceImpl1")
private SmsService smsService;
@Resource属于 JDK 提供的注解,默认注入方式为 byName。如果无法通过名称匹配到对应的 Bean 的话,注入方式会变为byType
如果仅指定 name 属性则注入方式为byName,如果仅指定type属性则注入方式为byType,如果同时指定name 和type属性(不建议这么做)则注入方式为byType+byName
1
2
3
4
5
6
7
8
9
// 报错,byName 和 byType 都无法匹配到 bean
@Resource
private SmsService smsService;
// 正确注入 SmsServiceImpl1 对象对应的 bean
@Resource
private SmsService smsServiceImpl1;
// 正确注入 SmsServiceImpl1 对象对应的 bean(比较推荐这种方式)
@Resource(name = "smsServiceImpl1")
private SmsService smsService;
总结:
-
@Autowired是 Spring 提供的注解,@Resource是 JDK 提供的注解。 -
Autowired默认的注入方式为byType(根据类型进行匹配),@Resource默认注入方式为byName(根据名称进行匹配)。 -
当一个接口存在多个实现类的情况下,
@Autowired和@Resource都需要通过名称才能正确匹配到对应的 Bean。Autowired可以通过@Qualifier注解来显式指定名称,@Resource可以通过name属性来显式指定名称。 -
@Autowired支持在构造函数、方法、字段和参数上使用。@Resource主要用于字段和方法上的注入,不支持在构造函数或参数上使用
Bean 的作用域有哪些
-
singleton : IoC 容器中只有唯一的 bean 实例。Spring 中的 bean 默认都是单例的,是对单例设计模式的应用。
-
prototype : 每次获取都会创建一个新的 bean 实例。也就是说,连续
getBean()两次,得到的是不同的 Bean 实例。 -
request (仅 Web 应用可用): 每一次 HTTP 请求都会产生一个新的 bean(请求 bean),该 bean 仅在当前 HTTP request 内有效。
-
session (仅 Web 应用可用) : 每一次来自新 session 的 HTTP 请求都会产生一个新的 bean(会话 bean),该 bean 仅在当前 HTTP session 内有效。
-
application/global-session (仅 Web 应用可用):每个 Web 应用在启动时创建一个 Bean(应用 Bean),该 bean 仅在当前应用启动时间内有效。
-
websocket (仅 Web 应用可用):每一次 WebSocket 会话产生一个新的 bean。
1
2
3
4
5
@Bean
@Scope(value = ConfigurableBeanFactory.SCOPE_PROTOTYPE)
public Person personPrototype() {
return new Person();
}
Bean 是线程安全的吗
Spring 框架中的 Bean 是否线程安全,取决于其作用域和状态
prototype 作用域下,每次获取都会创建一个新的 bean 实例,不存在资源竞争问题,所以不存在线程安全问题。
singleton 作用域下,IoC 容器中只有唯一的 bean 实例,可能会存在资源竞争问题(取决于 Bean 是否有状态)。如果这个 bean 是有状态的话,那就存在线程安全问题(有状态 Bean 是指包含可变的成员变量的对象)
对于有状态单例 Bean 的线程安全问题,常见的有两种解决办法:
- 在 Bean 中尽量避免定义可变的成员变量。
- 在类中定义一个
ThreadLocal成员变量,将需要的可变成员变量保存在ThreadLocal中(推荐的一种方式)
Bean 的生命周期
- 实例化Bean:
- Spring容器首先找到配置文件中的Spring Bean定义。
- 使用Java反射API创建Bean的实例。
- 设置Bean属性:
- 如果Bean定义中有属性需要注入,则使用setter方法设置这些属性值。
- Aware接口方法调用:
- 如果Bean实现了
BeanNameAware接口,Spring调用setBeanName()方法,传入Bean的名字。 - 如果实现了
BeanClassLoaderAware接口,调用setBeanClassLoader()方法,传入ClassLoader对象的实例。 - 如果实现了
BeanFactoryAware接口,调用setBeanFactory()方法,传入BeanFactory对象的实例。 - 类似地,如果实现了其他
*.Aware接口,Spring调用相应的方法。
- 如果Bean实现了
- BeanPostProcessor的前置处理:
- 如果存在与Bean相关的
BeanPostProcessor对象,执行postProcessBeforeInitialization()方法。
- 如果存在与Bean相关的
- 初始化:
- 如果Bean实现了
InitializingBean接口,执行afterPropertiesSet()方法。 - 如果Bean的定义中包含
init-method属性,执行指定的方法。
- 如果Bean实现了
- BeanPostProcessor的后置处理:
- 执行
postProcessAfterInitialization()方法。
- 执行
- 使用Bean:
- 此时,Bean已完全构建并准备好使用。
- 销毁Bean:
- 当容器关闭时,如果Bean实现了
DisposableBean接口,执行destroy()方法。 - 如果Bean的定义中包含
destroy-method属性,执行指定的方法。
- 当容器关闭时,如果Bean实现了
Spring AoP
能够将那些与业务无关,却为业务模块所共同调用的逻辑或责任(例如事务处理、日志管理、权限控制等)封装起来,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可拓展性和可维护性
Spring AOP 就是基于动态代理的,如果要代理的对象,实现了某个接口,那么 Spring AOP 会使用 JDK Proxy,去创建代理对象,而对于没有实现接口的对象,就无法使用 JDK Proxy 去进行代理了,这时候 Spring AOP 会使用 Cglib 生成一个被代理对象的子类来作为代理
考虑以下两个类,一个实现了接口,另一个没有:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public interface MyService {
void performAction();
}
public class MyServiceImpl implements MyService {
public void performAction() {
System.out.println("Performing action in MyServiceImpl");
}
}
public class MyComponent {
public void performAction() {
System.out.println("Performing action in MyComponent");
}
}
在这个例子中,MyServiceImpl实现了MyService接口,而MyComponent没有实现任何接口。
当你使用Spring AOP来为这些类创建代理时,处理将如下:
- 对于
MyServiceImpl(实现了接口的类),Spring将使用JDK动态代理。 - 对于
MyComponent(没有实现接口的类),Spring将使用Cglib代理。
配置spring aop
1
2
3
4
5
6
7
8
9
@Aspect
@Component
public class MyAspect {
@Before("execution(* com.yourpackage..*.*(..))")
public void beforeAdvice(JoinPoint joinPoint) {
System.out.println("Before method: " + joinPoint.getSignature().getName());
}
}

Spring AOP 和 AspectJ AOP 有什么区别
Spring AOP 属于运行时增强,而 AspectJ 是编译时增强。 Spring AOP 基于代理(Proxying),而 AspectJ 基于字节码操作(Bytecode Manipulation),如果我们的切面比较少,那么两者性能差异不大。但是,当切面太多的话,最好选择 AspectJ ,它比 Spring AOP 快很多
AspectJ 定义的通知类型有哪些
- Before(前置通知):目标对象的方法调用之前触发
- After (后置通知):目标对象的方法调用之后触发
- AfterReturning(返回通知):目标对象的方法调用完成,在返回结果值之后触发
- AfterThrowing(异常通知):目标对象的方法运行中抛出 / 触发异常后触发。AfterReturning 和 AfterThrowing 两者互斥。如果方法调用成功无异常,则会有返回值;如果方法抛出了异常,则不会有返回值。
- Around (环绕通知):编程式控制目标对象的方法调用。环绕通知是所有通知类型中可操作范围最大的一种,因为它可以直接拿到目标对象,以及要执行的方法,所以环绕通知可以任意的在目标对象的方法调用前后搞事,甚至不调用目标对象的方法
AspectJ 定义的通知类型有哪些
- Before(前置通知):目标对象的方法调用之前触发
- After (后置通知):目标对象的方法调用之后触发
- AfterReturning(返回通知):目标对象的方法调用完成,在返回结果值之后触发
- AfterThrowing(异常通知):目标对象的方法运行中抛出 / 触发异常后触发。AfterReturning 和 AfterThrowing 两者互斥。如果方法调用成功无异常,则会有返回值;如果方法抛出了异常,则不会有返回值。
- Around (环绕通知):编程式控制目标对象的方法调用。环绕通知是所有通知类型中可操作范围最大的一种,因为它可以直接拿到目标对象,以及要执行的方法,所以环绕通知可以任意的在目标对象的方法调用前后搞事,甚至不调用目标对象的方法
多个切面的执行顺序如何控制
-
通常使用
@Order注解直接定义切面顺序1 2 3 4 5 6
// 值越小优先级越高 @Order(3) @Component @Aspect public class LoggingAspect implements Ordered {
-
实现
Ordered接口重写getOrder方法1 2 3 4 5 6 7 8 9 10 11 12
@Component @Aspect public class LoggingAspect implements Ordered { // .... @Override public int getOrder() { // 返回值越小优先级越高 return 1; } }
Spring MVC
MVC 是模型(Model)、视图(View)、控制器(Controller)的简写,其核心思想是通过将业务逻辑、数据、显示分离来组织代码
MVC是一种设计模式,springMVC是一种MVC框架,帮助更简洁的开发,通常后端可以分为Service 层(处理业务)、Dao 层(数据库操作)、Entity 层(实体类)、Controller 层(控制层,返回数据给前台页面)
其核心组件有:
DispatcherServlet:核心的中央处理器,负责接收请求、分发,并给予客户端响应。HandlerMapping:处理器映射器,根据 URL 去匹配查找能处理的Handler,并会将请求涉及到的拦截器和Handler一起封装。HandlerAdapter:处理器适配器,根据HandlerMapping找到的Handler,适配执行对应的Handler;Handler:请求处理器,处理实际请求的处理器。ViewResolver:视图解析器,根据Handler返回的逻辑视图 / 视图,解析并渲染真正的视图,并传递给DispatcherServlet响应客户端
流程说明(重要):
- 客户端(浏览器)发送请求,
DispatcherServlet拦截请求。 DispatcherServlet根据请求信息调用HandlerMapping。HandlerMapping根据 URL 去匹配查找能处理的Handler(也就是我们平常说的Controller控制器) ,并会将请求涉及到的拦截器和Handler一起封装。DispatcherServlet调用HandlerAdapter适配器执行Handler。Handler完成对用户请求的处理后,会返回一个ModelAndView对象给DispatcherServlet,ModelAndView顾名思义,包含了数据模型以及相应的视图的信息。Model是返回的数据对象,View是个逻辑上的View。ViewResolver会根据逻辑View查找实际的View。DispaterServlet把返回的Model传给View(视图渲染)。- 把
View返回给请求者(浏览器)
统一异常处理怎么做
使用注解的方式统一异常处理,具体会使用到 @ControllerAdvice + @ExceptionHandler 这两个注解
1
2
3
4
5
6
7
8
9
10
11
12
13
14
@ControllerAdvice
@ResponseBody
public class GlobalExceptionHandler {
@ExceptionHandler(BaseException.class)
public ResponseEntity<?> handleAppException(BaseException ex, HttpServletRequest request) {
//......
}
@ExceptionHandler(value = ResourceNotFoundException.class)
public ResponseEntity<ErrorReponse> handleResourceNotFoundException(ResourceNotFoundException ex, HttpServletRequest request) {
//......
}
}
这种异常处理方式下,会给所有或者指定的 Controller 织入异常处理的逻辑(AOP),当 Controller 中的方法抛出异常的时候,由被@ExceptionHandler 注解修饰的方法进行处理。
ExceptionHandlerMethodResolver 中 getMappedMethod 方法决定了异常具体被哪个被 @ExceptionHandler 注解修饰的方法处理异常。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
@Nullable
private Method getMappedMethod(Class<? extends Throwable> exceptionType) {
List<Class<? extends Throwable>> matches = new ArrayList<>();
//找到可以处理的所有异常信息。mappedMethods 中存放了异常和处理异常的方法的对应关系
for (Class<? extends Throwable> mappedException : this.mappedMethods.keySet()) {
if (mappedException.isAssignableFrom(exceptionType)) {
matches.add(mappedException);
}
}
// 不为空说明有方法处理异常
if (!matches.isEmpty()) {
// 按照匹配程度从小到大排序
matches.sort(new ExceptionDepthComparator(exceptionType));
// 返回处理异常的方法
return this.mappedMethods.get(matches.get(0));
}
else {
return null;
}
}
Spring 事务
Spring 管理事务的方式有几种
-
编程式事务:在代码中硬编码(不推荐使用) : 通过
TransactionTemplate或者TransactionManager手动管理事务,实际应用中很少使用,但是对于你理解 Spring 事务管理原理有帮助。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
@Autowired private TransactionTemplate transactionTemplate; public void testTransaction() { transactionTemplate.execute(new TransactionCallbackWithoutResult() { @Override protected void doInTransactionWithoutResult(TransactionStatus transactionStatus) { try { // .... 业务代码 } catch (Exception e){ //回滚 transactionStatus.setRollbackOnly(); } } }); }
-
声明式事务:在 XML 配置文件中配置或者直接基于注解(推荐使用) : 实际是通过 AOP 实现(基于
@Transactional的全注解方式使用最多)1 2 3 4 5 6 7 8 9
@Transactional(propagation = Propagation.REQUIRED) public void aMethod { //do something B b = new B(); C c = new C(); b.bMethod(); c.cMethod(); }
事务的ACID特性
- 原子性:事务是最小的执行单位,不允许分割
- 隔离性:并发访问数据库时,一个事物不会受到其他事务的影响
- 一致性:执行事务前后,数据保持一致,比如转账,总金额是不变的
- 持久性:一个事务提交后,其对数据库的影响是永久的
事务的传播行为
事务传播行为是为了解决业务层方法之间互相调用的事务问题
举个例子:我们在 A 类的aMethod()方法中调用了 B 类的 bMethod() 方法。这个时候就涉及到业务层方法之间互相调用的事务问题。如果我们的 bMethod()如果发生异常需要回滚,如何配置事务传播行为才能让 aMethod()也跟着回滚呢?这个时候就需要事务传播行为的知识了,如果你不知道的话一定要好好看一下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
@Service
Class A {
@Autowired
B b;
@Transactional(propagation = Propagation.xxx)
public void aMethod {
//do something
b.bMethod();
}
}
@Service
Class B {
@Transactional(propagation = Propagation.xxx)
public void bMethod {
//do something
}
}
所以通过事务的传播属性来进行设置
在TransactionDefinition定义中包括了如下几个表示传播行为的常量:
1
2
3
4
5
6
7
8
9
10
11
public interface TransactionDefinition {
int PROPAGATION_REQUIRED = 0;
int PROPAGATION_SUPPORTS = 1;
int PROPAGATION_MANDATORY = 2;
int PROPAGATION_REQUIRES_NEW = 3;
int PROPAGATION_NOT_SUPPORTED = 4;
int PROPAGATION_NEVER = 5;
int PROPAGATION_NESTED = 6;
......
}
-
TransactionDefinition.PROPAGATION_REQUIRED如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务
-
如果外部方法没有开启事务的话,
Propagation.REQUIRED修饰的内部方法会新开启自己的事务,且开启的事务相互独立,互不干扰。 -
如果外部方法开启事务并且被
Propagation.REQUIRED的话,所有Propagation.REQUIRED修饰的内部方法和外部方法均属于同一事务 ,只要一个方法回滚,整个事务均回滚。
-
-
TransactionDefinition.PROPAGATION_REQUIRES_NEW创建一个新的事务,如果当前存在事务,则把当前事务挂起。也就是说不管外部方法是否开启事务,
Propagation.REQUIRES_NEW修饰的内部方法会新开启自己的事务,且开启的事务相互独立,互不干扰如果我们上面的
bMethod()使用PROPAGATION_REQUIRES_NEW事务传播行为修饰,aMethod还是用PROPAGATION_REQUIRED修饰的话。如果aMethod()发生异常回滚,bMethod()不会跟着回滚,因为bMethod()开启了独立的事务。但是,如果bMethod()抛出了未被捕获的异常并且这个异常满足事务回滚规则的话,aMethod()同样也会回滚,因为这个异常被aMethod()的事务管理机制检测到了。 -
TransactionDefinition.PROPAGATION_NESTED如果当前存在事务,就在嵌套事务内执行;如果当前没有事务,就执行与
TransactionDefinition.PROPAGATION_REQUIRED类似的操作。也就是说:- 在外部方法开启事务的情况下,在内部开启一个新的事务,作为嵌套事务存在。
- 如果外部方法无事务,则单独开启一个事务,与
PROPAGATION_REQUIRED类似。
如果
bMethod()回滚的话,aMethod()不会回滚。如果aMethod()回滚的话,bMethod()会回滚。 -
TransactionDefinition.PROPAGATION_MANDATORY如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常
事务的隔离级别
和事务传播行为这块一样,为了方便使用,Spring 也相应地定义了一个枚举类:Isolation
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
public enum Isolation {
DEFAULT(TransactionDefinition.ISOLATION_DEFAULT),
READ_UNCOMMITTED(TransactionDefinition.ISOLATION_READ_UNCOMMITTED),
READ_COMMITTED(TransactionDefinition.ISOLATION_READ_COMMITTED),
REPEATABLE_READ(TransactionDefinition.ISOLATION_REPEATABLE_READ),
SERIALIZABLE(TransactionDefinition.ISOLATION_SERIALIZABLE);
private final int value;
Isolation(int value) {
this.value = value;
}
public int value() {
return this.value;
}
}
TransactionDefinition.ISOLATION_DEFAULT:使用后端数据库默认的隔离级别,MySQL 默认采用的REPEATABLE_READ隔离级别 Oracle 默认采用的READ_COMMITTED隔离级别.TransactionDefinition.ISOLATION_READ_UNCOMMITTED:最低的隔离级别,使用这个隔离级别很少,因为它允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。脏读是指一个事务能读取另一个事务未提交的数据,这可能导致数据不一致TransactionDefinition.ISOLATION_READ_COMMITTED: 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。不可重复读是指在同一事务中,两次读取同一数据行返回不同的数据值,这通常是由于其他事务在这两次读取之间修改了数据。TransactionDefinition.ISOLATION_REPEATABLE_READ: 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。幻读是指当一个事务重新读取满足某个搜索条件的行时,会发现有其他事务插入或删除了额外的满足该条件的行。TransactionDefinition.ISOLATION_SERIALIZABLE: 最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
@Transactional(rollbackFor = Exception.class)注解
Exception 分为运行时异常 RuntimeException 和非运行时异常
当 @Transactional 注解作用于类上时,该类的所有 public 方法将都具有该类型的事务属性,同时,我们也可以在方法级别使用该标注来覆盖类级别的定义。如果类或者方法加了这个注解,那么这个类里面的方法抛出异常,就会回滚,数据库里面的数据也会回滚。
在 @Transactional 注解中如果不配置rollbackFor属性,那么事务只会在遇到RuntimeException的时候才会回滚,加上 rollbackFor=Exception.class,可以让事务在遇到非运行时异常时也回滚。
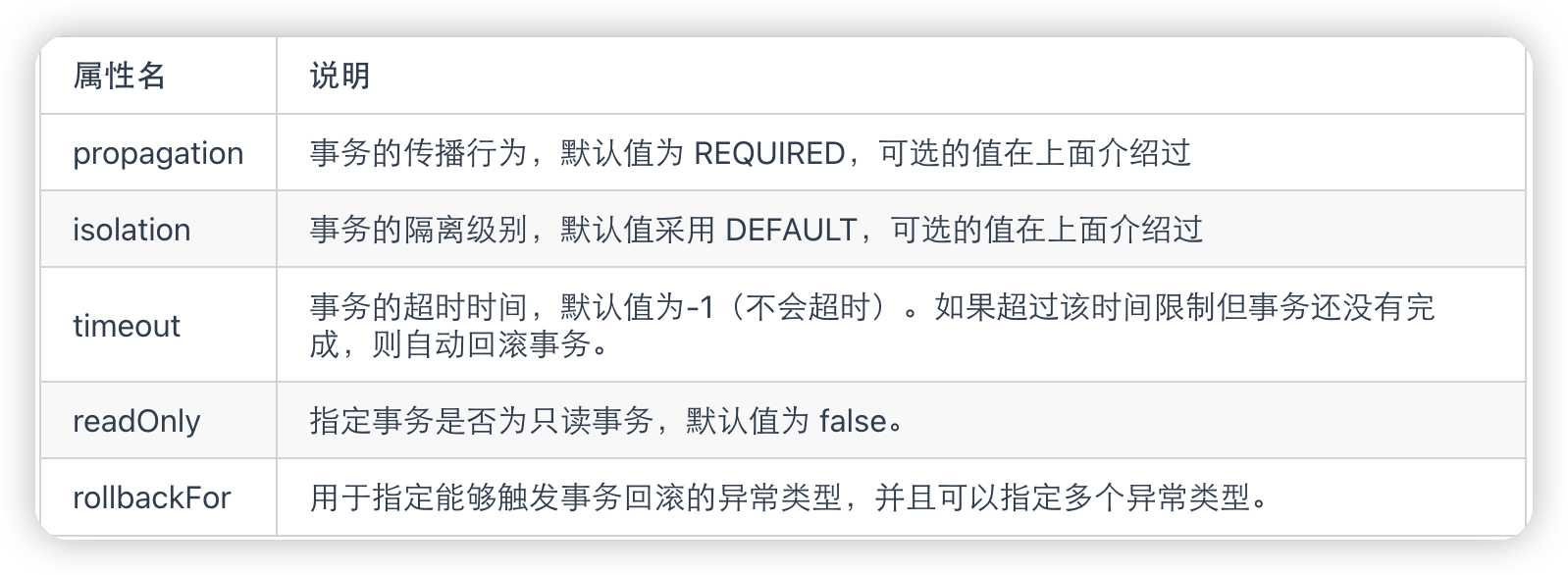
Spring Data JPA
JPA(Java Persistence API)是Java平台提供的一套规范,用于对象关系映射(ORM)。它定义了一种方式,使得Java开发者可以将对象映射到关系数据库中的表,从而实现了Java对象与数据库表之间的映射。JPA是Java EE和Jakarta EE平台的一部分,但也可以在Java SE环境中单独使用
1
2
3
4
5
6
7
8
9
10
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
private String name;
private String email;
// 省略构造函数、getter和setter方法
}
- 实体映射: JPA允许你通过使用注解(例如
@Entity,@Table,@Column)或XML配置来定义Java类与数据库表之间的映射。 - EntityManager: JPA中的
EntityManager是一个用于管理实体(例如查询、插入、更新、删除)的API。它也处理事务管理和实体的持久化。 - JPQL(Java Persistence Query Language): 一种独立于数据库的查询语言,类似于SQL,但是操作的是对象而不是表。
- 标准API: JPA提供了一套标准的API,这意味着你可以在不同的JPA实现之间切换而不需要重写代码。常见的JPA实现包括Hibernate, EclipseLink和OpenJPA。
- 缓存机制: JPA支持一级缓存和二级缓存,以提高应用程序性能。
- 自动化和简化数据库操作: JPA通过ORM技术简化了数据库操作,开发者无需编写大量的JDBC代码和手动处理结果集。
如何使用 JPA 在数据库中非持久化一个字段
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
@Entity(name="USER")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
@Column(name = "ID")
private Long id;
@Column(name="USER_NAME")
private String userName;
@Column(name="PASSWORD")
private String password;
private String secrect;
}
如果我们想让secrect 这个字段不被持久化,也就是不被数据库存储怎么办?我们可以采用下面几种方法:
1
2
3
4
5
static String transient1; // not persistent because of static
final String transient2 = "Satish"; // not persistent because of final
transient String transient3; // not persistent because of transient
@Transient
String transient4; // not persistent because of @Transient
JPA 的审计功能是做什么的
审计功能主要是帮助我们记录数据库操作的具体行为比如某条记录是谁创建的、什么时间创建的、最后修改人是谁、最后修改时间是什么时候
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
@Data
@AllArgsConstructor
@NoArgsConstructor
@MappedSuperclass
@EntityListeners(value = AuditingEntityListener.class)
public abstract class AbstractAuditBase {
@CreatedDate
@Column(updatable = false)
@JsonIgnore
private Instant createdAt;
@LastModifiedDate
@JsonIgnore
private Instant updatedAt;
@CreatedBy
@Column(updatable = false)
@JsonIgnore
private String createdBy;
@LastModifiedBy
@JsonIgnore
private String updatedBy;
}
Spring Security
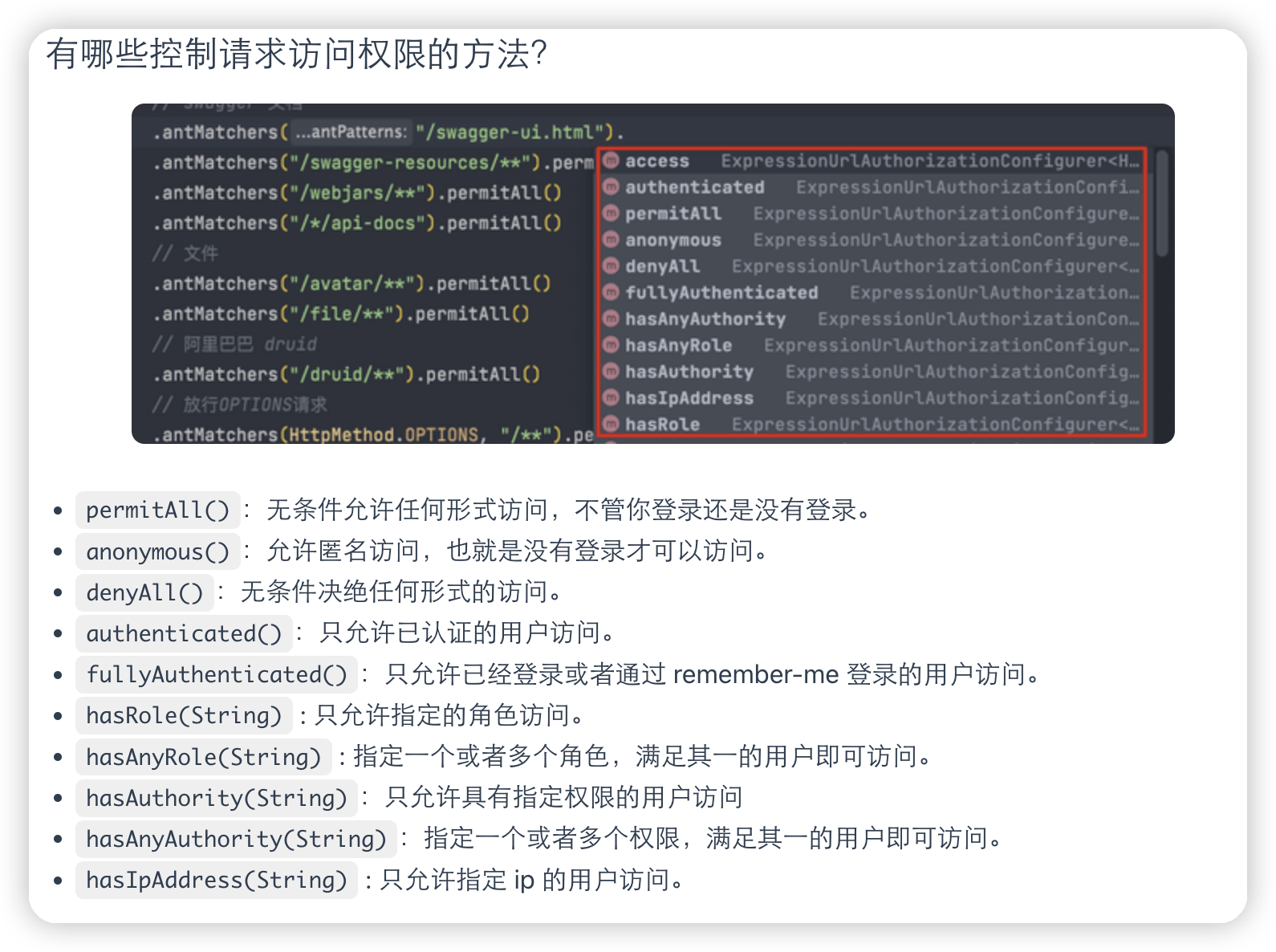
hasRole和hasAuthority的区别
hasRole:- 当你使用
hasRole('ROLE_XYZ')时,Spring Security会在内部实际上检查ROLE_XYZ权限。换句话说,它会自动为你提供的角色添加ROLE_前缀。这意味着如果你的角色存储在不带ROLE_前缀的数据库中,hasRole会自动添加这个前缀来进行匹配。 - 例如,如果你调用
hasRole('ADMIN'),Spring Security会查找ROLE_ADMIN权限。
- 当你使用
hasAuthority:hasAuthority不会自动添加任何前缀,它会精确匹配你所指定的字符串。如果你的权限或角色名称以特定方式存储(比如没有ROLE_前缀),你应该使用hasAuthority。- 例如,
hasAuthority('ROLE_ADMIN')和hasAuthority('ADMIN')会分别查找精确相同的字符串。
Spring&SpringBoot常用注解
@SpringBootApplication
可以把 @SpringBootApplication看作是 @Configuration、@EnableAutoConfiguration、@ComponentScan 注解的集合
@EnableAutoConfiguration:启用 SpringBoot 的自动配置机制@ComponentScan:扫描被@Component(@Repository,@Service,@Controller)注解的 bean,注解默认会扫描该类所在的包下所有的类。@Configuration:允许在 Spring 上下文中注册额外的 bean 或导入其他配置类
@Autowired
自动导入对象到类中,被注入进的类同样要被 Spring 容器管理比如:Service 类注入到 Controller 类中
1
2
3
4
5
6
7
8
9
10
11
12
13
@Service
public class UserService {
......
}
@RestController
@RequestMapping("/users")
public class UserController {
@Autowired
private UserService userService;
......
}
@Component,@Repository,@Service, @Controller
我们一般使用 @Autowired 注解让 Spring 容器帮我们自动装配 bean。要想把类标识成可用于 @Autowired 注解自动装配的 bean 的类,可以采用以下注解实现:
@Component:通用的注解,可标注任意类为Spring组件。如果一个 Bean 不知道属于哪个层,可以使用@Component注解标注。@Repository: 对应持久层即 Dao 层,主要用于数据库相关操作。@Service: 对应服务层,主要涉及一些复杂的逻辑,需要用到 Dao 层。@Controller: 对应 Spring MVC 控制层,主要用于接受用户请求并调用 Service 层返回数据给前端页面。
@RestController
@RestController注解是@Controller和@ResponseBody的合集,表示这是个控制器 bean,并且是将函数的返回值直接填入 HTTP 响应体中,是 REST 风格的控制器
单独使用 @Controller 不加 @ResponseBody的话一般是用在要返回一个视图的情况,这种情况属于比较传统的 Spring MVC 的应用,对应于前后端不分离的情况。@Controller +@ResponseBody 返回 JSON 或 XML 形式数据
@Scope
1
2
3
4
5
@Bean
@Scope("singleton")
public Person personSingleton() {
return new Person();
}
- singleton : 唯一 bean 实例,Spring 中的 bean 默认都是单例的。
- prototype : 每次请求都会创建一个新的 bean 实例。
- request : 每一次 HTTP 请求都会产生一个新的 bean,该 bean 仅在当前 HTTP request 内有效。
- session : 每一个 HTTP Session 会产生一个新的 bean,该 bean 仅在当前 HTTP session 内有效。
@Configuration
一般用来声明配置类,可以使用 @Component注解替代,不过使用@Configuration注解声明配置类更加语义化
1
2
3
4
5
6
7
8
@Configuration
public class AppConfig {
@Bean
public TransferService transferService() {
return new TransferServiceImpl();
}
}
前后端传值
@PathVariable 和 @RequestParam
@PathVariable用于获取路径参数,@RequestParam用于获取查询参数
@RequestBody
用于读取 Request 请求(可能是 POST,PUT,DELETE,GET 请求)的 body 部分并且Content-Type 为 application/json 格式的数据,接收到数据之后会自动将数据绑定到 Java 对象上去。系统会使用HttpMessageConverter或者自定义的HttpMessageConverter将请求的 body 中的 json 字符串转换为 java 对象。
读取配置信息
一般将一些常用的配置信息比如阿里云 oss、发送短信、微信认证的相关配置信息等等放到配置文件中。
使用注解进行读取
@Value
使用 @Value("${property}") 读取比较简单的配置信息
@ConfigurationProperties
通过@ConfigurationProperties读取配置信息并与 bean 绑定
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
@Component
@ConfigurationProperties(prefix = "library")
class LibraryProperties {
@NotEmpty
private String location;
private List<Book> books;
@Setter
@Getter
@ToString
static class Book {
String name;
String description;
}
省略getter/setter
......
}
接着就可以像使用普通的 Spring bean 一样,将其注入到类中使用
参数校验
即使在前端对数据进行校验的情况下,我们还是要对传入后端的数据再进行一遍校验,避免用户绕过浏览器直接通过一些 HTTP 工具直接向后端请求一些违法数据
JSR(Java Specification Requests) 是一套 JavaBean 参数校验的标准,它定义了很多常用的校验注解,我们可以直接将这些注解加在我们 JavaBean 的属性上面,这样就可以在需要校验的时候进行校验了
校验的时候我们实际用的是 Hibernate Validator 框架,SpringBoot 项目的 spring-boot-starter-web 依赖中已经有 hibernate-validator 包,不需要引用相关依赖
所有的注解,推荐使用 JSR 注解,即javax.validation.constraints,而不是org.hibernate.validator.constraints
一些常用的字段验证的注解

验证请求体
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Person {
@NotNull(message = "classId 不能为空")
private String classId;
@Size(max = 33)
@NotNull(message = "name 不能为空")
private String name;
@Pattern(regexp = "((^Man$|^Woman$|^UGM$))", message = "sex 值不在可选范围")
@NotNull(message = "sex 不能为空")
private String sex;
@Email(message = "email 格式不正确")
@NotNull(message = "email 不能为空")
private String email;
}
验证请求参数
1
2
3
4
5
6
7
8
9
10
@RestController
@RequestMapping("/api")
@Validated
public class PersonController {
@GetMapping("/person/{id}")
public ResponseEntity<Integer> getPersonByID(@Valid @PathVariable("id") @Max(value = 5,message = "超过 id 的范围了") Integer id) {
return ResponseEntity.ok().body(id);
}
}
全局处理 Controller 层异常
@ControllerAdvice:注解定义全局异常处理类@ExceptionHandler:注解声明异常处理方法
1
2
3
4
5
6
7
8
9
10
11
12
@ControllerAdvice
@ResponseBody
public class GlobalExceptionHandler {
/**
* 请求参数异常处理
*/
@ExceptionHandler(MethodArgumentNotValidException.class)
public ResponseEntity<?> handleMethodArgumentNotValidException(MethodArgumentNotValidException ex, HttpServletRequest request) {
......
}
}
json 数据处理
-
过滤 json 数据
@JsonIgnoreProperties作用在类上用于过滤掉特定字段不返回或者不解析1 2 3 4 5 6 7 8 9 10
//生成json时将userRoles属性过滤 @JsonIgnoreProperties({"userRoles"}) public class User { private String userName; private String fullName; private String password; private List<UserRole> userRoles = new ArrayList<>(); }
@JsonIgnore一般用于类的属性上,作用和上面的@JsonIgnoreProperties一样1 2 3 4 5 6 7 8 9 10
public class User { private String userName; private String fullName; private String password; //生成json时将userRoles属性过滤 @JsonIgnore private List<UserRole> userRoles = new ArrayList<>(); }
-
格式化 json 数据
@JsonFormat一般用来格式化 json 数据1 2 3
@JsonFormat(shape=JsonFormat.Shape.STRING, pattern="yyyy-MM-dd'T'HH:mm:ss.SSS'Z'", timezone="GMT") private Date date;
Spring Boot 的SpringApplication.run(xxx.class,args) 是怎么运行的
SpringApplication.run(xxx.class, args) 是Spring Boot应用程序启动的入口点,它封装了Spring应用启动时的一系列步骤。其工作原理可以分解为以下几个关键部分:
- 创建 SpringApplication 实例:
- 当你调用
SpringApplication.run(xxx.class, args)时,首先会创建一个SpringApplication的实例。这个实例是用来启动Spring应用的主要类。
- 当你调用
- 推断应用类型:
SpringApplication会根据类路径中的存在情况来推断应用类型(如是否是Web应用)。这决定了应用上下文是标准的还是针对Web的。
- 初始化应用上下文:
- 接下来,它会创建一个合适的
ApplicationContext实例。在Spring Boot中,这通常是一个AnnotationConfigApplicationContext或AnnotationConfigServletWebServerApplicationContext(对于Web应用)。
- 接下来,它会创建一个合适的
- 加载配置类:
SpringApplication会加载传递给run方法的配置类(例如xxx.class)。这些配置类通常使用@Configuration注解标记,它们定义了应用程序的配置。
- 设置环境:
- 它设置了Spring应用的环境。这涉及读取配置文件(比如
application.properties或application.yml)和解析命令行参数。
- 它设置了Spring应用的环境。这涉及读取配置文件(比如
- 执行自动配置:
- 自动配置是Spring Boot的核心特性,用于基于项目的类路径和定义的bean自动配置Spring应用。
SpringApplication会根据条件(如类路径上的库、Bean的定义等)触发自动配置。
- 自动配置是Spring Boot的核心特性,用于基于项目的类路径和定义的bean自动配置Spring应用。
- 刷新应用上下文:
- 接下来,
SpringApplication会刷新应用上下文,触发依赖注入过程,并执行任何声明的bean初始化方法。
- 接下来,
- 启动嵌入式Web服务器(如果是Web应用):
- 对于Web应用,Spring Boot会自动启动嵌入式Web服务器(如Tomcat、Jetty或Undertow)。
- 注册钩子并运行:
SpringApplication会注册JVM关闭钩子以确保优雅关闭,并调用任何CommandLineRunner或ApplicationRunnerbeans。
- 应用就绪:
- 最后,一旦应用上下文完全启动并且所有的服务都已就绪,应用就可以开始处理请求了。
SpringBoot 自动装配原理
SpringBoot 定义了一套接口规范,这套规范规定:SpringBoot 在启动时会扫描外部引用 jar 包中的META-INF/spring.factories文件,将文件中配置的类型信息加载到 Spring 容器(此处涉及到 JVM 类加载机制与 Spring 的容器知识),并执行类中定义的各种操作。对于外部 jar 来说,只需要按照 SpringBoot 定义的标准,就能将自己的功能装置进 SpringBoot。
实现原理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
<1.>@SpringBootConfiguration
<2.>@ComponentScan
<3.>@EnableAutoConfiguration
public @interface SpringBootApplication {
}
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Configuration //实际上它也是一个配置类
public @interface SpringBootConfiguration {
}
@EnableAutoConfiguration:启用 SpringBoot 的自动配置机制
@Configuration:允许在上下文中注册额外的 bean 或导入其他配置类
@ComponentScan:扫描被@Component (@Service,@Controller)注解的 bean,注解默认会扫描启动类所在的包下所有的类 ,可以自定义不扫描某些 bean。如下图所示,容器中将排除TypeExcludeFilter和AutoConfigurationExcludeFilter
由此可看出@EnableAutoConfiguration是实现自动装配的核心
@EnableAutoConfiguration
1
2
3
4
5
6
7
8
9
10
11
12
13
14
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@AutoConfigurationPackage //作用:将main包下的所有组件注册到容器中
@Import({AutoConfigurationImportSelector.class}) //加载自动装配类 xxxAutoconfiguration
public @interface EnableAutoConfiguration {
String ENABLED_OVERRIDE_PROPERTY = "spring.boot.enableautoconfiguration";
Class<?>[] exclude() default {};
String[] excludeName() default {};
}
由上面@EnableAutoConfiguration的源码可以看出AutoConfigurationImportSelector是实现自动装配的核心
AutoConfigurationImportSelector
该方法主要用于获取所有符合条件的类的全限定类名,这些类需要被加载到 IoC 容器中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
private static final String[] NO_IMPORTS = new String[0];
public String[] selectImports(AnnotationMetadata annotationMetadata) {
// <1>.判断自动装配开关是否打开
if (!this.isEnabled(annotationMetadata)) {
return NO_IMPORTS;
} else {
//<2>.获取所有需要装配的bean
AutoConfigurationMetadata autoConfigurationMetadata = AutoConfigurationMetadataLoader.loadMetadata(this.beanClassLoader);
AutoConfigurationImportSelector.AutoConfigurationEntry autoConfigurationEntry = this.getAutoConfigurationEntry(autoConfigurationMetadata, annotationMetadata);
return StringUtils.toStringArray(autoConfigurationEntry.getConfigurations());
}
}
其中getAutoConfigurationEntry方法主要负责加载自动配置类的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
private static final AutoConfigurationEntry EMPTY_ENTRY = new AutoConfigurationEntry();
AutoConfigurationEntry getAutoConfigurationEntry(AutoConfigurationMetadata autoConfigurationMetadata, AnnotationMetadata annotationMetadata) {
//<1>.判断自动装配开关是否打开
if (!this.isEnabled(annotationMetadata)) {
return EMPTY_ENTRY;
} else {
//<2>.用于获取`EnableAutoConfiguration`注解中的 `exclude` 和 `excludeName`
AnnotationAttributes attributes = this.getAttributes(annotationMetadata);
//<3>.获取需要自动装配的所有配置类,读取`META-INF/spring.factories`
List<String> configurations = this.getCandidateConfigurations(annotationMetadata, attributes);
//<4>.`@ConditionalOnXXX` 中的所有条件都满足,该类才会生效
configurations = this.removeDuplicates(configurations);
Set<String> exclusions = this.getExclusions(annotationMetadata, attributes);
this.checkExcludedClasses(configurations, exclusions);
configurations.removeAll(exclusions);
configurations = this.filter(configurations, autoConfigurationMetadata);
this.fireAutoConfigurationImportEvents(configurations, exclusions);
return new AutoConfigurationImportSelector.AutoConfigurationEntry(configurations, exclusions);
}
}
总结:
1、引入Starter组件
2、SpringBoot基于约定去Starter组件的路径下(META-INF/spring.factories)去找配置类
3、SpringBoot使用ImportSelector去导入这些配置类,并根据@Conditional动态加载配置类里面的Bean到容器
实现一个starter
-
创建
threadpool-spring-boot-starter工程 -
引入 Spring Boot 相关依赖
-
创建
ThreadPoolAutoConfiguration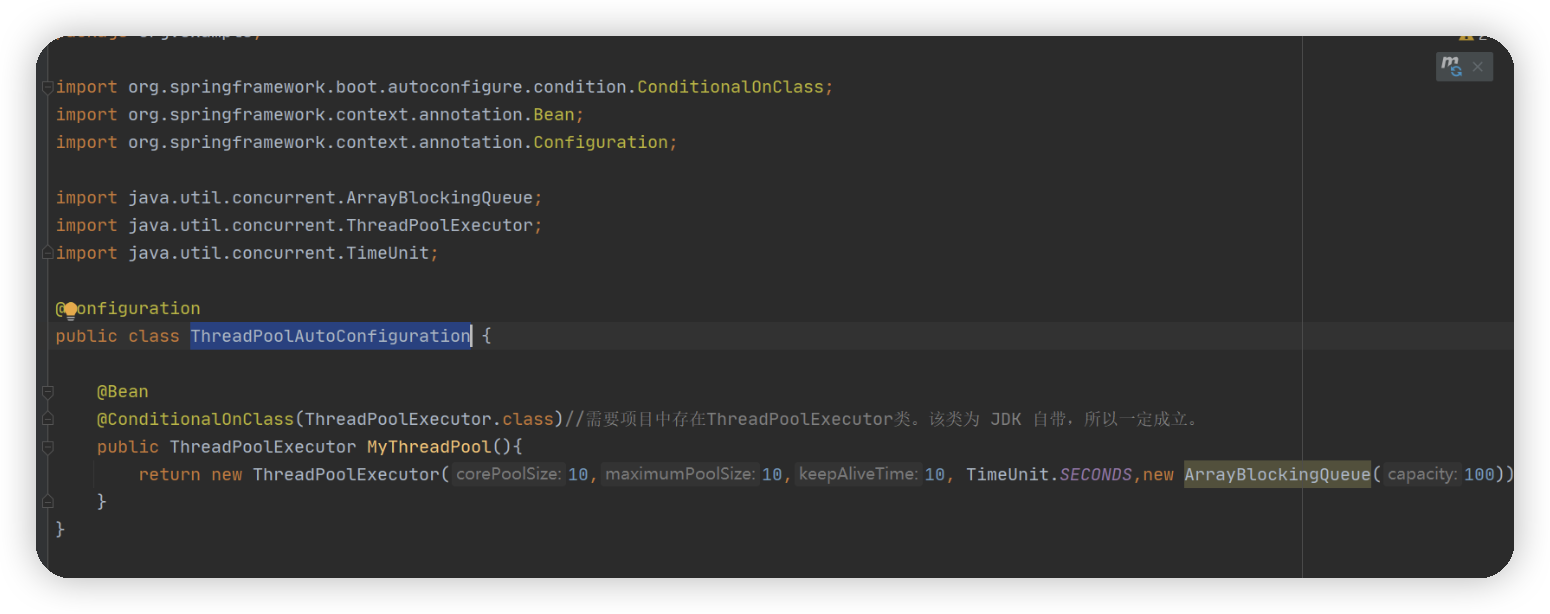
-
在
threadpool-spring-boot-starter工程的 resources 包下创建META-INF/spring.factories文件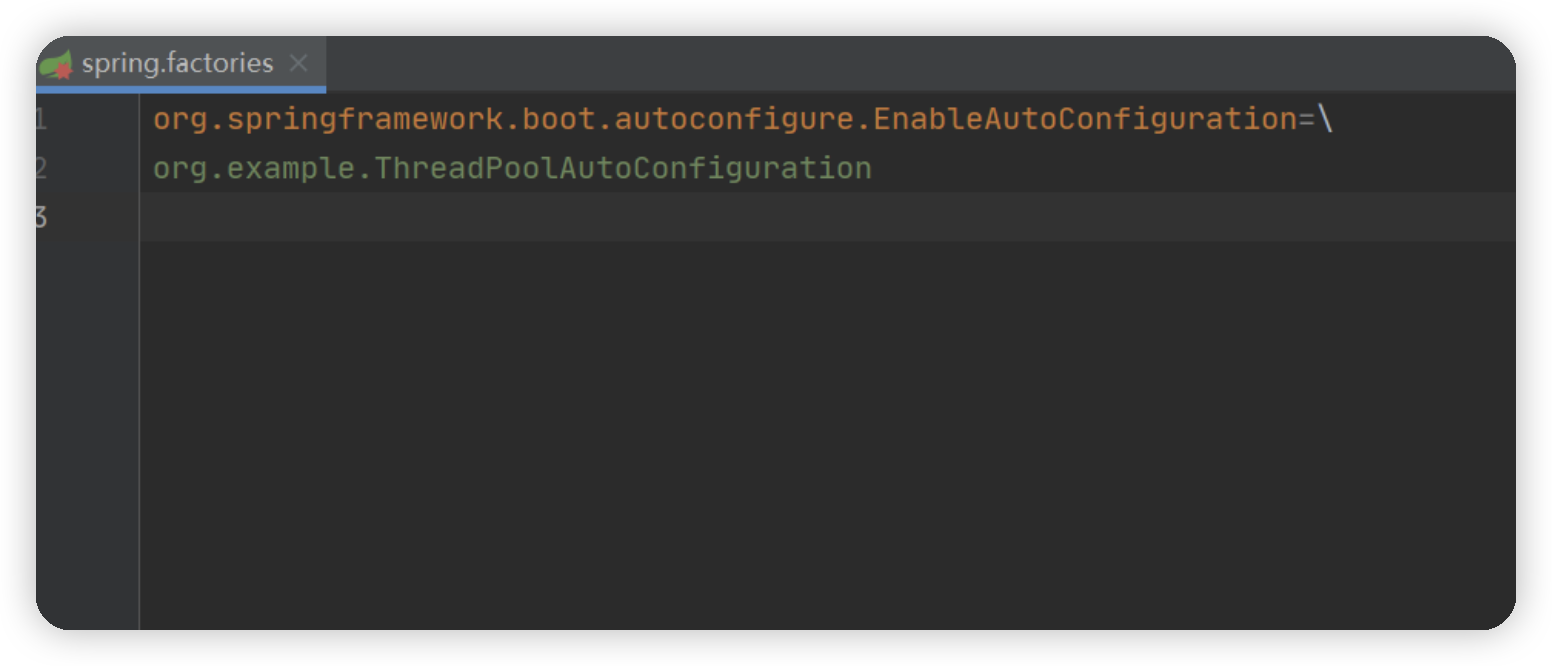
-
最后新建工程引入
threadpool-spring-boot-starter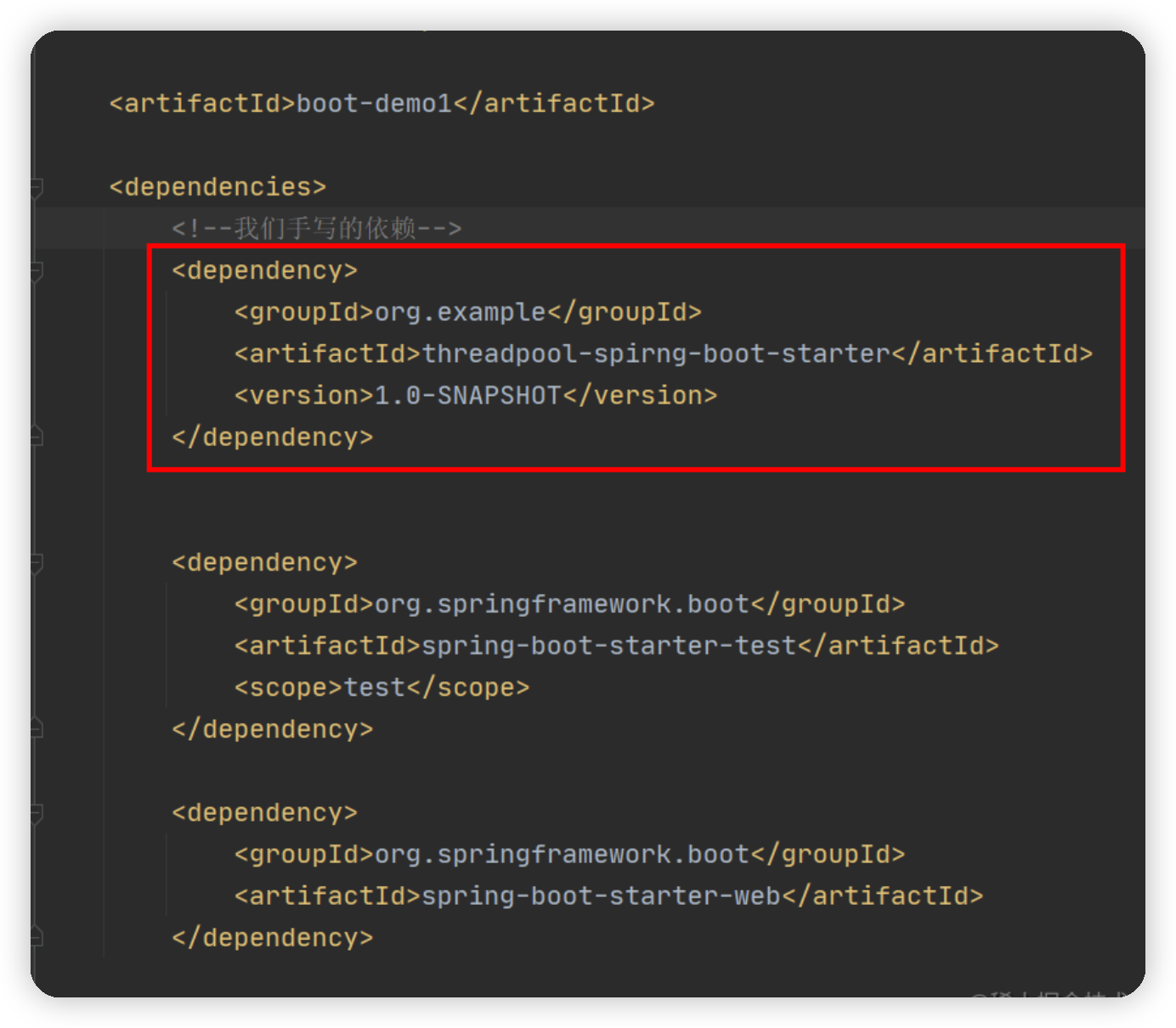
JVM
Java内存区域
运行时数据区域
Java 虚拟机在执行 Java 程序的过程中会把它管理的内存划分成若干个不同的数据区域
线程私有的:
- 程序计数器
- 虚拟机栈
- 本地方法栈
线程共享的:
- 堆
- 方法区
- 直接内存 (非运行时数据区的一部分)
程序计数器
程序计数器是一块较小的内存空间,可以看作是当前线程所执行的字节码的行号指示器,字节码解释器工作时通过改变这个计数器的值来选取下一条要执行的字节码指令。因此为了让每一个线程切换后都能恢复到正确执行的位置,每个线程都需要有一个独立的程序计数器,各个线程互不影响,独立存储。
程序计数器主要有两个作用:
-
字节码解释器通过改变程序计数器来依次读取指令,从而实现代码的流程控制,如:顺序执行、选择、循环、异常处理。
-
在多线程的情况下,程序计数器用于记录当前线程执行的位置,从而当线程被切换回来的时候能够知道该线程上次运行到哪儿了。
Java 虚拟机栈
与程序计数器一样,Java 虚拟机栈(后文简称栈)也是线程私有的,它的生命周期和线程相同,随着线程的创建而创建,随着线程的死亡而死亡
除了一些 Native 方法调用是通过本地方法栈实现的(后面会提到),其他所有的 Java 方法调用都是通过栈来实现的(也需要和其他运行时数据区域比如程序计数器配合)
方法调用的数据需要通过栈进行传递,每一次方法调用都会有一个对应的栈帧被压入栈中,每一个方法调用结束后,都会有一个栈帧被弹出
栈由一个个栈帧组成,而每个栈帧中都拥有:局部变量表、操作数栈、动态链接、方法返回地址。
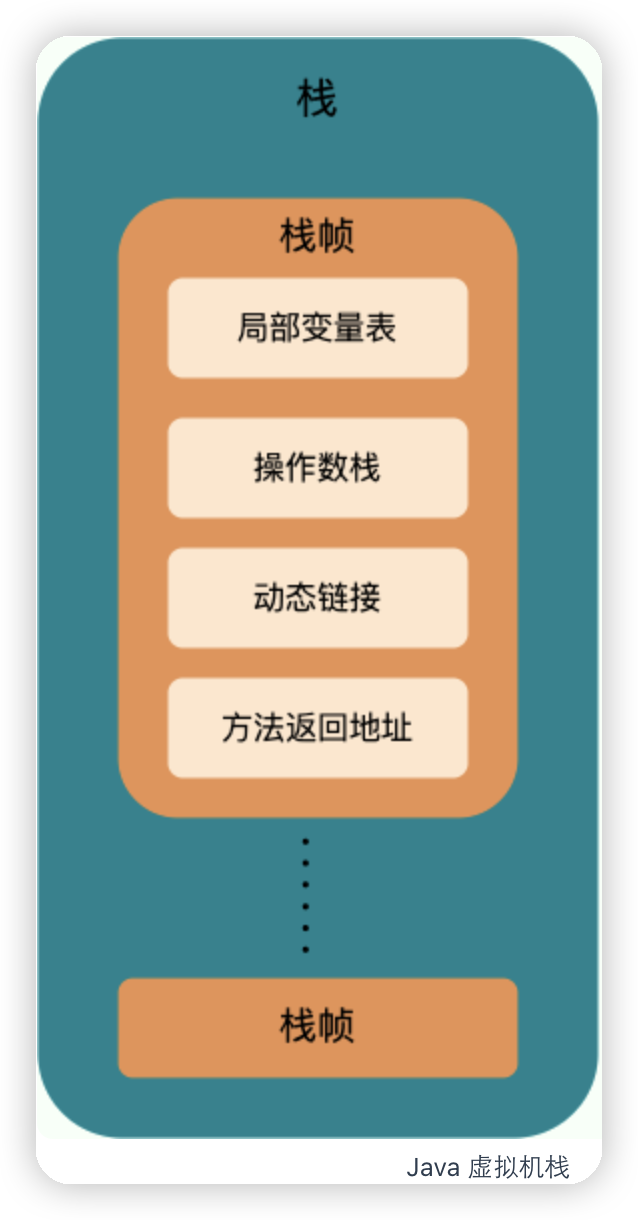
局部变量表 主要存放了编译期可知的各种数据类型(boolean、byte、char、short、int、float、long、double)、对象引用(reference 类型,它不同于对象本身,可能是一个指向对象起始地址的引用指针,也可能是指向一个代表对象的句柄或其他与此对象相关的位置)
操作数栈 主要作为方法调用的中转站使用,用于存放方法执行过程中产生的中间计算结果。另外,计算过程中产生的临时变量也会放在操作数栈中。
动态链接 主要服务一个方法需要调用其他方法的场景。Class 文件的常量池里保存有大量的符号引用比如方法引用的符号引用。当一个方法要调用其他方法,需要将常量池中指向方法的符号引用转化为其在内存地址中的直接引用。
动态链接的作用就是为了将符号引用转换为调用方法的直接引用,这个过程也被称为 动态连接 。
程序运行中栈可能会出现两种错误:
-
StackOverFlowError: 若栈的内存大小不允许动态扩展,那么当线程请求栈的深度超过当前 Java 虚拟机栈的最大深度的时候,就抛出StackOverFlowError错误。 -
OutOfMemoryError: 如果栈的内存大小可以动态扩展, 如果虚拟机在动态扩展栈时无法申请到足够的内存空间,则抛出OutOfMemoryError异常。
本地方法栈
和虚拟机栈所发挥的作用非常相似,区别是:虚拟机栈为虚拟机执行 Java 方法 (也就是字节码)服务,而本地方法栈则为虚拟机使用到的 Native 方法服务
本地方法被执行的时候,在本地方法栈也会创建一个栈帧,用于存放该本地方法的局部变量表、操作数栈、动态链接、出口信息
堆
Java 虚拟机所管理的内存中最大的一块,Java 堆是所有线程共享的一块内存区域,在虚拟机启动时创建。此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例以及数组都在这里分配内存
Java 堆是垃圾收集器管理的主要区域,因此也被称作 GC 堆(Garbage Collected Heap)
从垃圾回收的角度,由于现在收集器基本都采用分代垃圾收集算法,所以 Java 堆还可以细分为:新生代和老年代;再细致一点有:Eden、Survivor、Old 等空间。进一步划分的目的是更好地回收内存,或者更快地分配内存
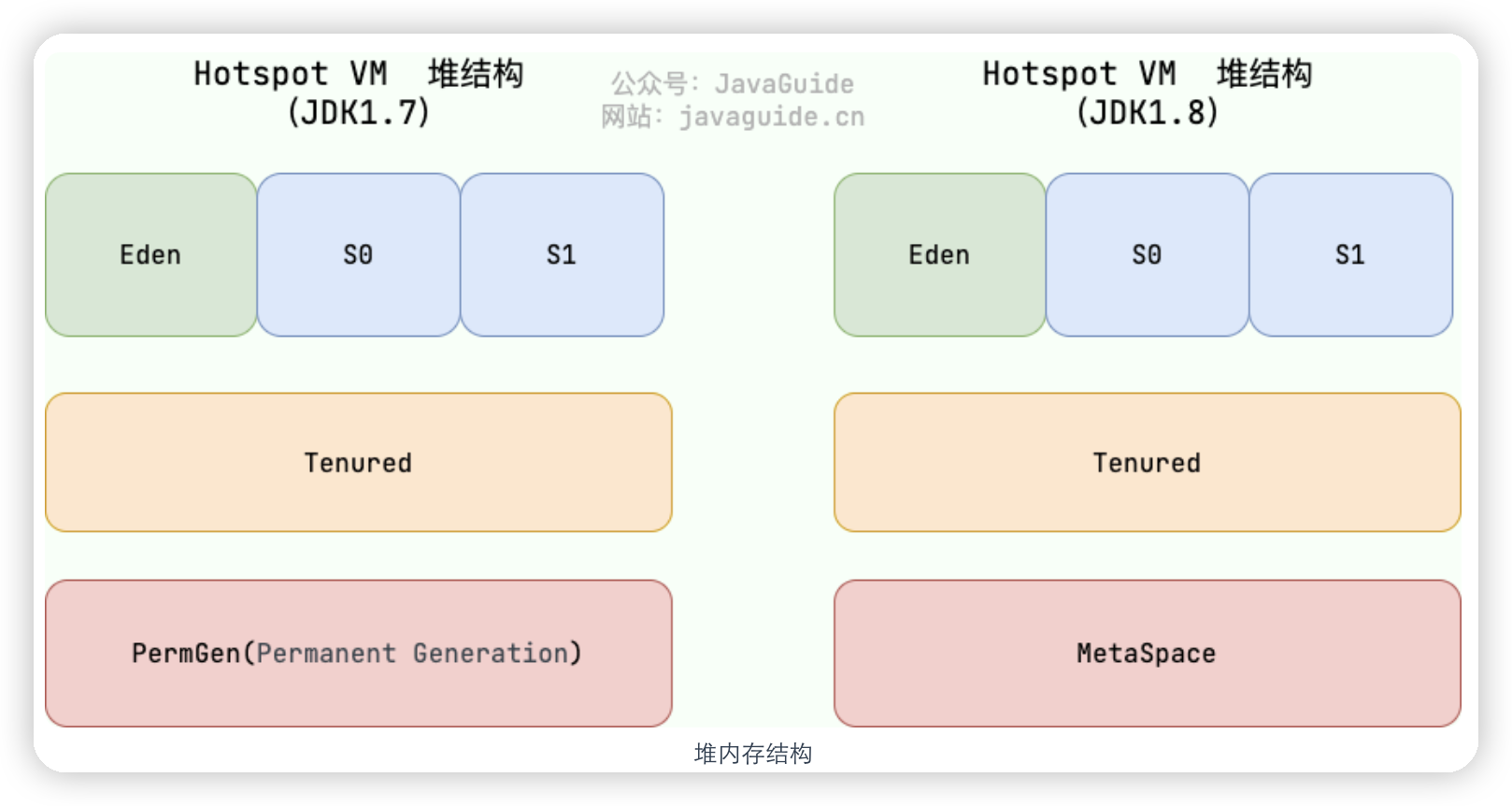
大部分情况,对象都会首先在 Eden 区域分配,在一次新生代垃圾回收后,如果对象还存活,则会进入 S0 或者 S1,并且对象的年龄还会加 1(Eden 区->Survivor 区后对象的初始年龄变为 1),当它的年龄增加到一定程度(默认为 15 岁),就会被晋升到老年代中。对象晋升到老年代的年龄阈值,可以通过参数 -XX:MaxTenuringThreshold 来设置
方法区
方法区属于是 JVM 运行时数据区域的一块逻辑区域,是各个线程共享的内存区域
当虚拟机要使用一个类时,它需要读取并解析 Class 文件获取相关信息,再将信息存入到方法区。方法区会存储已被虚拟机加载的 类信息、字段信息、方法信息、常量、静态变量、即时编译器编译后的代码缓存等数据
方法区和永久代以及元空间是什么关系呢?
永久代以及元空间是 HotSpot 虚拟机对虚拟机规范中方法区的两种实现方式。并且,永久代是 JDK 1.8 之前的方法区实现,JDK 1.8 及以后方法区的实现变成了元空间。
为什么要将永久代 (PermGen) 替换为元空间 (MetaSpace) 呢
- 元空间用的是本地内存,永久代是虚拟机设置的一个固定大小,元空间造成内存溢出的可能性更小
- 在 JDK8,合并 HotSpot 和 JRockit 的代码时, JRockit 从来没有一个叫永久代的东西, 合并之后就没有必要额外的设置这么一个永久代的地方了
但与永久代很大的不同就是,如果不指定大小的话,随着更多类的创建,虚拟机会耗尽所有可用的系统内存。
1
2
-XX:MetaspaceSize=N //设置 Metaspace 的初始(和最小大小)
-XX:MaxMetaspaceSize=N //设置 Metaspace 的最大大小
元空间用的是本地内存,堆用的是虚拟机内存,这个时候这两者就是独立分开了的
运行时常量池
Class 文件中除了有类的版本、字段、方法、接口等描述信息外,还有用于存放编译期生成的各种字面量(Literal)和符号引用(Symbolic Reference)的 常量池表(Constant Pool Table) 。
字符串常量池
在jkd1.8之前是存放在方法区中,此时方法区的实现是永久代,后来弃用永久代之后,存放在堆中
字符串常量池 是 JVM 为了提升性能和减少内存消耗针对字符串(String 类)专门开辟的一块区域,主要目的是为了避免字符串的重复创建
1
2
3
4
5
6
// 在堆中创建字符串对象”ab“
// 将字符串对象”ab“的引用保存在字符串常量池中
String aa = "ab";
// 直接返回字符串常量池中字符串对象”ab“的引用
String bb = "ab";
System.out.println(aa==bb);// true
HotSpot 虚拟机中字符串常量池的实现是可以简单理解为一个固定大小的HashTable ,容量为 StringTableSize(可以通过 -XX:StringTableSize 参数来设置),保存的是字符串(key)和 字符串对象的引用(value)的映射关系,字符串对象的引用指向堆中的字符串对象。
在JDK1.7之前字符串常量池存放在永久代,JDK1.7 字符串常量池和静态变量从永久代移动了 Java 堆中,这是因为永久代(方法区实现)的 GC 回收效率太低,只有在整堆收集 (Full GC)的时候才会被执行 GC。Java 程序中通常会有大量的被创建的字符串等待回收,将字符串常量池放到堆中,能够更高效及时地回收字符串内存
直接内存
直接内存是一种特殊的内存缓冲区,并不在 Java 堆或方法区中分配的,而是通过 JNI 的方式在本地内存上分配的。
HotSpot虚拟机对象探秘
对象的创建
-
类加载检查
虚拟机遇到一条new指令,首先将去检查这个指令的参数是否能在常量池中定位到这个类的符号引用,并且检查这个符号引用代表的类是否已被加载过、解析和初始化过。如果没有,那必须先执行相应的类加载过程
-
分配内存
在类加载检查通过后,接下来虚拟机将为新生对象分配内存。对象所需的内存大小在类加载完成后便可确定,为对象分配空间的任务等同于把一块确定大小的内存从 Java 堆中划分出来。
分配方式有 “指针碰撞” 和 “空闲列表” 两种,选择哪种分配方式由 Java 堆是否规整决定,而 Java 堆是否规整又由所采用的垃圾收集器是否带有压缩整理功能决定。
内存分配方式
指针碰撞:
- 适用场合:堆内存规整(即没有内存碎片)的情况下。
- 原理:用过的内存全部整合到一边,没有用过的内存放在另一边,中间有一个分界指针,只需要向着没用过的内存方向将该指针移动对象内存大小位置即可。
- 使用该分配方式的 GC 收集器:Serial, ParNew
空闲列表:
- 适用场合:堆内存不规整的情况下。
- 原理:虚拟机会维护一个列表,该列表中会记录哪些内存块是可用的,在分配的时候,找一块儿足够大的内存块儿来划分给对象实例,最后更新列表记录。
- 使用该分配方式的 GC 收集器:CMS
不过在并发的情况下,需要考虑线程安全问题,通常考虑下面两种方式
CAS+失败重试: CAS 是乐观锁的一种实现方式。所谓乐观锁就是,每次不加锁而是假设没有冲突而去完成某项操作,如果因为冲突失败就重试,直到成功为止。虚拟机采用 CAS 配上失败重试的方式保证更新操作的原子性。
TLAB: 为每一个线程预先在 Eden 区分配一块儿内存,JVM 在给线程中的对象分配内存时,首先在 TLAB 分配,当对象大于 TLAB 中的剩余内存或 TLAB 的内存已用尽时,再采用上述的 CAS 进行内存分配
-
初始化零值
内存分配完成后,虚拟机需要将分配到的内存空间初始为零值,这一步操作保证了对象实例字段在java代码中不赋值就直接使用,程序能访问到这些字段的数据类型所对应的零值。
-
设置对象头
初始化之后,虚拟机就需要对对象进行必要的设置,例如这个对象是哪个类的实例、如何才能找到类的元数据信息、对象的哈希码、对象的 GC 分代年龄等信息。 这些信息存放在对象头中
-
执行init方法
上述工作都完成后,从虚拟机的视角来看,一个新的对象已经产生了,但从 Java 程序的视角来看,对象创建才刚开始,
<init>方法还没有执行,所有的字段都还为零。所以一般来说,执行 new 指令之后会接着执行<init>方法,把对象按照程序员的意愿进行初始化,这样一个真正可用的对象才算完全产生出来
对象的内存布局
对象在内存中的布局可以分为 3 块区域:对象头、实例数据和对齐填充
-
Hotspot 虚拟机的对象头包括两部分信息,第一部分用于存储对象自身的运行时数据(哈希码、GC 分代年龄、锁状态标志等等),另一部分是类型指针,即对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。
-
实例数据部分是对象真正存储的有效信息,也是在程序中所定义的各种类型的字段内容。
-
对齐填充部分不是必然存在的,也没有什么特别的含义,仅仅起占位作用。 因为 Hotspot 虚拟机的自动内存管理系统要求对象起始地址必须是 8 字节的整数倍,换句话说就是对象的大小必须是 8 字节的整数倍。而对象头部分正好是 8 字节的倍数(1 倍或 2 倍),因此,当对象实例数据部分没有对齐时,就需要通过对齐填充来补全。
对象的访问定位
通过栈上的 reference 数据来操作堆上的具体对象。对象的访问方式由虚拟机实现而定,目前主流的访问方式有:使用句柄、直接指针
句柄
那么 Java 堆中将会划分出一块内存来作为句柄池,reference 中存储的就是对象的句柄地址,而句柄中包含了对象实例数据与对象类型数据各自的具体地址信息。
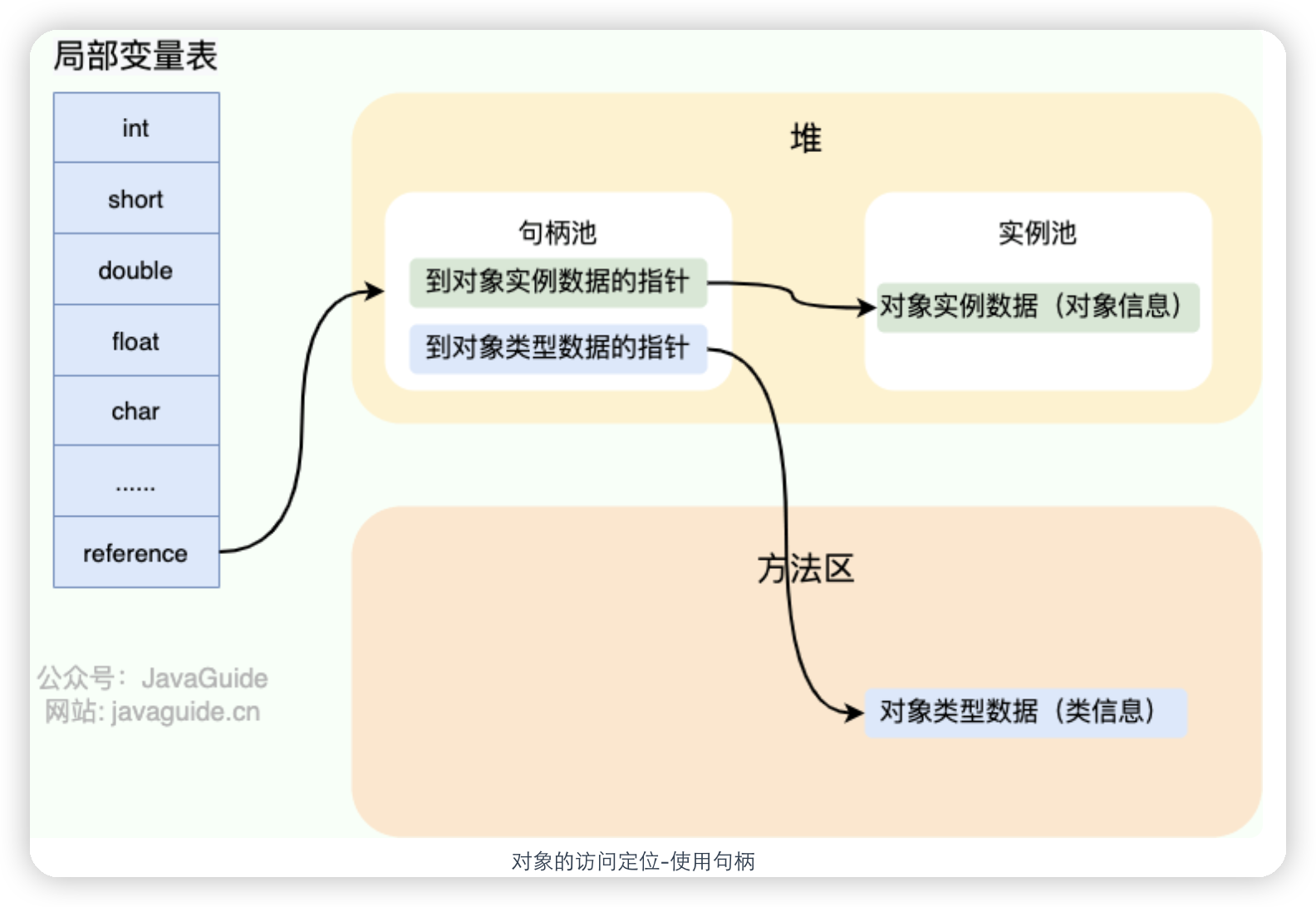
直接指针
如果使用直接指针访问,reference 中存储的直接就是对象的地址
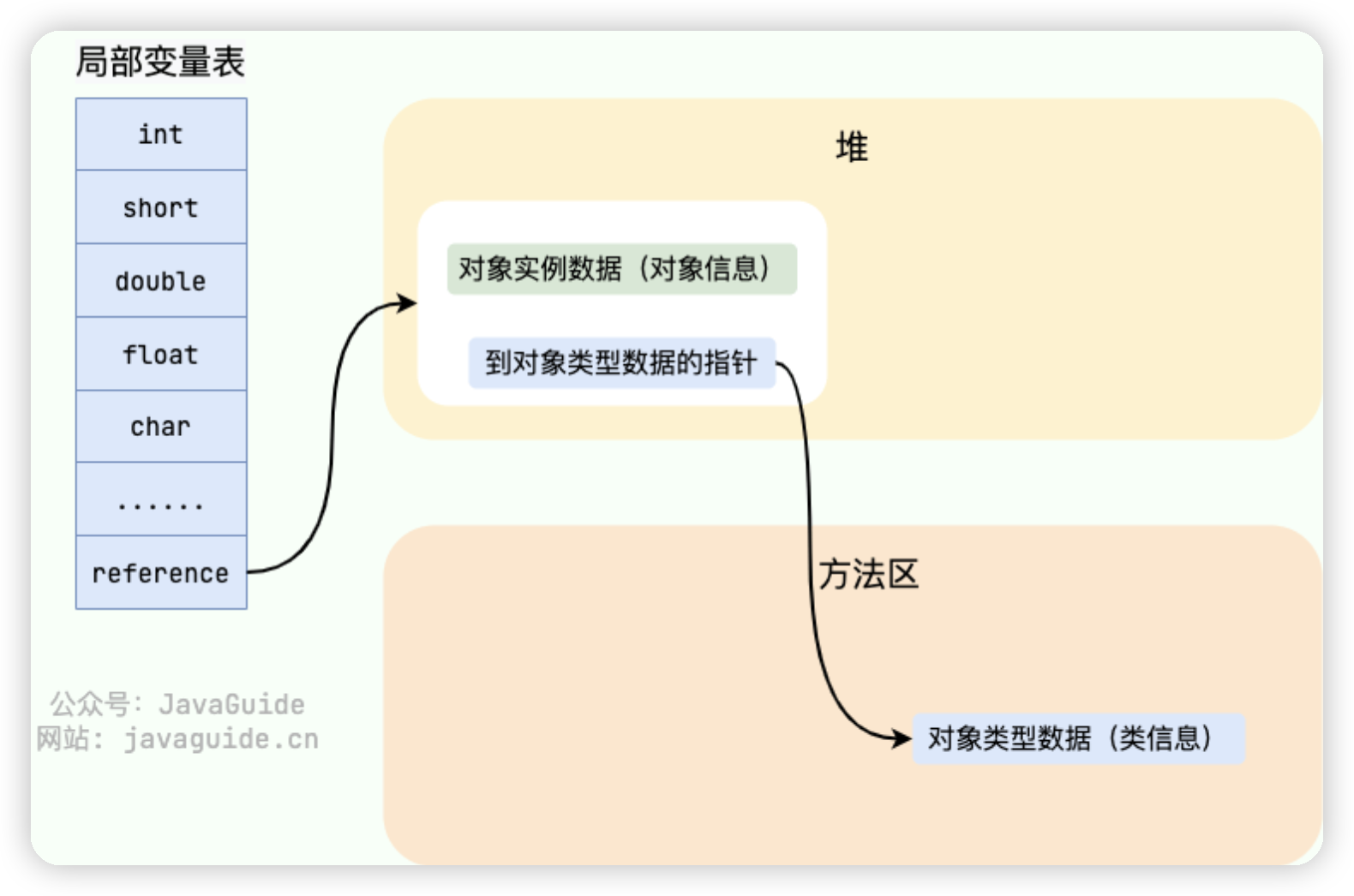
JVM垃圾回收
堆空间的基本结构
java的自动内存管理主要针对对象内存回收和对象内存分配,java自动内存管理最核心的功能是堆内存中对象的分配和回收
java堆是垃圾收集器主要管理区域,因此也叫做GC堆
由于现在收集器基本都采用分代垃圾收集算法,所以java堆可以分为几个不同的区域,每个区域行驶不同的功能
内存分配和回收规则
对象优先在Eden区分配
大多数情况下,对象在新生代中 Eden 区分配。
当 Eden 区没有足够空间进行分配时,虚拟机将发起一次 Minor GC,将新生代对象转移到老年代中,老年代中空间足够存放 allocation1,所以不会出现 Full GC
大对象直接进入老年代
大对象直接进入老年代的行为是由虚拟机动态决定的,它与具体使用的垃圾回收器和相关参数有关。大对象直接进入老年代是一种优化策略,旨在避免将大对象放入新生代,从而减少新生代的垃圾回收频率和成本。
-
G1 垃圾回收器会根据
-XX:G1HeapRegionSize参数设置的堆区域大小和-XX:G1MixedGCLiveThresholdPercent参数设置的阈值,来决定哪些对象会直接进入老年代。 -
Parallel Scavenge 垃圾回收器中,默认情况下,并没有一个固定的阈值(
XX:ThresholdTolerance是动态调整的)来决定何时直接在老年代分配大对象。而是由虚拟机根据当前的堆内存情况和历史数据动态决定
长期存活的对象将进入老年代
既然虚拟机采用了分代收集的思想来管理内存,那么内存回收时就必须能识别哪些对象应放在新生代,哪些对象应放在老年代中
大部分情况下,对象首先在Eden区域中分配,如果对象在Eden出生并经过第一次Minor GC后仍能存活,并且能被 Survivor 容纳的话,将被移动到 Survivor 空间(s0 或者 s1)中,并将对象年龄设为 1(Eden 区->Survivor 区后对象的初始年龄变为 1)
对象在 Survivor 中每熬过一次 MinorGC,年龄就增加 1 岁,当它的年龄增加到一定程度(默认为 15 岁),就会被晋升到老年代中。对象晋升到老年代的年龄阈值,可以通过参数 -XX:MaxTenuringThreshold 来设置
主要进行 gc 的区域

空间分配担保
空间分配担保是为了确保在 Minor GC 之前老年代本身还有容纳新生代所有对象的剩余空间
死亡对象判断方法
堆中几乎放着所有的对象实例,对堆垃圾回收前的第一步就是要判断哪些对象已经死亡(即不能再被任何途径使用的对象)
引用计数法
给对象中添加一个引用计数器:
- 每当有一个地方引用它,计数器就加 1;
- 当引用失效,计数器就减 1;
- 任何时候计数器为 0 的对象就是不可能再被使用的
这种方式简单,但其最主要的原因是它很难解决对象之间循环引用的问题。
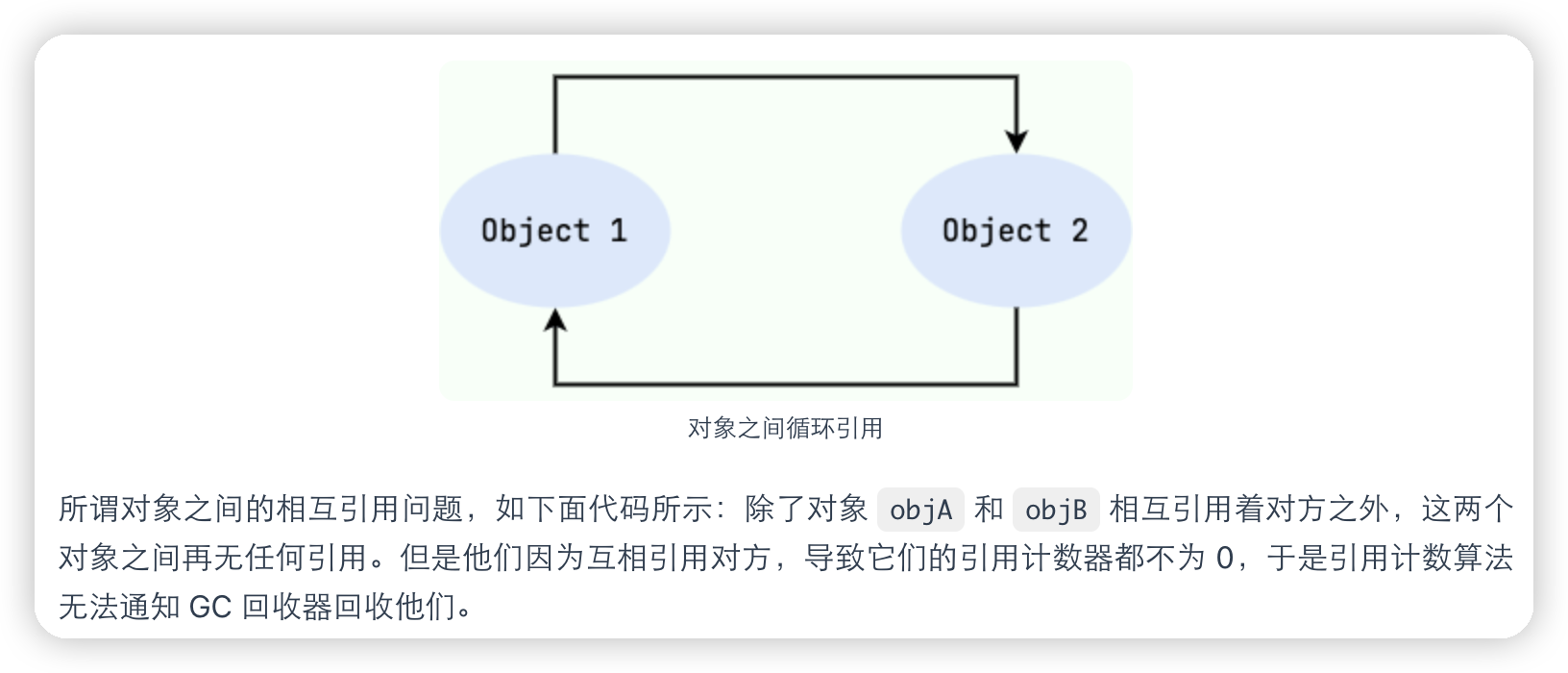
可达性分析算法
这个算法的基本思想就是通过一系列的称为 “GC Roots” 的对象作为起点,从这些节点开始向下搜索,节点所走过的路径称为引用链,当一个对象到 GC Roots 没有任何引用链相连的话,则证明此对象是不可用的,需要被回收
哪些对象能作为GC Roots呢
-
虚拟机栈(栈帧中的局部变量表)中引用的对象
-
本地方法栈(Native 方法)中引用的对象
-
方法区中类静态属性引用的对象
-
方法区中常量引用的对象
-
所有被同步锁持有的对象
-
JNI(Java Native Interface)引用的对象
对象可以被回收,就代表一定会被回收吗
在可达性分析算法中不可达的对象,也不是一定会被回收,要真正宣告一个对象死亡,至少要经历两次标记过程,可达性分析法中不可达的对象被第一次标记并进行了一次筛选,筛选的条件是此对象是否有必要执行 finalize 方法。当对象没有覆盖 finalize 方法,或 finalize 方法已经被虚拟机调用过时,虚拟机将这两种情况视为没有必要执行。

被判定为需要执行的对象将会被放在一个队列中进行第二次标记,除非这个对象与引用链上的任何一个对象建立关联,否则就会被真的回收。
引用类型总结

虚引用主要用来跟踪对象被垃圾回收的活动
虚引用与软引用和弱引用的一个区别在于: 虚引用必须和引用队列(ReferenceQueue)联合使用。当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之关联的引用队列中。程序可以通过判断引用队列中是否已经加入了虚引用,来了解被引用的对象是否将要被垃圾回收。程序如果发现某个虚引用已经被加入到引用队列,那么就可以在所引用的对象的内存被回收之前采取必要的行动。
如何判断一个常量是废弃常量
-
JDK1.7 之前运行时常量池逻辑包含字符串常量池存放在方法区, 此时 hotspot 虚拟机对方法区的实现为永久代
-
JDK1.7 字符串常量池被从方法区拿到了堆中, 这里没有提到运行时常量池,也就是说字符串常量池被单独拿到堆,运行时常量池剩下的东西还在方法区, 也就是 hotspot 中的永久代 。
-
JDK1.8 hotspot 移除了永久代用元空间(Metaspace)取而代之, 这时候字符串常量池还在堆, 运行时常量池还在方法区, 只不过方法区的实现从永久代变成了元空间(Metaspace)
假如在字符串常量池中存在字符串 “abc”,如果当前没有任何 String 对象引用该字符串常量的话,就说明常量 “abc” 就是废弃常量,如果这时发生内存回收的话而且有必要的话
如何判断一个类是无用类
类信息是存储在方法区中,类的实例化对象是存储在堆中
满足下面三个条件就是无用类:
-
该类所有的实例都已经被回收,也就是 Java 堆中不存在该类的任何实例。
-
加载该类的
ClassLoader已经被回收。 -
该类对应的
java.lang.Class对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法
垃圾收集算法
标记-清除算法
首先标记出所有不需要回收的对象,在标记完成后统一回收掉所有没有被标记的对象。
- 效率问题:标记和清除两个过程效率都不高。
- 空间问题:标记清除后会产生大量不连续的内存碎片。
复制算法
为了解决标记-清除算法的效率和内存碎片问题,复制(Copying)收集算法出现了。它可以将内存分为大小相同的两块,每次使用其中的一块。当这一块的内存使用完后,就将还存活的对象复制到另一块去,然后再把使用的空间一次清理掉。这样就使每次的内存回收都是对内存区间的一半进行回收。
但也存在下面问题:
- 可用内存变小:可用内存缩小为原来的一半。
- 不适合老年代:如果存活对象数量比较大,复制性能会变得很差。
标记-整理算法
思路和标记-清除类似,标记之后,将有用的对象放到内存的一端,然后对其他的所有空间进行清除
分代收集算法
根据对象存活周期的不同将内存分为几块。一般将 Java 堆分为新生代和老年代,这样我们就可以根据各个年代的特点选择合适的垃圾收集算法。
比如在新生代中,每次收集都会有大量对象死去,所以可以选择”标记-复制“算法,只需要付出少量对象的复制成本就可以完成每次垃圾收集。而老年代的对象存活几率是比较高的,而且没有额外的空间对它进行分配担保,所以我们必须选择“标记-清除”或“标记-整理”算法进行垃圾收集
所以这也可以看作分成新生代,老年代的原因
垃圾收集器
如果说收集算法是内存回收的方法论,那么垃圾收集器就是内存回收的具体实现
根据具体应用场景选择适合自己的垃圾收集器

Serial 收集器
Serial(串行)收集器是最基本、历史最悠久的垃圾收集器了。大家看名字就知道这个收集器是一个单线程收集器了。
它的 “单线程” 的意义不仅仅意味着它只会使用一条垃圾收集线程去完成垃圾收集工作,更重要的是它在进行垃圾收集工作的时候必须暂停其他所有的工作线程( “Stop The World” ),直到它收集结束。
ParNew收集器
ParNew 收集器其实就是 Serial 收集器的多线程版本,除了使用多线程进行垃圾收集外,其余行为(控制参数、收集算法、回收策略等等)和 Serial 收集器完全一样
Parallel Scavenge收集器
Parallel Scavenge 收集器也是使用标记-复制算法的多线程收集器,它看上去几乎和 ParNew 都一样。 那么它有什么特别之处呢?
1
2
3
4
5
6
7
8
-XX:+UseParallelGC
使用 Parallel 收集器+ 老年代串行
-XX:+UseParallelOldGC
使用 Parallel 收集器+ 老年代并行
Parallel Scavenge 收集器关注点是吞吐量(高效率的利用 CPU),所谓吞吐量就是 CPU 中用于运行用户代码的时间与 CPU 总消耗时间的比值
Parallel Scavenge 收集器提供了很多参数供用户找到最合适的停顿时间或最大吞吐量
Serial Old收集器
Serial 收集器的老年代版本,它同样是一个单线程收集器。它主要有两大用途:一种用途是在 JDK1.5 以及以前的版本中与 Parallel Scavenge 收集器搭配使用,另一种用途是作为 CMS 收集器的后备方案。
Parallel Old收集器
Parallel Scavenge 收集器的老年代版本。使用多线程和“标记-整理”算法。在注重吞吐量以及 CPU 资源的场合,都可以优先考虑 Parallel Scavenge 收集器和 Parallel Old 收集器。
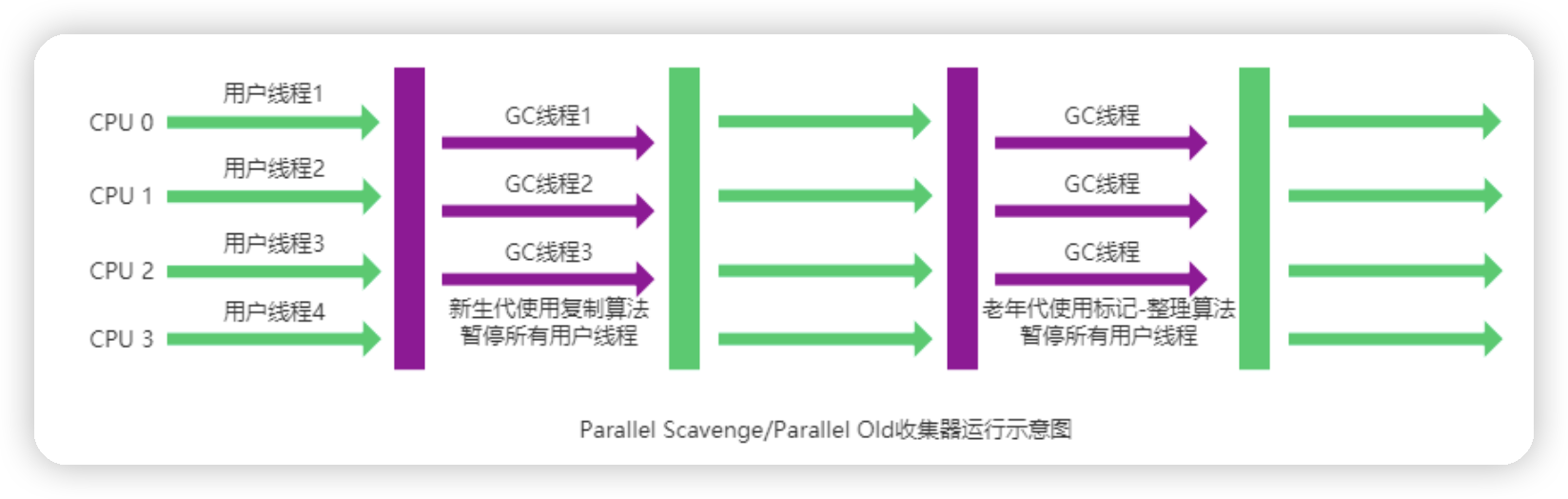
CMS收集器
CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。它非常符合在注重用户体验的应用上使用。
CMS(Concurrent Mark Sweep)收集器是 HotSpot 虚拟机第一款真正意义上的并发收集器,它第一次实现了让垃圾收集线程与用户线程(基本上)同时工作
整个过程分为以下四个步骤:
-
初始标记: 暂停所有的其他线程,并记录下直接与 root 相连的对象,速度很快 ;
-
并发标记: 同时开启 GC 和用户线程,用一个闭包结构去记录可达对象。但在这个阶段结束,这个闭包结构并不能保证包含当前所有的可达对象。因为用户线程可能会不断的更新引用域,所以 GC 线程无法保证可达性分析的实时性。所以这个算法里会跟踪记录这些发生引用更新的地方。
-
重新标记: 重新标记阶段就是为了修正并发标记期间因为用户程序继续运行而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间一般会比初始标记阶段的时间稍长,远远比并发标记阶段时间短
-
并发清除: 开启用户线程,同时 GC 线程开始对未标记的区域做清扫。
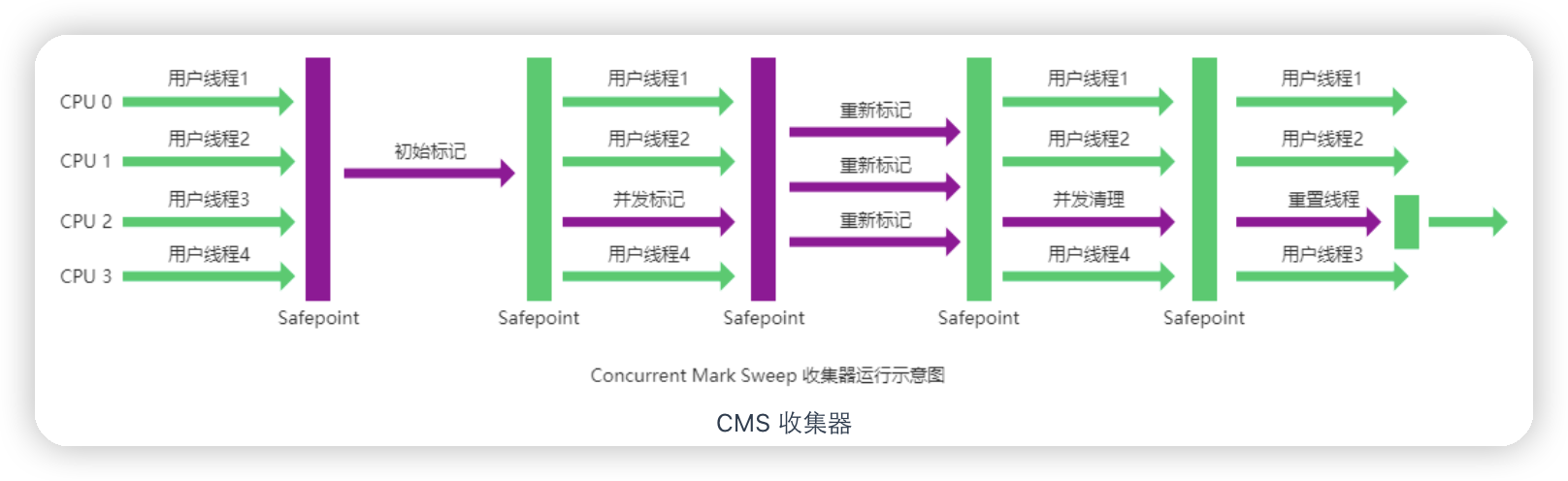
从它的名字就可以看出它是一款优秀的垃圾收集器,主要优点:并发收集、低停顿。但是它有下面三个明显的缺点:
- 对 CPU 资源敏感;
- 无法处理浮动垃圾;
- 它使用的回收算法-“标记-清除”算法会导致收集结束时会有大量空间碎片产生
G1收集器
G1 (Garbage-First) 是一款面向服务器的垃圾收集器,主要针对配备多颗处理器及大容量内存的机器. 以极高概率满足 GC 停顿时间要求的同时,还具备高吞吐量性能特征.
具备以下特点:
并行与并发:G1 能充分利用 CPU、多核环境下的硬件优势,使用多个 CPU(CPU 或者 CPU 核心)来缩短 Stop-The-World 停顿时间。部分其他收集器原本需要停顿 Java 线程执行的 GC 动作,G1 收集器仍然可以通过并发的方式让 java 程序继续执行。
分代收集:虽然 G1 可以不需要其他收集器配合就能独立管理整个 GC 堆,但是还是保留了分代的概念。
空间整合:与 CMS 的“标记-清除”算法不同,G1 从整体来看是基于“标记-整理”算法实现的收集器;从局部上来看是基于“标记-复制”算法实现的。
可预测的停顿:这是 G1 相对于 CMS 的另一个大优势,降低停顿时间是 G1 和 CMS 共同的关注点,但 G1 除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为 M 毫秒的时间片段内,消耗在垃圾收集上的时间不得超过 N 毫秒。
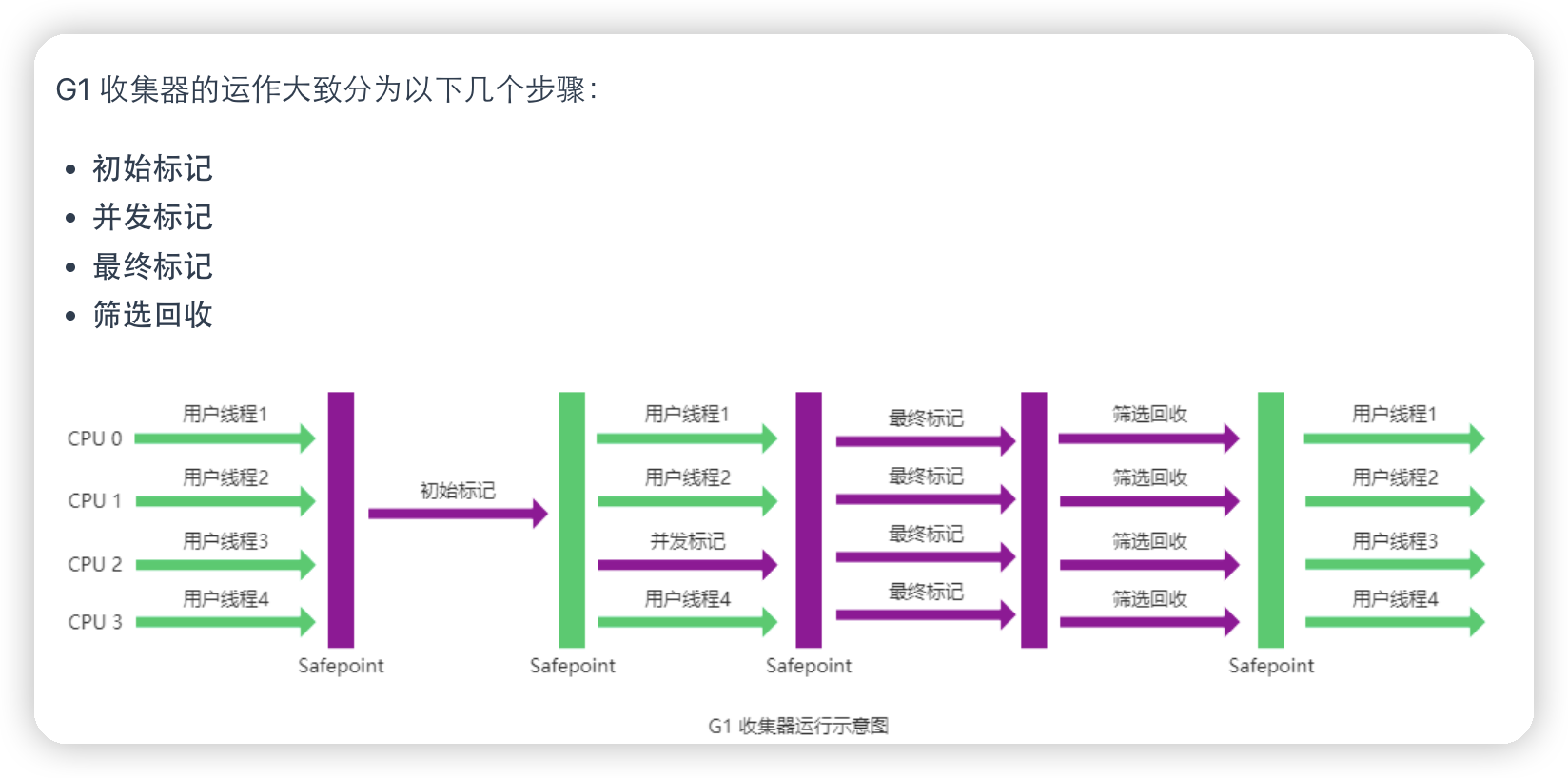
最终标记:这个阶段是并发标记的结束,它处理在并发标记阶段积累的变更(称为SATB(Snapshot-At-The-Beginning)标记的一部分),处理剩下的工作。
筛选回收:G1会复制活动对象到新的区域,释放大量空间,这通常发生在年轻代和老年代区域
ZGC收集器
与 CMS 中的 ParNew 和 G1 类似,ZGC 也采用标记-复制算法,不过 ZGC 对该算法做了重大改进。
在 ZGC 中出现 Stop The World 的情况会更少!
类的生命周期
类从被加载到虚拟机内存中开始到卸载出内存为止,它的整个生命周期可以简单概括为 7 个阶段:
加载(Loading)、验证(Verification)、准备(Preparation)、解析(Resolution)、初始化(Initialization)、使用(Using)和卸载(Unloading)。
其中,验证、准备和解析这三个阶段可以统称为连接(Linking)
加载:
- 通过全类名获取定义此类的二进制字节流。
- 将字节流所代表的静态存储结构转换为方法区的运行时数据结构。
- 在内存中生成一个代表该类的
Class对象,作为方法区这些数据的访问入口。
验证:
-
文件格式验证(Class 文件格式检查)
文件格式验证这一阶段是基于该类的二进制字节流进行的,主要目的是保证输入的字节流能正确地解析并存储于方法区之内,格式上符合描述一个 Java 类型信息的要求。
-
元数据验证(字节码语义检查)
-
字节码验证(程序语义检查)
-
符号引用验证(类的正确性检查)
准备:
准备阶段是正式为类变量分配内存并设置类变量初始值的阶段
-
这时候进行内存分配的仅包括类变量( Class Variables ,即静态变量,被
static关键字修饰的变量,只与类相关,因此被称为类变量),而不包括实例变量。实例变量会在对象实例化时随着对象一块分配在 Java 堆中。 -
从概念上讲,类变量所使用的内存都应当在 方法区 中进行分配。不过有一点需要注意的是:JDK 7 之前,HotSpot 使用永久代来实现方法区的时候,实现是完全符合这种逻辑概念的。 而在 JDK 7 及之后,HotSpot 已经把原本放在永久代的字符串常量池、静态变量等移动到堆中,这个时候类变量则会随着 Class 对象一起存放在 Java 堆中。
-
这里所设置的初始值”通常情况”下是数据类型默认的零值(如 0、0L、null、false 等),比如我们定义了
public static int value=111,那么 value 变量在准备阶段的初始值就是 0 而不是 111(初始化阶段才会赋值)。特殊情况:比如给 value 变量加上了 final 关键字
public static final int value=111,那么准备阶段 value 的值就被赋值为 111。
解析:
解析阶段是虚拟机将常量池内的符号引用替换为直接引用的过程
在解析阶段为每个类准备一个方法表来存放类中所有的方法,当需要调用一个类的方法时,只要知道这个方法在方法表的偏移量就可以直接调用该方法了
初始化:
初始化阶段是执行初始化方法 <clinit> ()方法的过程,是类加载的最后一步,这一步 JVM 才开始真正执行类中定义的 Java 程序代码(字节码)

使用:
卸载:
卸载类即该类的 Class 对象被 GC
卸载类需要满足 3 个要求:
- 该类的所有的实例对象都已被 GC,也就是说堆不存在该类的实例对象。
- 该类没有在其他任何地方被引用
- 该类的类加载器的实例已被 GC
类加载器
- 类加载过程:加载->连接->初始化
- 连接过程又可分为三步:验证->准备->解析
加载是类加载过程的第一步,主要完成下面 3 件事情:
- 通过全类名获取定义此类的二进制字节流
- 将字节流所代表的静态存储结构转换为方法区的运行时数据结构
- 在内存中生成一个代表该类的
Class对象,作为方法区这些数据的访问入口
类加载器
赋予了 Java 类可以被动态加载到 JVM 中并执行的能力
-
类加载器是一个负责加载类的对象,用于实现类加载过程中的加载这一步。
-
每个 Java 类都有一个引用指向加载它的
ClassLoader。 -
数组类不是通过
ClassLoader创建的(数组类没有对应的二进制字节流),是由 JVM 直接生成的。
类加载器的主要作用就是加载 Java 类的字节码( .class 文件)到 JVM 中(在内存中生成一个代表该类的 Class 对象)。 字节码可以是 Java 源程序(.java文件)经过 javac 编译得来,也可以是通过工具动态生成或者通过网络下载得来
类加载器加载规则
- JVM 启动的时候,并不会一次性加载所有的类,而是根据需要去动态加载。也就是说,大部分类在具体用到的时候才会去加载,这样对内存更加友好
- 对于已经加载的类会被放在
ClassLoader中。在类加载的时候,系统会首先判断当前类是否被加载过。已经被加载的类会直接返回,否则才会尝试加载。也就是说,对于一个类加载器来说,相同二进制名称的类只会被加载一次
类加载器总结
-
BootstrapClassLoader(启动类加载器):最顶层的加载类,由 C++实现,通常表示为 null,并且没有父级,主要用来加载 JDK 内部的核心类库(%JAVA_HOME%/lib目录下的rt.jar、resources.jar、charsets.jar等 jar 包和类)以及被-Xbootclasspath参数指定的路径下的所有类。 -
ExtensionClassLoader(扩展类加载器):主要负责加载%JRE_HOME%/lib/ext目录下的 jar 包和类以及被java.ext.dirs系统变量所指定的路径下的所有类。 -
AppClassLoader(应用程序类加载器):面向我们用户的加载器,负责加载当前应用 classpath 下的所有 jar 包和类。
自定义类加载器
我们前面也说说了,除了 BootstrapClassLoader 其他类加载器均由 Java 实现且全部继承自java.lang.ClassLoader。如果我们要自定义自己的类加载器,很明显需要继承 ClassLoader抽象类
如果我们不想打破双亲委派模型,就重写 ClassLoader 类中的 findClass() 方法即可,无法被父类加载器加载的类最终会通过这个方法被加载。但是,如果想打破双亲委派模型则需要重写 loadClass() 方法。
双亲委派模型
类加载器有很多种,当我们想要加载一个类的时候,具体是哪个类加载器加载呢?这就需要提到双亲委派模型了
-
ClassLoader类使用委托模型来搜索类和资源。 -
双亲委派模型要求除了顶层的启动类加载器外,其余的类加载器都应有自己的父类加载器。
-
ClassLoader实例会在试图亲自查找类或资源之前,将搜索类或资源的任务委托给其父类加载器。
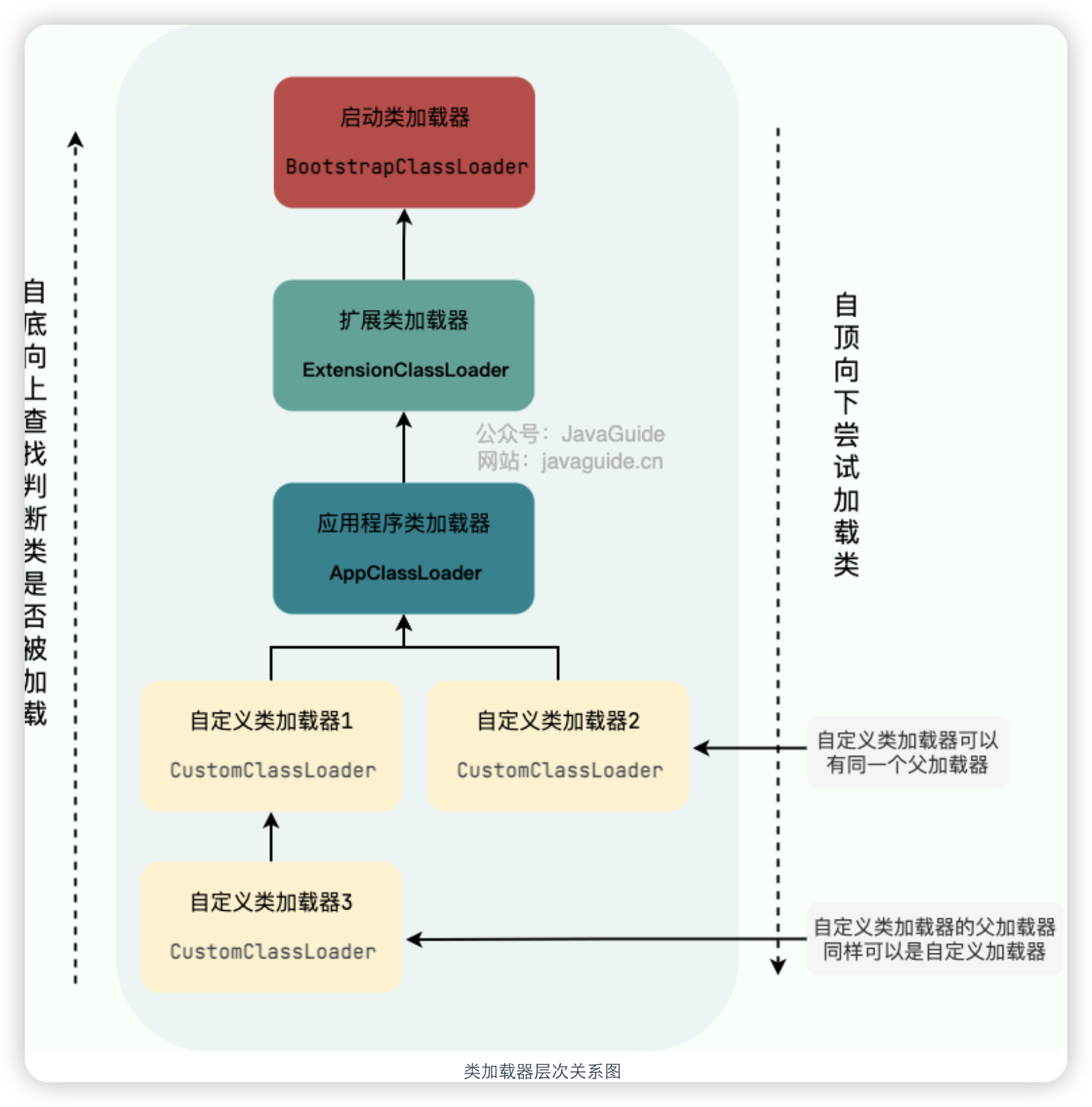
双亲委派模型流程:
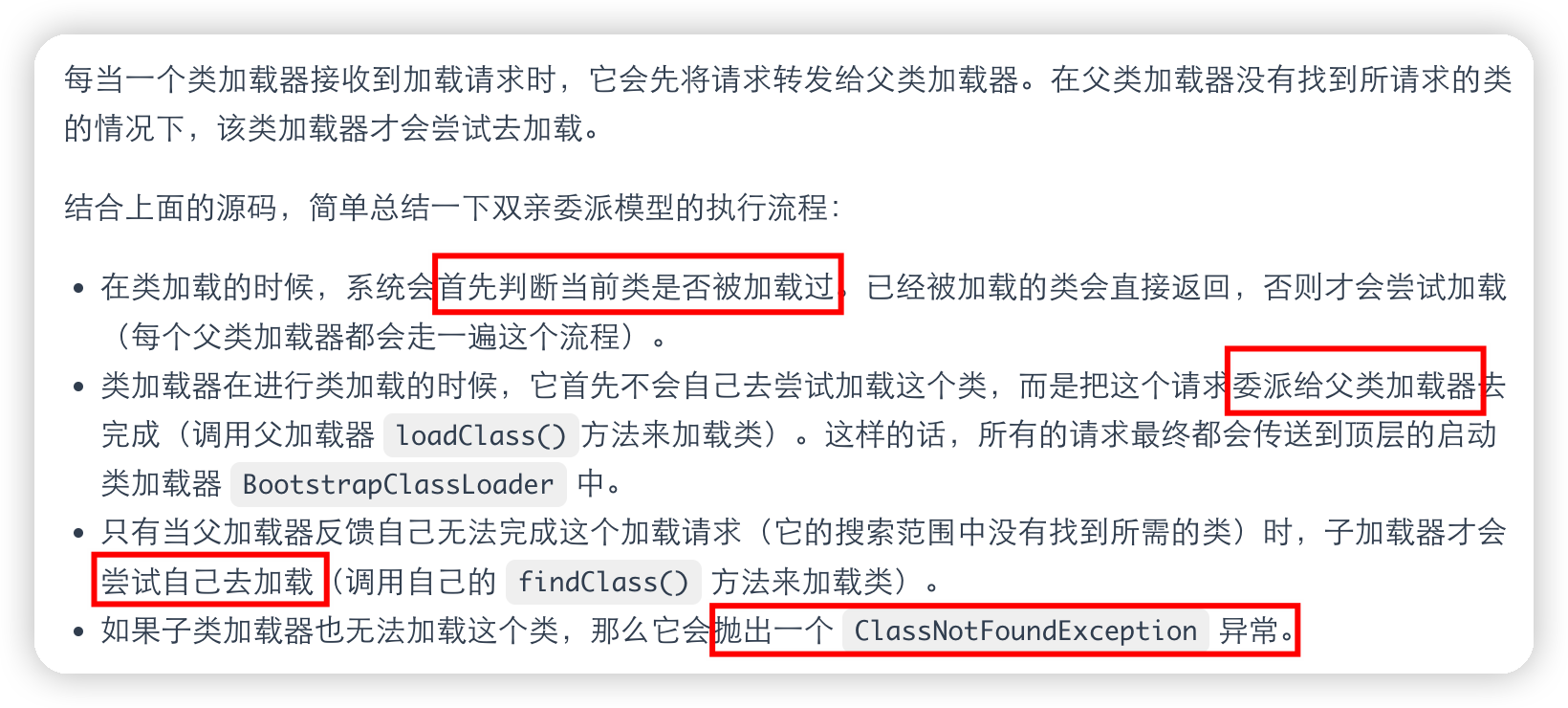
使用双亲委派模型的好处:
保证了 Java 程序的稳定运行,可以避免类的重复加载
像之前自定义类加载器中说的一样,如果要打破双亲委派模型,就需要重写loadClass() 方法,因为loadClass方法里就是首先去找父类等
线程上下文类加载器
有时候高层的类加载器需要加载低层的加载器才能加载的类。
比如,SPI 中,SPI 的接口(如 java.sql.Driver)是由 Java 核心库提供的,由BootstrapClassLoader 加载。而 SPI 的实现(如com.mysql.cj.jdbc.Driver)是由第三方供应商提供的,它们是由应用程序类加载器或者自定义类加载器来加载的。默认情况下,一个类及其依赖类由同一个类加载器加载。所以,加载 SPI 的接口的类加载器(BootstrapClassLoader)也会用来加载 SPI 的实现。按照双亲委派模型,BootstrapClassLoader 是无法找到 SPI 的实现类的,因为它无法委托给子类加载器去尝试加载。
每个 Web 应用都会创建一个单独的 WebAppClassLoader,并在启动 Web 应用的线程里设置线程线程上下文类加载器为 WebAppClassLoader。这样就可以让高层的类加载器(SharedClassLoader)借助子类加载器( WebAppClassLoader)来加载业务类,破坏了 Java 的类加载委托机制,让应用逆向使用类加载器。
原理是将一个类加载器保存在线程私有数据里,跟线程绑定,然后在需要的时候取出来使用。这个类加载器通常是由应用程序或者容器(如 Tomcat)设置的
Spring中的设计模式
工厂设计模式
Spring 使用工厂模式可以通过 BeanFactory 或 ApplicationContext 创建 bean 对象
两者对比:
BeanFactory:延迟注入(使用到某个 bean 的时候才会注入),相比于ApplicationContext来说会占用更少的内存,程序启动速度更快。ApplicationContext:容器启动的时候,不管你用没用到,一次性创建所有 bean 。BeanFactory仅提供了最基本的依赖注入支持,ApplicationContext扩展了BeanFactory,除了有BeanFactory的功能还有额外更多功能,所以一般开发人员使用ApplicationContext会更多。
ApplicationContext 的三个实现类:
ClassPathXmlApplication:把上下文文件当成类路径资源。FileSystemXmlApplication:从文件系统中的 XML 文件载入上下文定义信息。XmlWebApplicationContext:从 Web 系统中的 XML 文件载入上下文定义信息。
单例设计模式
使用单例模式的好处 :
- 对于频繁使用的对象,可以省略创建对象所花费的时间,这对于那些重量级对象而言,是非常可观的一笔系统开销;
- 由于 new 操作的次数减少,因而对系统内存的使用频率也会降低,这将减轻 GC 压力,缩短 GC 停顿时间。

Spring 通过 ConcurrentHashMap 实现单例注册表的特殊方式实现单例模式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
// 通过 ConcurrentHashMap(线程安全) 实现单例注册表
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<String, Object>(64);
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(beanName, "'beanName' must not be null");
synchronized (this.singletonObjects) {
// 检查缓存中是否存在实例
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
//...省略了很多代码
try {
singletonObject = singletonFactory.getObject();
}
//...省略了很多代码
// 如果实例对象在不存在,我们注册到单例注册表中。
addSingleton(beanName, singletonObject);
}
return (singletonObject != NULL_OBJECT ? singletonObject : null);
}
}
//将对象添加到单例注册表
protected void addSingleton(String beanName, Object singletonObject) {
synchronized (this.singletonObjects) {
this.singletonObjects.put(beanName, (singletonObject != null ? singletonObject : NULL_OBJECT));
}
}
}
代理设计模式
代理模式在AOP应用
Spring AOP 就是基于动态代理的,如果要代理的对象,实现了某个接口,那么 Spring AOP 会使用 JDK Proxy 去创建代理对象,而对于没有实现接口的对象,就无法使用 JDK Proxy 去进行代理了,这时候 Spring AOP 会使用 Cglib 生成一个被代理对象的子类来作为代理
Spring AOP 和 AspectJ AOP 有什么区别
Spring AOP 属于运行时增强,而 AspectJ 是编译时增强。 Spring AOP 基于代理(Proxying),而 AspectJ 基于字节码操作
模板方法
模板方法模式是一种行为设计模式,它定义一个操作中的算法的骨架,而将一些步骤延迟到子类中。 模板方法使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤的实现方式。
观察者模式
表示的是一种对象与对象之间具有依赖关系,当一个对象发生改变的时候,依赖这个对象的所有对象也会做出反应
Spring 事件驱动模型中的三种角色
事件角色
ApplicationEvent
Spring 中默认存在以下事件,他们都是对 ApplicationContextEvent 的实现(继承自ApplicationContextEvent):
ContextStartedEvent:ApplicationContext启动后触发的事件;ContextStoppedEvent:ApplicationContext停止后触发的事件;ContextRefreshedEvent:ApplicationContext初始化或刷新完成后触发的事件;ContextClosedEvent:ApplicationContext关闭后触发的事件。
事件监听者角色
ApplicationListener 充当了事件监听者角色,它是一个接口,里面只定义了一个 onApplicationEvent()方法来处理ApplicationEvent。ApplicationListener接口类源码如下,可以看出接口定义看出接口中的事件只要实现了 ApplicationEvent就可以了。所以,在 Spring 中我们只要实现 ApplicationListener 接口的 onApplicationEvent() 方法即可完成监听事件
事件发布者角色
ApplicationEventPublisher 充当了事件的发布者,它也是一个接口。
Spring 的事件流程总结
- 定义一个事件: 实现一个继承自
ApplicationEvent,并且写相应的构造函数; - 定义一个事件监听者:实现
ApplicationListener接口,重写onApplicationEvent()方法; - 使用事件发布者发布消息: 可以通过
ApplicationEventPublisher的publishEvent()方法发布消息。
适配器模式
将一个接口转换成客户希望的另一个接口,适配器模式使接口不兼容的那些类可以一起工作
Spring AOP 中的适配器模式
Spring AOP 的实现是基于代理模式,但是 Spring AOP 的增强或通知(Advice)使用到了适配器模式,与之相关的接口是AdvisorAdapter
Advice 常用的类型有:BeforeAdvice(目标方法调用前,前置通知)、AfterAdvice(目标方法调用后,后置通知)、AfterReturningAdvice(目标方法执行结束后,return 之前)等等。每个类型 Advice(通知)都有对应的拦截器:MethodBeforeAdviceInterceptor、AfterReturningAdviceInterceptor、ThrowsAdviceInterceptor 等等
Spring MVC 中的适配器模式
在 Spring MVC 中,DispatcherServlet 根据请求信息调用 HandlerMapping,解析请求对应的 Handler。解析到对应的 Handler(也就是我们平常说的 Controller 控制器)后,开始由HandlerAdapter 适配器处理。HandlerAdapter 作为期望接口,具体的适配器实现类用于对目标类进行适配,Controller 作为需要适配的类。
装饰者模式
装饰者模式可以动态地给对象添加一些额外的属性或行为。相比于使用继承,装饰者模式更加灵活。简单点儿说就是当我们需要修改原有的功能,但我们又不愿直接去修改原有的代码时,设计一个 Decorator 套在原有代码外面。其实在 JDK 中就有很多地方用到了装饰者模式,比如 InputStream家族,InputStream 类下有 FileInputStream (读取文件)、BufferedInputStream (增加缓存,使读取文件速度大大提升)等子类都在不修改InputStream 代码的情况下扩展了它的功能。
计算机网络
网络分层模型
OSI七层模型
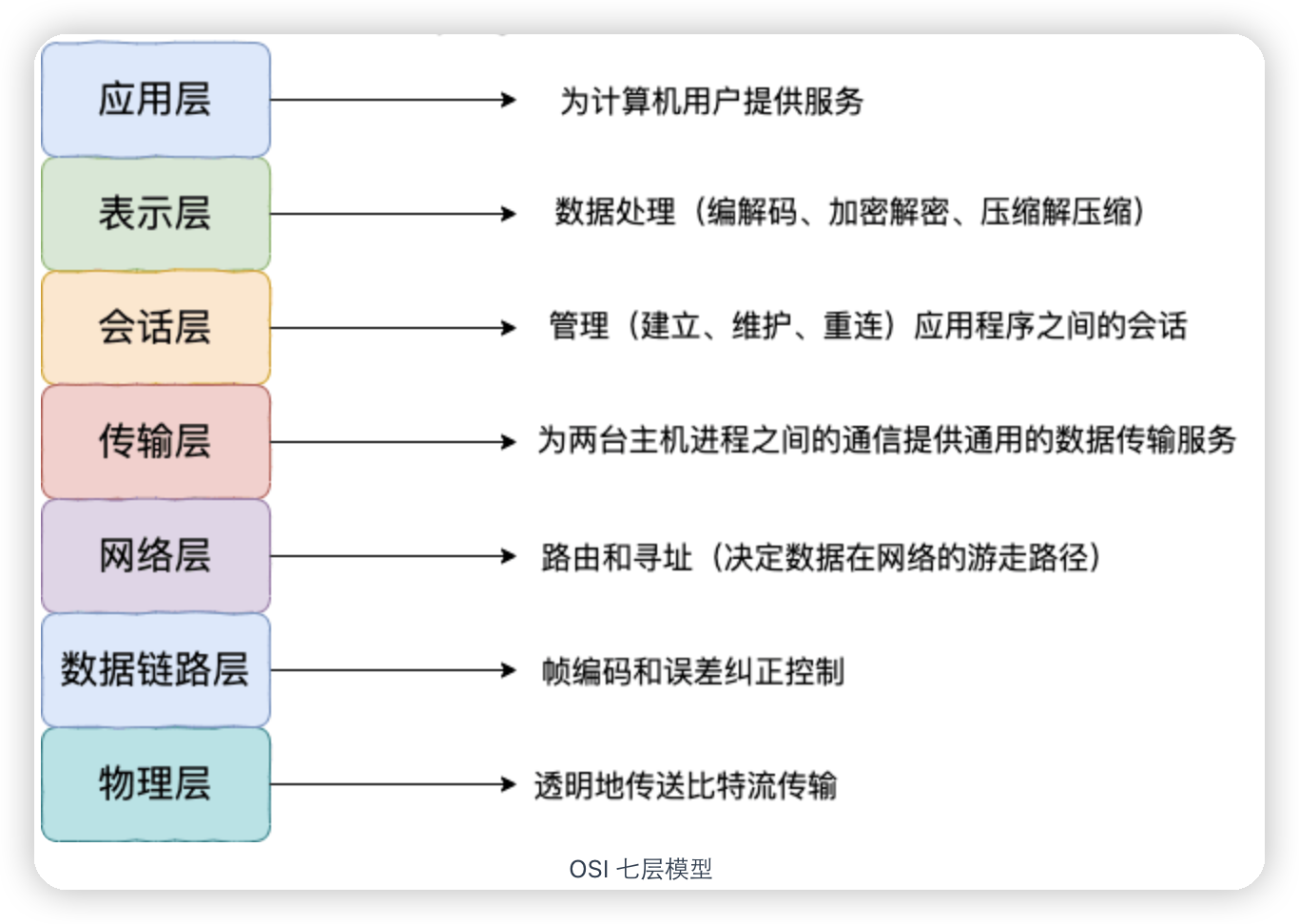
-
物理层(Physical Layer):
- 负责原始数据的传输,包括数据的编码、电压、接线、数据速率等。这层关注的是物理连接的特性。
物理层的主要任务就是确定与传输媒体接口有关的一些特性,如机械特性,电气特性,功能特性,过程特性
考虑的是怎样才能在连接各种计算机的传输媒体上传输数据比特流,而不是指具体的传输媒体。
常用的信道复用的技术:
- 频分复用(FDM):所有用户在同样的时间占用不同的带宽资源。
- 时分复用(TDM):所有用户在不同的时间占用同样的频带宽度(分时不分频)。
- 统计时分复用 (Statistic TDM):改进的时分复用,能够明显提高信道的利用率。
- 码分复用(CDM):用户使用经过特殊挑选的不同码型,因此各用户之间不会造成干扰。这种系统发送的信号有很强的抗干扰能力,其频谱类似于白噪声,不易被敌人发现。
- 波分复用( WDM):波分复用就是光的频分复用。
-
数据链路层(Data Link Layer):
- 负责在相邻节点之间的可靠传输,包括帧的定界、地址解析、错误检测和修正。它确保数据准确地传输到网络层。
数据链路层使用的主要是点对点信道和广播信道两种
数据链路层传输的协议数据单元是帧。数据链路层的三个基本问题是:封装成帧,透明传输和差错检测
循环冗余检验 CRC 是一种检错方法,而帧检验序列 FCS 是添加在数据后面的冗余码
点对点协议 PPP 是数据链路层使用最多的一种协议,它的特点是:简单,只检测差错而不去纠正差错,不使用序号,也不进行流量控制,可同时支持多种网络层协议
局域网的优点是:具有广播功能,从一个站点可方便地访问全网;便于系统的扩展和逐渐演变;提高了系统的可靠性,可用性和生存性。
-
网络层(Network Layer):
- 负责不同网络之间的数据传输和路由选择,包括寻址、数据包的转发和路由决策。
-
传输层(Transport Layer):
- 负责端到端的数据传输,确保数据的完整性。这一层实现了错误检测、数据重传和流量控制等功能。
-
会话层(Session Layer):
- 负责建立、管理和终止会话。它允许不同应用之间的会话控制和数据交换。
-
表示层(Presentation Layer):
- 负责数据的表示、加密和解密,数据压缩。它确保从应用层发出的数据可以被另一端的应用层理解。
-
应用层(Application Layer):
- 接近最终用户,负责处理特定的应用程序细节。这层为应用软件提供网络服务。
TCP/IP四层模型
- 应用层
- 传输层
- 网络层
- 网络接口层
常见的网络协议
应用层有哪些常见的协议
HTTP(Hypertext Transfer Protocol,超文本传输协议):基于 TCP 协议,是一种用于传输超文本和多媒体内容的协议,主要是为 Web 浏览器与 Web 服务器之间的通信而设计的。当我们使用浏览器浏览网页的时候,我们网页就是通过 HTTP 请求进行加载的。
SMTP(Simple Mail Transfer Protocol,简单邮件发送协议):基于 TCP 协议,是一种用于发送电子邮件的协议。注意 ⚠️:SMTP 协议只负责邮件的发送,而不是接收。要从邮件服务器接收邮件,需要使用 POP3 或 IMAP 协议。
POP3/IMAP(邮件接收协议):基于 TCP 协议,两者都是负责邮件接收的协议。IMAP 协议是比 POP3 更新的协议,它在功能和性能上都更加强大。IMAP 支持邮件搜索、标记、分类、归档等高级功能,而且可以在多个设备之间同步邮件状态。几乎所有现代电子邮件客户端和服务器都支持 IMAP。
FTP(File Transfer Protocol,文件传输协议) : 基于 TCP 协议,是一种用于在计算机之间传输文件的协议,可以屏蔽操作系统和文件存储方式。注意 ⚠️:FTP 是一种不安全的协议,因为它在传输过程中不会对数据进行加密。建议在传输敏感数据时使用更安全的协议,如 SFTP。
Telnet(远程登陆协议):基于 TCP 协议,用于通过一个终端登陆到其他服务器。Telnet 协议的最大缺点之一是所有数据(包括用户名和密码)均以明文形式发送,这有潜在的安全风险。这就是为什么如今很少使用 Telnet,而是使用一种称为 SSH 的非常安全的网络传输协议的主要原因。
SSH(Secure Shell Protocol,安全的网络传输协议):基于 TCP 协议,通过加密和认证机制实现安全的访问和文件传输等业务
RTP(Real-time Transport Protocol,实时传输协议):通常基于 UDP 协议,但也支持 TCP 协议。它提供了端到端的实时传输数据的功能,但不包含资源预留存、不保证实时传输质量,这些功能由 WebRTC 实现。
DNS(Domain Name System,域名管理系统): 基于 UDP 协议,用于解决域名和 IP 地址的映射问题。
传输层有哪些常见的协议
- TCP(Transmission Control Protocol,传输控制协议 ):提供 面向连接 的,可靠 的数据传输服务。
- UDP(User Datagram Protocol,用户数据协议):提供 无连接 的,尽最大努力 的数据传输服务(不保证数据传输的可靠性),简单高效。
网络层有哪些常见的协议
IP(Internet Protocol,网际协议):TCP/IP 协议中最重要的协议之一,属于网络层的协议,主要作用是定义数据包的格式、对数据包进行路由和寻址,以便它们可以跨网络传播并到达正确的目的地。目前 IP 协议主要分为两种,一种是过去的 IPv4,另一种是较新的 IPv6,目前这两种协议都在使用,但后者已经被提议来取代前者。
ARP(Address Resolution Protocol,地址解析协议):ARP 协议解决的是网络层地址和链路层地址之间的转换问题。因为一个 IP 数据报在物理上传输的过程中,总是需要知道下一跳(物理上的下一个目的地)该去往何处,但 IP 地址属于逻辑地址,而 MAC 地址才是物理地址,ARP 协议解决了 IP 地址转 MAC 地址的一些问题。
ICMP(Internet Control Message Protocol,互联网控制报文协议):一种用于传输网络状态和错误消息的协议,常用于网络诊断和故障排除。例如,Ping 工具就使用了 ICMP 协议来测试网络连通性
NAT(Network Address Translation,网络地址转换协议):NAT 协议的应用场景如同它的名称——网络地址转换,应用于内部网到外部网的地址转换过程中。具体地说,在一个小的子网(局域网,LAN)内,各主机使用的是同一个 LAN 下的 IP 地址,但在该 LAN 以外,在广域网(WAN)中,需要一个统一的 IP 地址来标识该 LAN 在整个 Internet 上的位置。
OSPF(Open Shortest Path First,开放式最短路径优先) ):一种内部网关协议(Interior Gateway Protocol,IGP),也是广泛使用的一种动态路由协议,基于链路状态算法,考虑了链路的带宽、延迟等因素来选择最佳路径。
RIP(Routing Information Protocol,路由信息协议):一种内部网关协议(Interior Gateway Protocol,IGP),也是一种动态路由协议,基于距离向量算法,使用固定的跳数作为度量标准,选择跳数最少的路径作为最佳路径。
BGP(Border Gateway Protocol,边界网关协议):一种用来在路由选择域之间交换网络层可达性信息(Network Layer Reachability Information,NLRI)的路由选择协议,具有高度的灵活性和可扩展性。
HTTP
从输入 URL 到页面展示到底发生了什么

HTTP 和 HTTPS 有什么区别
-
端口号:HTTP 默认是 80,HTTPS 默认是 443。
-
URL 前缀:HTTP 的 URL 前缀是
http://,HTTPS 的 URL 前缀是https://。 -
安全性和资源消耗:HTTP 协议运行在 TCP 之上,所有传输的内容都是明文,客户端和服务器端都无法验证对方的身份。HTTPS 是运行在 SSL/TLS 之上的 HTTP 协议,SSL/TLS 运行在 TCP 之上。所有传输的内容都经过加密,加密采用对称加密,但对称加密的密钥用服务器方的证书进行了非对称加密。所以说,HTTP 安全性没有 HTTPS 高,但是 HTTPS 比 HTTP 耗费更多服务器资源。
-
SEO(搜索引擎优化):搜索引擎通常会更青睐使用 HTTPS 协议的网站,因为 HTTPS 能够提供更高的安全性和用户隐私保护。使用 HTTPS 协议的网站在搜索结果中可能会被优先显示,从而对 SEO 产生影响。
HTTP/1.0 和 HTTP/1.1 有什么区别
-
连接方式 : HTTP/1.0 为短连接,HTTP/1.1 支持长连接。
-
状态响应码 : HTTP/1.1 中新加入了大量的状态码,光是错误响应状态码就新增了 24 种。比如说,
100 (Continue)——在请求大资源前的预热请求,206 (Partial Content)——范围请求的标识码,409 (Conflict)——请求与当前资源的规定冲突,410 (Gone)——资源已被永久转移,而且没有任何已知的转发地址。 -
缓存机制 : 在 HTTP/1.0 中主要使用 Header 里的 If-Modified-Since,Expires 来做为缓存判断的标准,HTTP/1.1 则引入了更多的缓存控制策略例如 Entity tag,If-Unmodified-Since, If-Match, If-None-Match 等更多可供选择的缓存头来控制缓存策略。
-
带宽:HTTP/1.0 中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP/1.1 则在请求头引入了 range 头域,它允许只请求资源的某个部分,即返回码是 206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
-
Host 头(Host Header)处理 :HTTP/1.1 引入了 Host 头字段,允许在同一 IP 地址上托管多个域名,从而支持虚拟主机的功能。而 HTTP/1.0 没有 Host 头字段,无法实现虚拟主机。
HTTP/1.1 和 HTTP/2.0 有什么区别
-
多路复用(Multiplexing):HTTP/2.0 在同一连接上可以同时传输多个请求和响应(可以看作是 HTTP/1.1 中长链接的升级版本),互不干扰。HTTP/1.1 则使用串行方式,每个请求和响应都需要独立的连接,而浏览器为了控制资源会有 6-8 个 TCP 连接都限制。。这使得 HTTP/2.0 在处理多个请求时更加高效,减少了网络延迟和提高了性能。
-
二进制帧(Binary Frames):HTTP/2.0 使用二进制帧进行数据传输,而 HTTP/1.1 则使用文本格式的报文。二进制帧更加紧凑和高效,减少了传输的数据量和带宽消耗。
-
头部压缩(Header Compression):HTTP/1.1 支持
Body压缩,Header不支持压缩。HTTP/2.0 支持对Header压缩,使用了专门为Header压缩而设计的 HPACK 算法,减少了网络开销。 -
服务器推送(Server Push):HTTP/2.0 支持服务器推送,可以在客户端请求一个资源时,将其他相关资源一并推送给客户端,从而减少了客户端的请求次数和延迟。而 HTTP/1.1 需要客户端自己发送请求来获取相关资源。
HTTP/2.0 和 HTTP/3.0 有什么区别
-
传输协议:HTTP/2.0 是基于 TCP 协议实现的,HTTP/3.0 新增了 QUIC(Quick UDP Internet Connections) 协议来实现可靠的传输,提供与 TLS/SSL 相当的安全性,具有较低的连接和传输延迟。你可以将 QUIC 看作是 UDP 的升级版本,在其基础上新增了很多功能比如加密、重传等等。HTTP/3.0 之前名为 HTTP-over-QUIC,从这个名字中我们也可以发现,HTTP/3 最大的改造就是使用了 QUIC。
-
连接建立:HTTP/2.0 需要经过经典的 TCP 三次握手过程(由于安全的 HTTPS 连接建立还需要 TLS 握手,共需要大约 3 个 RTT)。由于 QUIC 协议的特性(TLS 1.3,TLS 1.3 除了支持 1 个 RTT 的握手,还支持 0 个 RTT 的握手)连接建立仅需 0-RTT 或者 1-RTT。这意味着 QUIC 在最佳情况下不需要任何的额外往返时间就可以建立新连接。
-
队头阻塞:HTTP/2.0 多请求复用一个 TCP 连接,一旦发生丢包,就会阻塞住所有的 HTTP 请求。由于 QUIC 协议的特性,HTTP/3.0 在一定程度上解决了队头阻塞(Head-of-Line blocking, 简写:HOL blocking)问题,一个连接建立多个不同的数据流,这些数据流之间独立互不影响,某个数据流发生丢包了,其数据流不受影响(本质上是多路复用+轮询)。
-
错误恢复:HTTP/3.0 具有更好的错误恢复机制,当出现丢包、延迟等网络问题时,可以更快地进行恢复和重传。而 HTTP/2.0 则需要依赖于 TCP 的错误恢复机制。
-
安全性:HTTP/2.0 和 HTTP/3.0 在安全性上都有较高的要求,支持加密通信,但在实现上有所不同。HTTP/2.0 使用 TLS 协议进行加密,而 HTTP/3.0 基于 QUIC 协议,包含了内置的加密和身份验证机制,可以提供更强的安全性。
HTTP是不保存状态协议,所以需要通过session机制通过服务端记录用户状态,一般是把session放在cookie中,如果cookie被禁用,一般就放在url中
URI 和 URL 的区别是什么
URI(Uniform Resource Identifier) 是统一资源标志符,可以唯一标识一个资源。
URL(Uniform Resource Locator) 是统一资源定位符,可以提供该资源的路径。它是一种具体的 URI,即 URL 可以用来标识一个资源,而且还指明了如何 locate 这个资源。
Cookie 和 Session 有什么区别
-
存储位置
cookie存储在客户端,session存储在服务器端
-
安全性
cookie由于存储在客户端,所以容易被篡改和窃取,不适合存储敏感数据,session存储在服务器端,客户端无法直接访问,所以更安全
-
存储大小
cookie存储大小有限,约为5KB,session没有存储大小的限制,适合存储较大的数据
-
寿命
cookie可以持久存储在客户端,直到过期或删除,session寿命取决于会话的时间,通常浏览器关闭后结束,但也可以设置超时时间
-
用途
cookie存储个性化设置,跟踪用户会话等,session用于存储用户登陆信息,购物车等敏感数据
GET和POST有什么区别
GET 和 POST 是 HTTP 协议中两种常用的请求方法
-
语义(主要区别):GET 通常用于获取或查询资源,而 POST 通常用于创建或修改资源。
-
幂等:GET 请求是幂等的,即多次重复执行不会改变资源的状态,而 POST 请求是不幂等的,即每次执行可能会产生不同的结果或影响资源的状态。
-
格式:GET 请求的参数通常放在 URL 中,形成查询字符串(querystring),而 POST 请求的参数通常放在请求体(body)中,可以有多种编码格式,如 application/x-www-form-urlencoded、multipart/form-data、application/json 等。GET 请求的 URL 长度受到浏览器和服务器的限制,而 POST 请求的 body 大小则没有明确的限制。不过,实际上 GET 请求也可以用 body 传输数据,只是并不推荐这样做,因为这样可能会导致一些兼容性或者语义上的问题。
-
缓存:由于 GET 请求是幂等的,它可以被浏览器或其他中间节点(如代理、网关)缓存起来,以提高性能和效率。而 POST 请求则不适合被缓存,因为它可能有副作用,每次执行可能需要实时的响应。
-
安全性:GET 请求和 POST 请求如果使用 HTTP 协议的话,那都不安全,因为 HTTP 协议本身是明文传输的,必须使用 HTTPS 协议来加密传输数据。另外,GET 请求相比 POST 请求更容易泄露敏感数据,因为 GET 请求的参数通常放在 URL 中。
PING
PING 命令是一种常用的网络诊断工具,经常用来测试网络中主机之间的连通性和网络延迟。
基于网络层的ICMP,通过在网络上发送和接收的ICMP报文实现的
- 查询报文类型:向目标主机发送请求并期望得到响应。
- 差错报文类型:向源主机发送错误信息,用于报告网络中的错误情况。
DNS
是当用户使用浏览器访问网址之后,使用的第一个重要协议。DNS 要解决的是域名和 IP 地址的映射问题
- 根 DNS 服务器。根 DNS 服务器提供 TLD 服务器的 IP 地址。目前世界上只有 13 组根服务器,我国境内目前仍没有根服务器。
- 顶级域 DNS 服务器(TLD 服务器)。顶级域是指域名的后缀,如
com、org、net和edu等。国家也有自己的顶级域,如uk、fr和ca。TLD 服务器提供了权威 DNS 服务器的 IP 地址。 - 权威 DNS 服务器。在因特网上具有公共可访问主机的每个组织机构必须提供公共可访问的 DNS 记录,这些记录将这些主机的名字映射为 IP 地址。
- 本地 DNS 服务器。每个 ISP(互联网服务提供商)都有一个自己的本地 DNS 服务器。当主机发出 DNS 请求时,该请求被发往本地 DNS 服务器,它起着代理的作用,并将该请求转发到 DNS 层次结构中。严格说来,不属于 DNS 层级结构
TCP与UDP
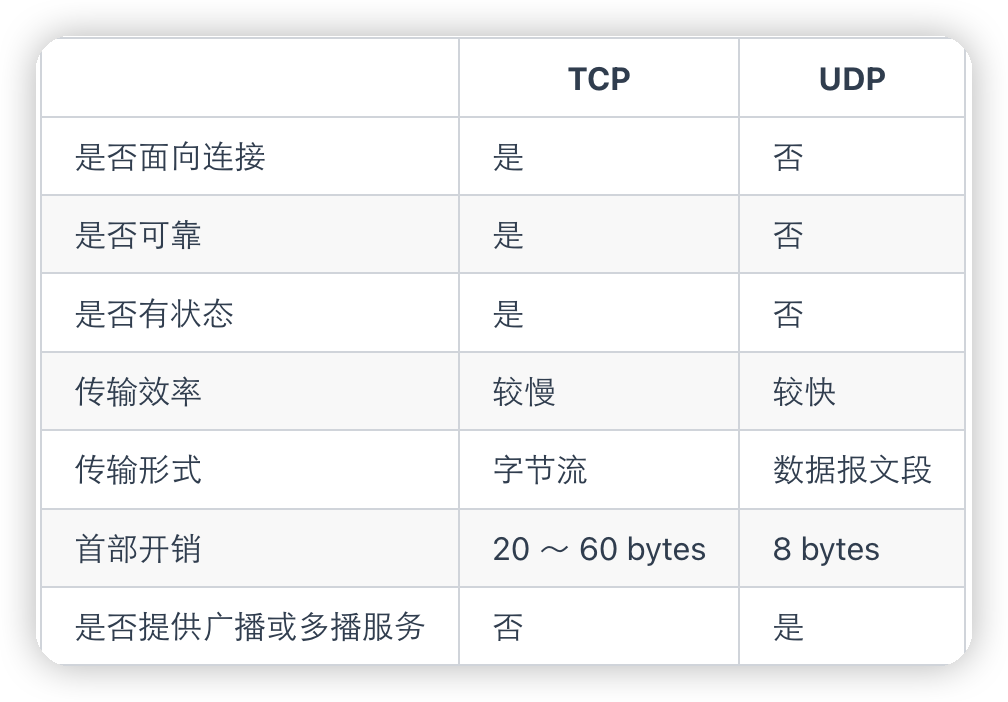
- 连接性
- TCP: 连接导向。在数据传输前需要建立连接,通过三次握手过程建立可靠的连接。
- UDP: 无连接。数据在无需建立连接的情况下直接发送。
- 可靠性
- TCP: 提供高度可靠的数据传输。通过序列号、确认响应、重传机制等确保数据完整性和顺序。
- UDP: 不保证数据传输的可靠性。没有内建的重传、顺序保证或数据完整性检查。
- 速度和效率
- TCP: 由于其确认和重传机制,相比于UDP来说较慢,处理开销更大。
- UDP: 更快速且高效,适用于对实时性要求高的应用。
- 数据流
- TCP: 面向字节流,数据传输没有明显的边界。
- UDP: 面向数据报,每个UDP数据包都是独立的单元。
- 头部开销
- TCP: 头部较大,通常20字节,包含多个用于保障可靠性和流控制的字段。
- UDP: 头部较小,只有8字节,包含基本的端口和校验和信息。
- 使用场景
- TCP: 适用于要求高数据准确性的应用,如网页浏览、文件传输、电子邮件等。
- UDP: 适用于要求低延迟和高速传输的应用,如视频会议、在线游戏、实时数据广播等。
HTTP 基于 TCP 还是 UDP
HTTP/3.0 之前是基于 TCP 协议的,而 HTTP/3.0 将弃用 TCP,改用 基于 UDP 的 QUIC 协议
-
此变化解决了HTTP/2中队头阻塞的问题,由于 HTTP/2.0 在单个 TCP 连接上使用了多路复用,受到 TCP 拥塞控制的影响,少量的丢包就可能导致整个 TCP 连接上的所有流被阻塞。HTTP/3.0 在一定程度上解决了队头阻塞问题,一个连接建立多个不同的数据流,这些数据流之间独立互不影响,某个数据流发生丢包了,其数据流不受影响
-
变化之后也有助于减少握手过程的延迟

TCP的三次握手和四次挥手
三次握手
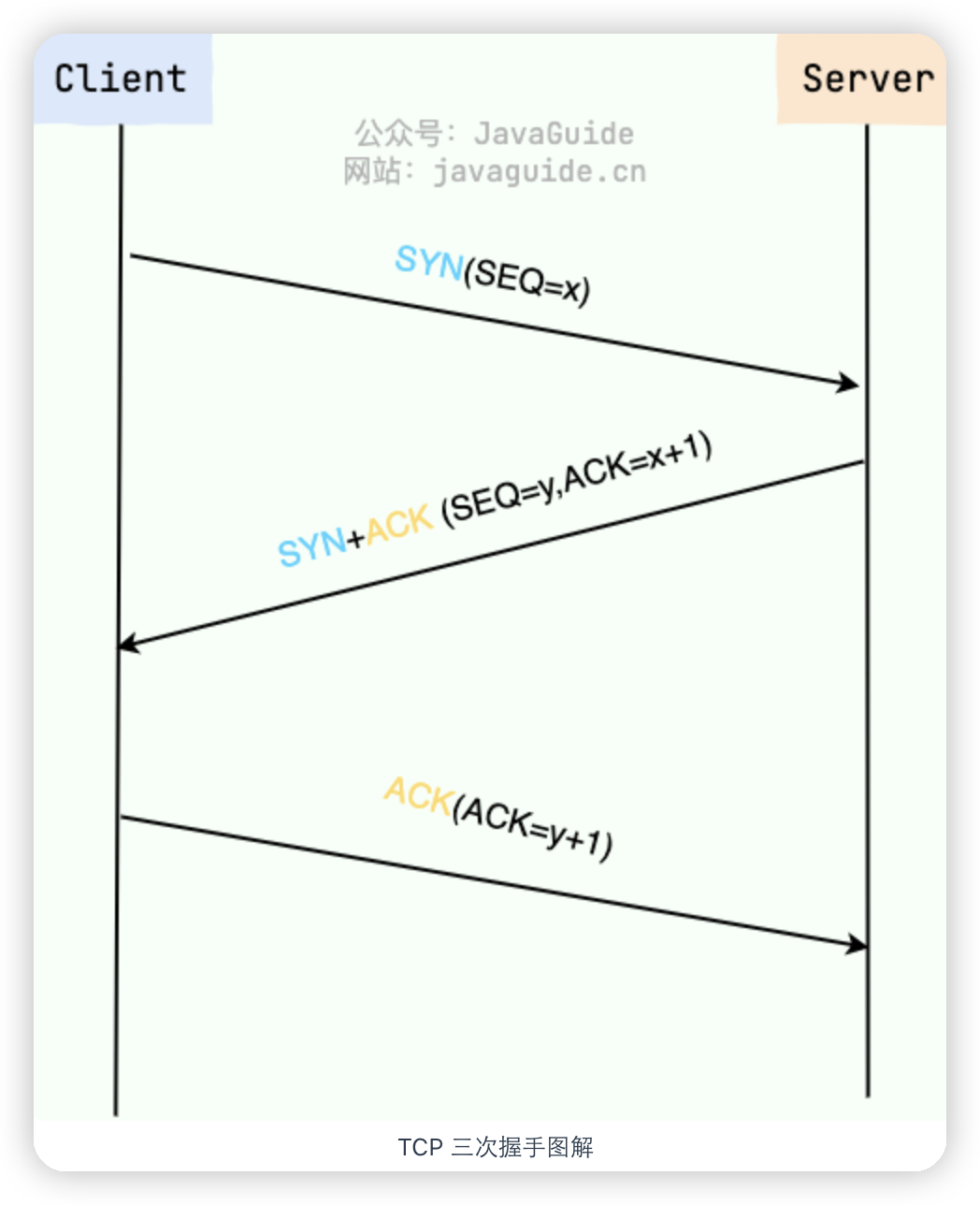
三次握手(Three-way Handshake)是TCP(传输控制协议)用来在两个网络设备之间建立一个可靠的连接的过程。它的目的是同步双方的序列号和确认号,并交换TCP窗口大小信息。三次握手的步骤如下:
第一次握手:SYN
- 发起方发送SYN包:
- 客户端发送一个SYN(同步序列编号)数据包到服务器。这个包含客户端的初始序列号(ISN,Initial Sequence Number),用于开始TCP连接。
- 设置SYN标志位为1,序列号为一个随机值,比如x。
第二次握手:SYN-ACK
- 接收方确认并响应:
- 服务器接收到客户端的SYN包后,需要确认客户端的SYN。
- 服务器发送一个SYN-ACK(同步确认)数据包。该数据包中,SYN标志位仍然为1,ACK(确认)标志位也设置为1,确认号(ACK Number)设为客户端的序列号加1(x+1),同时也发送自己的初始序列号y。
第三次握手:ACK
- 发起方再次确认:
- 客户端接收到服务器的SYN-ACK包后,向服务器发送一个确认包ACK。
- 这个数据包的ACK标志位设为1,序列号设为初始序列号加1(x+1),确认号设为服务器的序列号加1(y+1)。
- 此时,客户端到服务器的连接建立。
整体的思路就是客户端先发一个序列号x,服务器端接收之后为了验证正确,就确认发x+1,保证没问题,同时也发一个y,看客户端能不能准确接收,客户端收到后,也发确认y+1,表示能准确收到
四次挥手
只要四次挥手没有结束,客户端和服务端就可以继续传输数据!
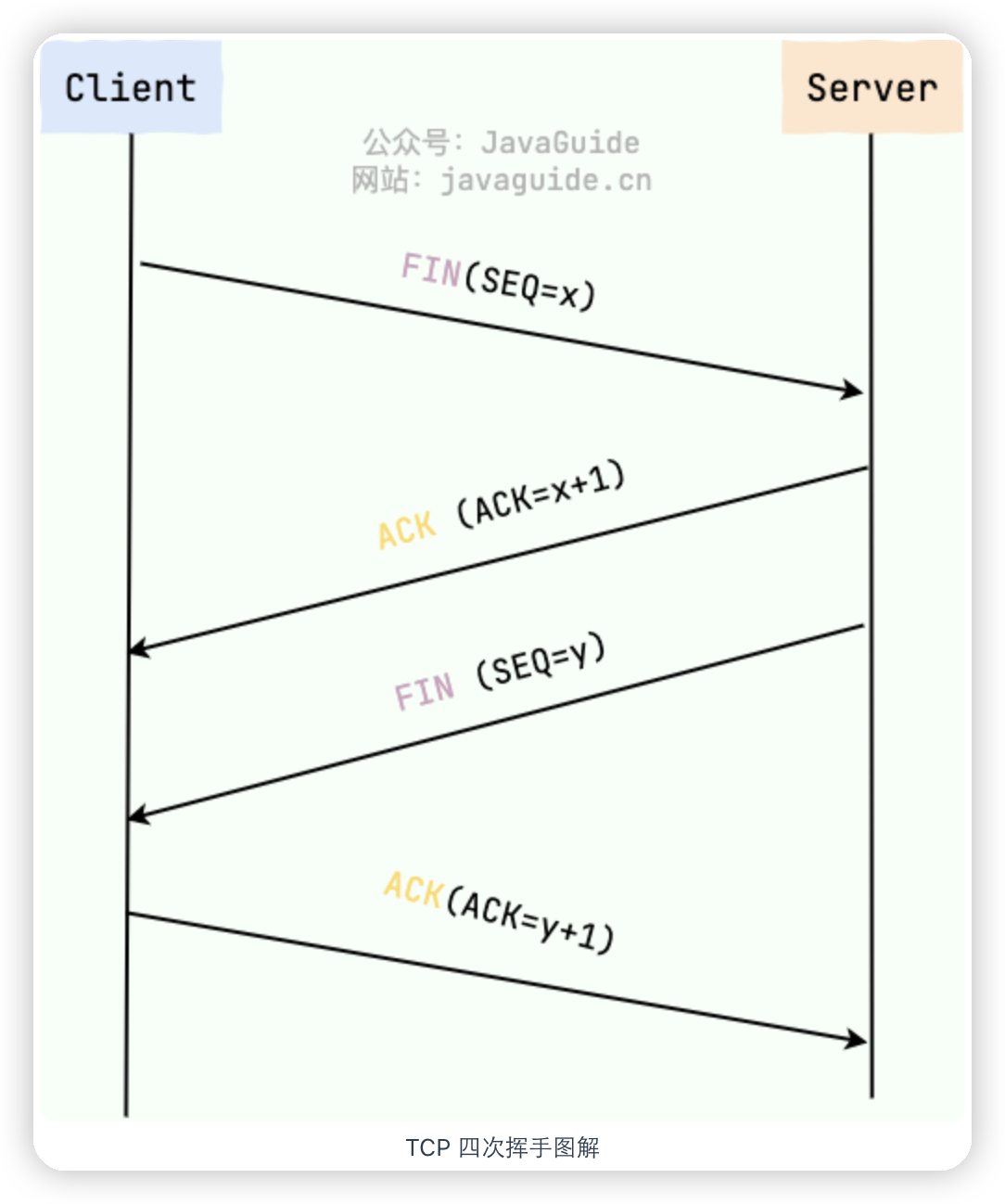
第一次挥手:客户端发送一个 FIN(SEQ=x) 标志的数据包->服务端,用来关闭客户端到服务器的数据传送。然后客户端进入 FIN-WAIT-1 状态。
第二次挥手:服务器收到这个 FIN(SEQ=X) 标志的数据包,它发送一个 ACK (ACK=x+1)标志的数据包->客户端 。然后服务端进入 CLOSE-WAIT 状态,客户端进入 FIN-WAIT-2 状态。
第三次挥手:服务端发送一个 FIN (SEQ=y)标志的数据包->客户端,请求关闭连接,然后服务端进入 LAST-ACK 状态。
第四次挥手:客户端发送 ACK (ACK=y+1)标志的数据包->服务端,然后客户端进入TIME-WAIT状态,服务端在收到 ACK (ACK=y+1)标志的数据包后进入 CLOSE 状态。此时如果客户端等待 2MSL 后依然没有收到回复,就证明服务端已正常关闭,随后客户端也可以关闭连接了。
相比三次握手,区别在于ACK和FIN是分开发送的
因为服务器收到客户端断开连接的请求时,可能还有一些数据没有发完,这时先回复 ACK,表示接收到了断开连接的请求。等到数据发完之后再发 FIN,断开服务器到客户端的数据传送。即一方想断开连接,得到通知后,需要把剩下的发完才行
为什么第四次挥手客户端需要等待 2*MSL(报文段最长寿命)时间后才进入 CLOSED 状态
因为第四次挥手的时候,可能客户端发给服务器端的ACK丢失了,这个时候服务器端会重发FIN,客户端需要等待一段时间,看是否会有FIN,如果有的话,就需要重发,而这个时间就是2*MSL
MSL:一个片段在网络中最大的存活时间,2MSL 就是一个发送和一个回复所需的最大时间。如果直到 2MSL,Client 都没有再次收到 FIN,那么 Client 推断 ACK 已经被成功接收,则结束 TCP 连接
TCP 如何保证传输的可靠性
TCP如果保证传输的可靠性
-
基于数据块传输:应用数据被分割成 TCP 认为最适合发送的数据块,再传输给网络层,数据块被称为报文段或段。
-
对失序数据包重新排序以及去重:TCP 为了保证不发生丢包,就给每个包一个序列号,有了序列号能够将接收到的数据根据序列号排序,并且去掉重复序列号的数据就可以实现数据包去重。
-
校验和 : TCP 将保持它首部和数据的检验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP 将丢弃这个报文段和不确认收到此报文段。
-
超时重传 : 当发送方发送数据之后,它启动一个定时器,等待目的端确认收到这个报文段。接收端实体对已成功收到的包发回一个相应的确认信息(ACK)。如果发送端实体在合理的往返时延(RTT)内未收到确认消息,那么对应的数据包就被假设为已丢失open in new window并进行重传。
-
流量控制 : 因为发送速率和接收速率不一定一样,所以需要使用滑动窗口进行流量控制。
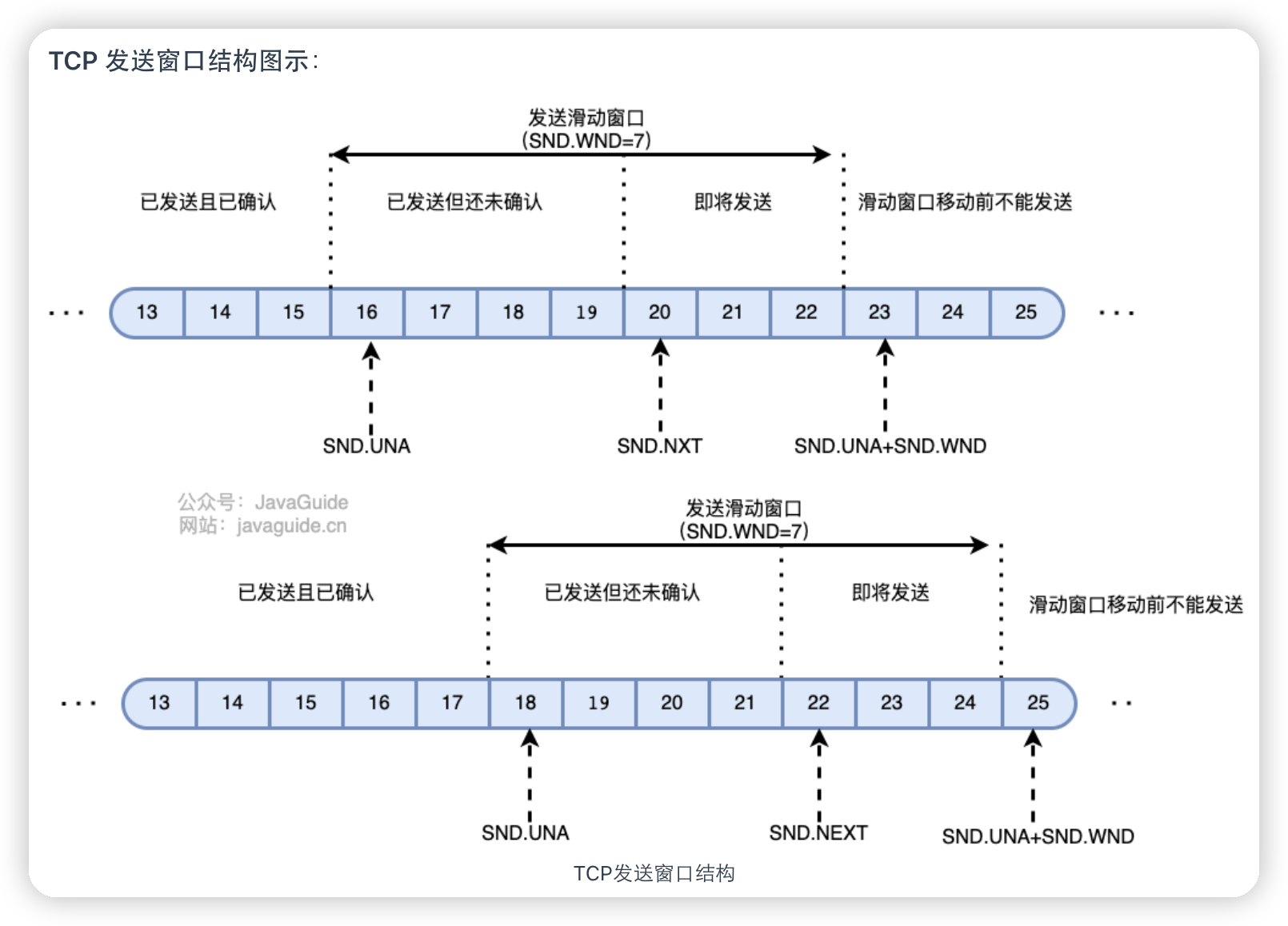
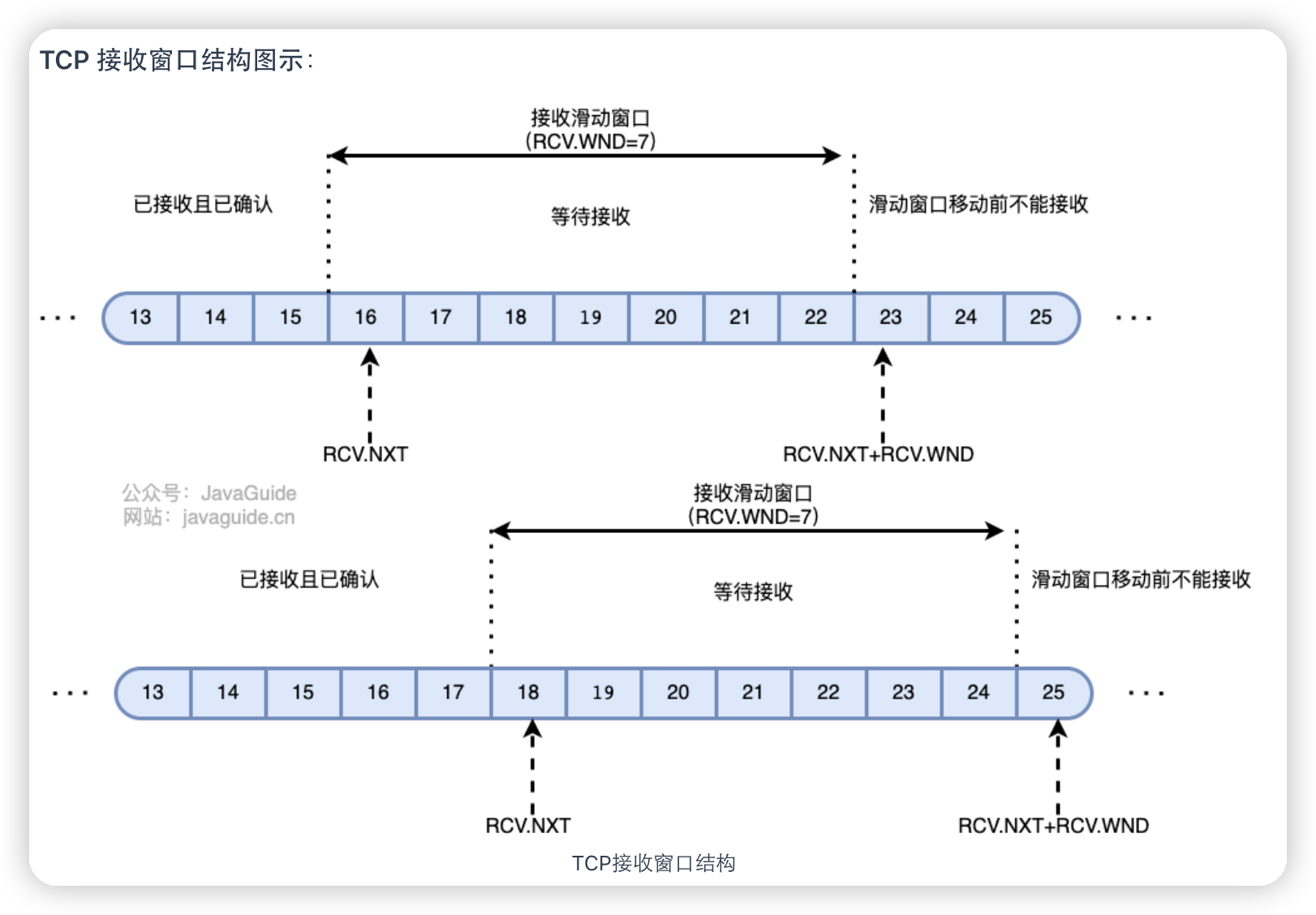 TCP 连接的每一方都有固定大小的缓冲空间,TCP 的接收端只允许发送端发送接收端缓冲区能接纳的数据。当接收方来不及处理发送方的数据,能提示发送方降低发送的速率,防止包丢失。
TCP 连接的每一方都有固定大小的缓冲空间,TCP 的接收端只允许发送端发送接收端缓冲区能接纳的数据。当接收方来不及处理发送方的数据,能提示发送方降低发送的速率,防止包丢失。TCP 使用的流量控制协议是可变大小的滑动窗口协议(TCP 利用滑动窗口实现流量控制)。
-
拥塞控制 : 当网络拥塞时,减少数据的发送。
如果需求大于该资源能够提供的部分,网络性能就会变差,这就叫拥塞,拥塞控制就是防止过多的数据涌入网络中
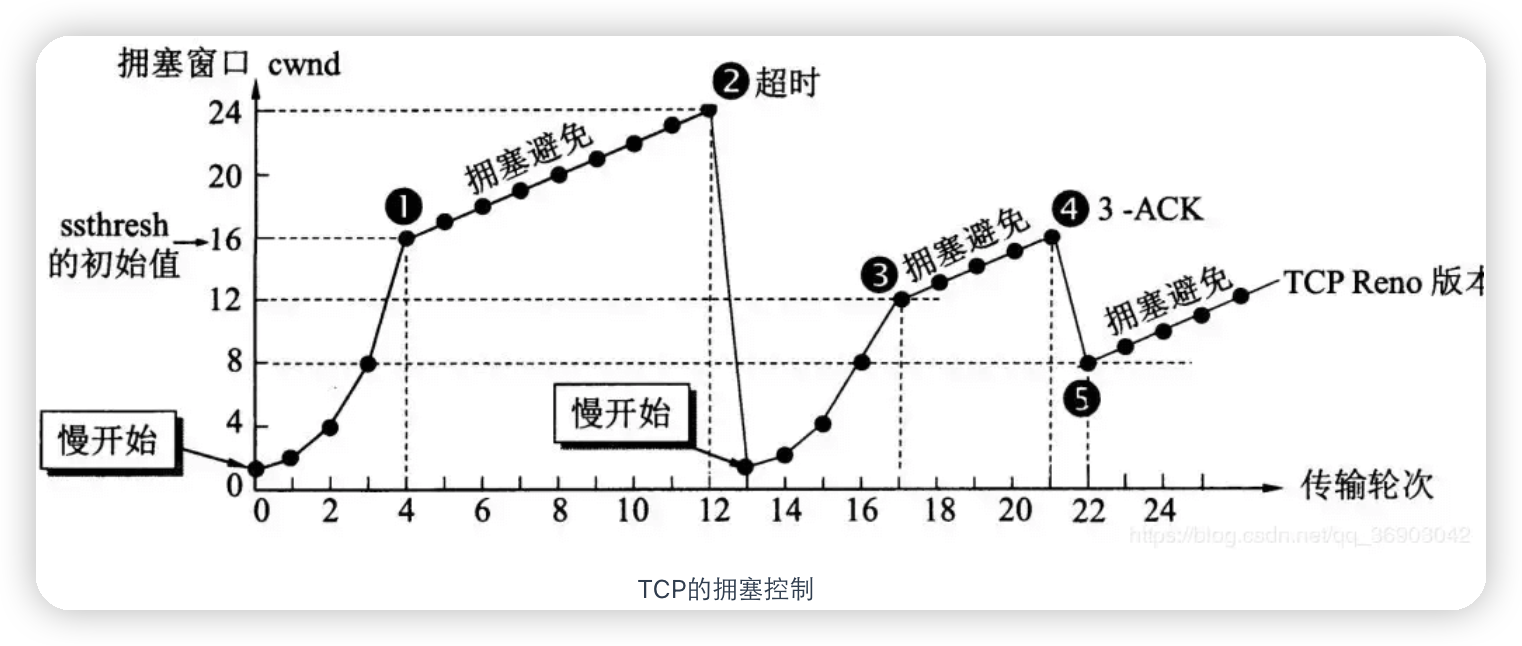
TCP 的拥塞控制采用了四种算法,即 慢开始、 拥塞避免、快重传和快恢复。在网络层也可以使路由器采用适当的分组丢弃策略(如主动队列管理 AQM),以减少网络拥塞的发生。
- 慢开始: 慢开始算法的思路是当主机开始发送数据时,如果立即把大量数据字节注入到网络,那么可能会引起网络阻塞,因为现在还不知道网络的符合情况。经验表明,较好的方法是先探测一下,即由小到大逐渐增大发送窗口,也就是由小到大逐渐增大拥塞窗口数值。cwnd 初始值为 1,每经过一个传播轮次,cwnd 加倍。
- 拥塞避免: 拥塞避免算法的思路是让拥塞窗口 cwnd 缓慢增大,即每经过一个往返时间 RTT 就把发送方的 cwnd 加 1.
- 快重传与快恢复: 在 TCP/IP 中,快速重传和恢复(fast retransmit and recovery,FRR)是一种拥塞控制算法,它能快速恢复丢失的数据包。没有 FRR,如果数据包丢失了,TCP 将会使用定时器来要求传输暂停。在暂停的这段时间内,没有新的或复制的数据包被发送。有了 FRR,如果接收机接收到一个不按顺序的数据段,它会立即给发送机发送一个重复确认。如果发送机接收到三个重复确认,它会假定确认件指出的数据段丢失了,并立即重传这些丢失的数据段。有了 FRR,就不会因为重传时要求的暂停被耽误。 当有单独的数据包丢失时,快速重传和恢复(FRR)能最有效地工作。当有多个数据信息包在某一段很短的时间内丢失时,它则不能很有效地工作。
拥塞控制是一个全局性的过程,涉及到所有的主机,所有的路由器,以及与降低网络传输性能有关的所有因素。
流量控制往往是点对点通信量的控制,是个端到端的问题。流量控制所要做到的就是抑制发送端发送数据的速率,以便使接收端来得及接收。
IP
当网络设备发送 IP 数据包时,数据包中包含了 源 IP 地址 和 目的 IP 地址 。源 IP 地址用于标识数据包的发送方设备或域,而目的 IP 地址则用于标识数据包的接收方设备或域。这类似于一封邮件中同时包含了目的地地址和回邮地址。
IP地址过滤
限制或阻止特定 IP 地址或 IP 地址范围的访问。例如,你有一个图片服务突然被某一个 IP 地址攻击,那我们就可以禁止这个 IP 地址访问图片服务
IPv4 和 IPv6 有什么区别
- 地址长度
- IPv4:
- 使用32位地址长度,通常表示为4个数字的组合,每个数字范围从0到255,例如192.168.0.1。
- IPv6:
- 使用128位地址长度,表示为8组16进制数,每组由4个字符组成,例如2001:0db8:85a3:0000:0000:8a2e:0370:7334。
- IPv4:
- 分组处理和路由
- IPv4:
- 分组处理和路由技术相对成熟,但需要处理碎片化问题。
- IPv6:
- 简化了分组头部结构,提高了处理效率。不允许在互联网中对数据包进行碎片化。
- IPv4:
- 安全性
- IPv4:
- 安全性依赖于应用层实现,如SSL/TLS。
- IPv6:
- 设计时考虑了安全性,内置了IPsec(一种网络层安全协议)的支持。
- IPv4:
- 自动配置能力
- IPv4:
- 需要额外的协议进行地址配置(如DHCP)。
- IPv6:
- 支持无状态地址自动配置(SLAAC),可以自动为设备分配地址。
- IPv4:
NAT
NAT(Network Address Translation,网络地址转换) 主要用于在不同网络之间转换 IP 地址。它允许将私有 IP 地址(如在局域网中使用的 IP 地址)映射为公有 IP 地址(在互联网中使用的 IP 地址)或者反向映射,从而实现局域网内的多个设备通过单一公有 IP 地址访问互联网。
NAT 不光可以缓解 IPv4 地址资源短缺的问题,还可以隐藏内部网络的实际拓扑结构,使得外部网络无法直接访问内部网络中的设备,从而提高了内部网络的安全性。
ARP
MAC地址
MAC 地址的全称是 媒体访问控制地址(Media Access Control Address)。如果说,互联网中每一个资源都由 IP 地址唯一标识(IP 协议内容),那么一切网络设备都由 MAC 地址唯一标识
MAC 地址的长度为 6 字节(48 比特),MAC 地址由 IEEE 统一管理与分配,理论上,一个网络设备中的网卡上的 MAC 地址是永久的。不同的网卡生产商从 IEEE 那里购买自己的 MAC 地址空间(MAC 的前 24 比特),也就是前 24 比特由 IEEE 统一管理,保证不会重复。而后 24 比特,由各家生产商自己管理,同样保证生产的两块网卡的 MAC 地址不会重复。
MAC 地址具有可携带性、永久性,身份证号永久地标识一个人的身份,不论他到哪里都不会改变。而 IP 地址不具有这些性质,当一台设备更换了网络,它的 IP 地址也就可能发生改变,也就是它在互联网中的定位发生了变化

ARP 协议,全称 地址解析协议(Address Resolution Protocol),它解决的是网络层地址和链路层地址之间的转换问题。因为一个 IP 数据报在物理上传输的过程中,总是需要知道下一跳(物理上的下一个目的地)该去往何处,但 IP 地址属于逻辑地址,而 MAC 地址才是物理地址,ARP 协议解决了 IP 地址转 MAC 地址的一些问题。
工作原理
在一个局域网内,每个网络设备都自己维护了一个 ARP 表,ARP 表记录了某些其他网络设备的 IP 地址-MAC 地址映射关系,该映射关系以 <IP, MAC, TTL> 三元组的形式存储。
ARP 表中的映射信息是有生存周期的,典型值为 20 分钟
同一个局域网中MAC寻址
假设当前有如下场景:IP 地址为137.196.7.23的主机 A,想要给同一局域网内的 IP 地址为137.196.7.14主机 B,发送 IP 数据报文
- 主机 A 检索自己的 ARP 表,发现 ARP 表中并无主机 B 的 IP 地址对应的映射条目,也就无从知道主机 B 的 MAC 地址
- 主机 A 将构造一个 ARP 查询分组,并将其广播到所在的局域网中
- 该局域网内每一个设备都会收到该分组,并检查查询分组的接收 IP 地址是否为自己的 IP 地址,如果是,说明查询分组已经到达了主机 B,否则,该查询分组对当前设备无效,丢弃之。
- 主机 B 收到了查询分组之后,验证是对自己的问询,接着构造一个 ARP 响应分组,该分组的目的地只有一个——主机 A,发送给主机 A。同时,主机 B 提取查询分组中的 IP 地址和 MAC 地址信息,在主机B的 ARP 表中构造一条主机 A 的 IP-MAC 映射记录。
- 主机 A 终将收到主机 B 的响应分组,提取出该分组中的 IP 地址和 MAC 地址后,构造映射信息,加入到自己的 ARP 表中
不同局域网中MAC寻址
- 主机 A 查询 ARP 表,期望寻找到目标路由器的本子网接口的 MAC 地址
- 主机 A 未能找到目标路由器的本子网接口的 MAC 地址,将采用 ARP 协议,问询到该 MAC 地址,由于目标接口与主机 A 在同一个子网内,该过程与同一局域网内的 MAC 寻址相同
- 主机 A 获取到目标接口的 MAC 地址后,先构造 IP 数据报,其中源 IP 是 A 的 IP 地址,目的 IP 地址是 B 的 IP 地址,再构造链路层帧,其中源 MAC 地址是 A 的 MAC 地址,目的 MAC 地址是本子网内与路由器连接的接口的 MAC 地址。主机 A 将把这个链路层帧,以单播的方式,发送给目标接口
- 目标接口接收到了主机 A 发过来的链路层帧,解析,根据目的 IP 地址,查询转发表,将该 IP 数据报转发到与主机 B 所在子网相连的接口上
- 路由器接口查询 ARP 表,期望寻找到主机 B 的 MAC 地址
- 路由器接口如未能找到主机 B 的 MAC 地址,将采用 ARP 协议,广播问询,单播响应,获取到主机 B 的 MAC 地址
- 路由器接口将对 IP 数据报重新封装成链路层帧,目标 MAC 地址为主机 B 的 MAC 地址,单播发送,直到目的地
操作系统
操作系统的六大功能:
- 进程和线程的管理:进程的创建、撤销、阻塞、唤醒,进程间的通信等。
- 存储管理:内存的分配和管理、外存(磁盘等)的分配和管理等。
- 文件管理:文件的读、写、创建及删除等。
- 设备管理:完成设备(输入输出设备和外部存储设备等)的请求或释放,以及设备启动等功能。
- 网络管理:操作系统负责管理计算机网络的使用。网络是计算机系统中连接不同计算机的方式,操作系统需要管理计算机网络的配置、连接、通信和安全等,以提供高效可靠的网络服务。
- 安全管理:用户的身份认证、访问控制、文件加密等,以防止非法用户对系统资源的访问和操作。
用户态内核态
根据进程访问资源的特点,可以把进程在系统上的运行分为两个级别
用户态(User Mode) : 用户态运行的进程可以直接读取用户程序的数据,拥有较低的权限。当应用程序需要执行某些需要特殊权限的操作,例如读写磁盘、网络通信等,就需要向操作系统发起系统调用请求,进入内核态。
内核态(Kernel Mode):内核态运行的进程几乎可以访问计算机的任何资源包括系统的内存空间、设备、驱动程序等,不受限制,拥有非常高的权限。当操作系统接收到进程的系统调用请求时,就会从用户态切换到内核态,执行相应的系统调用,并将结果返回给进程,最后再从内核态切换回用户态。
内核态相比用户态拥有更高的特权级别,因此能够执行更底层、更敏感的操作。不过,由于进入内核态需要付出较高的开销(需要进行一系列的上下文切换和权限检查),应该尽量减少进入内核态的次数,以提高系统的性能和稳定性。
用户态和内核态切换的方式
系统调用(Trap):用户态进程 主动 要求切换到内核态的一种方式,主要是为了使用内核态才能做的事情比如读取磁盘资源。系统调用的机制其核心还是使用了操作系统为用户特别开放的一个中断来实现。
中断(Interrupt):当外围设备完成用户请求的操作后,会向 CPU 发出相应的中断信号,这时 CPU 会暂停执行下一条即将要执行的指令转而去执行与中断信号对应的处理程序,如果先前执行的指令是用户态下的程序,那么这个转换的过程自然也就发生了由用户态到内核态的切换。比如硬盘读写操作完成,系统会切换到硬盘读写的中断处理程序中执行后续操作等。
异常(Exception):当 CPU 在执行运行在用户态下的程序时,发生了某些事先不可知的异常,这时会触发由当前运行进程切换到处理此异常的内核相关程序中,也就转到了内核态,比如缺页异常。
系统调用
-
设备管理:完成设备(输入输出设备和外部存储设备等)的请求或释放,以及设备启动等功能。
-
文件管理:完成文件的读、写、创建及删除等功能。
-
进程管理:进程的创建、撤销、阻塞、唤醒,进程间的通信等功能。
-
内存管理:完成内存的分配、回收以及获取作业占用内存区大小及地址等功能。
进程管理
- 进程(Process) 是指计算机中正在运行的一个程序实例。举例:你打开的微信就是一个进程。
- 线程(Thread) 也被称为轻量级进程,更加轻量。多个线程可以在同一个进程中同时执行,并且共享进程的资源比如内存空间、文件句柄、网络连接等。举例:你打开的微信里就有一个线程专门用来拉取别人发你的最新的消息。
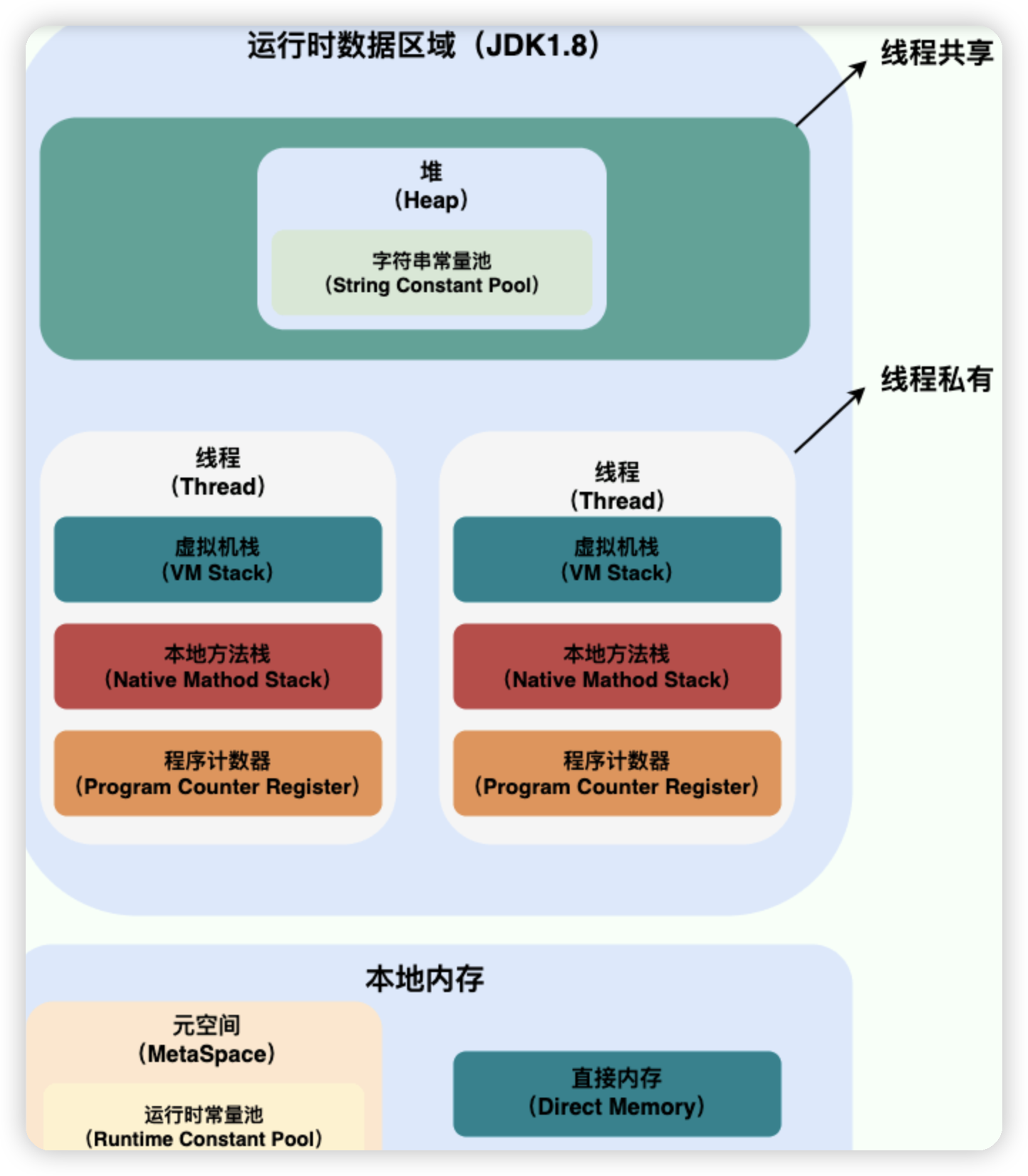
一个进程中可以有多个线程,多个线程共享进程的堆和方法区 (JDK1.8 之后的元空间)*资源,但是每个线程有自己的*程序计数器、虚拟机栈 和 本地方法栈。
总结:
- 线程是进程划分成的更小的运行单位,一个进程在其执行的过程中可以产生多个线程。
- 线程和进程最大的不同在于基本上各进程是独立的,而各线程则不一定,因为同一进程中的线程极有可能会相互影响。
- 线程执行开销小,但不利于资源的管理和保护;而进程正相反。
PCB
进程控制块,是操作系统中用来管理和跟踪进程的数据结构,每个进程都对应着一个独立的 PCB。你可以将 PCB 视为进程的大脑。
当操作系统创建一个新进程时,会为该进程分配一个唯一的进程 ID,并且为该进程创建一个对应的进程控制块。当进程执行时,PCB 中的信息会不断变化,操作系统会根据这些信息来管理和调度进程。
包含以下几个内容:
-
进程的描述信息,包括进程的名称、标识符等等;
-
进程的调度信息,包括进程阻塞原因、进程状态(就绪、运行、阻塞等)、进程优先级(标识进程的重要程度)等等;
-
进程对资源的需求情况,包括 CPU 时间、内存空间、I/O 设备等等。
-
进程打开的文件信息,包括文件描述符、文件类型、打开模式等等。
-
处理机的状态信息(由处理机的各种寄存器中的内容组成的),包括通用寄存器、指令计数器、程序状态字 PSW、用户栈指针。
进程的状态
-
创建状态(new):进程正在被创建,尚未到就绪状态。
-
就绪状态(ready):进程已处于准备运行状态,即进程获得了除了处理器之外的一切所需资源,一旦得到处理器资源(处理器分配的时间片)即可运行。
-
运行状态(running):进程正在处理器上运行(单核 CPU 下任意时刻只有一个进程处于运行状态)。
-
阻塞状态(waiting):又称为等待状态,进程正在等待某一事件而暂停运行如等待某资源为可用或等待 IO 操作完成。即使处理器空闲,该进程也不能运行。
-
结束状态(terminated):进程正在从系统中消失。可能是进程正常结束或其他原因中断退出运行。
进程间通信的方式
- 管道/匿名管道:具有亲缘关系的父子进程间或兄弟进程之间的通信
- 有名管道:匿名管道由于没有名字,只能用于亲缘关系的进程间通信。为了克服这个缺点,提出了有名管道。有名管道严格遵循 先进先出(First In First Out) 。
- 信号:用于通知接收进程某个事件已经发生
- 信号量:信号量是一个计数器,用于多进程对共享数据的访问,信号量的意图在于进程间同步。这种通信方式主要用于解决与同步相关的问题并避免竞争条件
- 共享内存:让多个进程可以访问同一个内存空间,不同进程可以及时看到对方进程对共享数据中数据的更新,如互斥锁或信号量
- 套接字:在客户端和服务器端通过网络进行通信,套接字是支持TCP/IP的网络通信的基本操作单元,可以看做是不同主机之间的进程进行双向通信的端点
进程调度算法
- 先到先服务调度算法(FCFS,First Come, First Served) : 从就绪队列中选择一个最先进入该队列的进程为之分配资源,使它立即执行并一直执行到完成或发生某事件而被阻塞放弃占用 CPU 时再重新调度。
- 短作业优先的调度算法(SJF,Shortest Job First) : 从就绪队列中选出一个估计运行时间最短的进程为之分配资源,使它立即执行并一直执行到完成或发生某事件而被阻塞放弃占用 CPU 时再重新调度。
- 时间片轮转调度算法(RR,Round-Robin) : 时间片轮转调度是一种最古老,最简单,最公平且使用最广的算法。每个进程被分配一个时间段,称作它的时间片,即该进程允许运行的时间。
- 多级反馈队列调度算法(MFQ,Multi-level Feedback Queue):前面介绍的几种进程调度的算法都有一定的局限性。如短进程优先的调度算法,仅照顾了短进程而忽略了长进程 。多级反馈队列调度算法既能使高优先级的作业得到响应又能使短作业(进程)迅速完成。因而它是目前被公认的一种较好的进程调度算法,UNIX 操作系统采取的便是这种调度算法。
- 优先级调度算法(Priority):为每个流程分配优先级,首先执行具有最高优先级的进程,依此类推。具有相同优先级的进程以 FCFS 方式执行。可以根据内存要求,时间要求或任何其他资源要求来确定优先级。
僵尸进程和孤儿进程
- 僵尸进程:子进程已经终止,但是其父进程仍在运行,且父进程没有调用 wait()或 waitpid()等系统调用来获取子进程的状态信息,释放子进程占用的资源,导致子进程的 PCB 依然存在于系统中,但无法被进一步使用。这种情况下,子进程被称为“僵尸进程”。避免僵尸进程的产生,父进程需要及时调用 wait()或 waitpid()系统调用来回收子进程。
- 孤儿进程:一个进程的父进程已经终止或者不存在,但是该进程仍在运行。这种情况下,该进程就是孤儿进程。孤儿进程通常是由于父进程意外终止或未及时调用 wait()或 waitpid()等系统调用来回收子进程导致的。为了避免孤儿进程占用系统资源,操作系统会将孤儿进程的父进程设置为 init 进程(进程号为 1),由 init 进程来回收孤儿进程的资源。
死锁
多个进程/线程同时被阻塞,它们中的一个或者全部都在等待某个资源被释放。由于进程/线程被无限期地阻塞,因此程序不可能正常终止
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
public class DeadLockDemo {
private static Object resource1 = new Object();//资源 1
private static Object resource2 = new Object();//资源 2
public static void main(String[] args) {
new Thread(() -> {
synchronized (resource1) {
System.out.println(Thread.currentThread() + "get resource1");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread() + "waiting get resource2");
synchronized (resource2) {
System.out.println(Thread.currentThread() + "get resource2");
}
}
}, "线程 1").start();
new Thread(() -> {
synchronized (resource2) {
System.out.println(Thread.currentThread() + "get resource2");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread() + "waiting get resource1");
synchronized (resource1) {
System.out.println(Thread.currentThread() + "get resource1");
}
}
}, "线程 2").start();
}
}
解决死锁的方法:
- 预防 是采用某种策略,限制并发进程对资源的请求,从而使得死锁的必要条件在系统执行的任何时间上都不满足。
- 避免则是系统在分配资源时,根据资源的使用情况提前做出预测,从而避免死锁的发生
- 检测是指系统设有专门的机构,当死锁发生时,该机构能够检测死锁的发生,并精确地确定与死锁有关的进程和资源。
- 解除 是与检测相配套的一种措施,用于将进程从死锁状态下解脱出来。
死锁的预防
预防的话,对于死锁的必要条件,条件1和3不好改变,所以可以考虑从2,4中入手
1、静态分配策略
静态分配策略可以破坏死锁产生的第二个条件(占有并等待)。所谓静态分配策略,就是指一个进程必须在执行前就申请到它所需要的全部资源,并且知道它所要的资源都得到满足之后才开始执行。进程要么占有所有的资源然后开始执行,要么不占有资源,不会出现占有一些资源等待一些资源的情况。
静态分配策略逻辑简单,实现也很容易,但这种策略 严重地降低了资源利用率,因为在每个进程所占有的资源中,有些资源是在比较靠后的执行时间里采用的,甚至有些资源是在额外的情况下才使用的,这样就可能造成一个进程占有了一些 几乎不用的资源而使其他需要该资源的进程产生等待 的情况。
2、层次分配策略
层次分配策略破坏了产生死锁的第四个条件(循环等待)。在层次分配策略下,所有的资源被分成了多个层次,一个进程得到某一次的一个资源后,它只能再申请较高一层的资源;当一个进程要释放某层的一个资源时,必须先释放所占用的较高层的资源,按这种策略,是不可能出现循环等待链的,因为那样的话,就出现了已经申请了较高层的资源,反而去申请了较低层的资源,不符合层次分配策略
死锁的避免(银行家算法)
直接破坏条件可能会造成系统的负担加重,所以考虑死锁的避免,即前提上也允许系统中同时存在四个必要条件 ,只要掌握并发进程中与每个进程有关的资源动态申请情况,做出 明智和合理的选择 ,仍然可以避免死锁,因为四大条件仅仅是产生死锁的必要条件。
例如最具有代表性的 避免死锁算法 就是 Dijkstra 的银行家算法,银行家算法用一句话表达就是:当一个进程申请使用资源的时候,银行家算法 通过先 试探 分配给该进程资源,然后通过 安全性算法 判断分配后系统是否处于安全状态,若不安全则试探分配作废,让该进程继续等待,若能够进入到安全的状态,则就 真的分配资源给该进程。
死锁的检测和解除
有点像乐观锁,分配资源的时候不去考虑,等真出问题了,再去解决。
这种方法对资源的分配不加以任何限制,也不采取死锁避免措施,但系统 定时地运行一个 “死锁检测” 的程序,判断系统内是否出现死锁,如果检测到系统发生了死锁,再采取措施去解除它。
死锁的检测
可以通过进程-资源分配图进行死锁的检测:
- 如果进程-资源分配图中无环路,则此时系统没有发生死锁
- 如果进程-资源分配图中有环路,且每个资源类仅有一个资源,则系统中已经发生了死锁。
- 如果进程-资源分配图中有环路,且涉及到的资源类有多个资源,此时系统未必会发生死锁。如果能在进程-资源分配图中找出一个 既不阻塞又非独立的进程 ,该进程能够在有限的时间内归还占有的资源,也就是把边给消除掉了,重复此过程,直到能在有限的时间内 消除所有的边 ,则不会发生死锁,否则会发生死锁。(消除边的过程类似于 拓扑排序)
死锁的解除
- 立即结束所有进程的执行,重新启动操作系统:这种方法简单,但以前所在的工作全部作废,损失很大。
- 撤销涉及死锁的所有进程,解除死锁后继续运行:这种方法能彻底打破死锁的循环等待条件,但将付出很大代价,例如有些进程可能已经计算了很长时间,由于被撤销而使产生的部分结果也被消除了,再重新执行时还要再次进行计算。
- 逐个撤销涉及死锁的进程,回收其资源直至死锁解除。
- 抢占资源:从涉及死锁的一个或几个进程中抢占资源,把夺得的资源再分配给涉及死锁的进程直至死锁解除。
内存管理
主要负责下面这些事情:
-
内存的分配与回收:对进程所需的内存进行分配和释放,malloc 函数:申请内存,free 函数:释放内存。
-
地址转换:将程序中的虚拟地址转换成内存中的物理地址。
-
内存扩充:当系统没有足够的内存时,利用虚拟内存技术或自动覆盖技术,从逻辑上扩充内存。
-
内存映射:将一个文件直接映射到进程的进程空间中,这样可以通过内存指针用读写内存的办法直接存取文件内容,速度更快。
-
内存优化:通过调整内存分配策略和回收算法来优化内存使用效率。
-
内存安全:保证进程之间使用内存互不干扰,避免一些恶意程序通过修改内存来破坏系统的安全性。
内存碎片
- 内部内存碎片(Internal Memory Fragmentation,简称为内存碎片):已经分配给进程使用但未被使用的内存。导致内部内存碎片的主要原因是,当采用固定比例比如 2 的幂次方进行内存分配时,进程所分配的内存可能会比其实际所需要的大。举个例子,一个进程只需要 65 字节的内存,但为其分配了 128(2^7) 大小的内存,那 63 字节的内存就成为了内部内存碎片。
- 外部内存碎片(External Memory Fragmentation,简称为外部碎片):由于未分配的连续内存区域太小,以至于不能满足任意进程所需要的内存分配请求,这些小片段且不连续的内存空间被称为外部碎片。也就是说,外部内存碎片指的是那些并未分配给进程但又不能使用的内存。我们后面介绍的分段机制就会导致外部内存碎片。
内存碎片会导致内存利用率下降,如何减少内存碎片是内存管理要非常重视的一件事情
内存管理的方式可以简单分为下面两种:
- 连续内存管理:为一个用户程序分配一个连续的内存空间
- 非连续内存管理:允许一个程序使用的内存分布在离散或者说不相邻的内存中
连续内存管理
在 Linux 系统中,连续内存管理采用了 伙伴系统(Buddy System)算法 来实现
当进行内存分配时,伙伴系统会尝试找到大小最合适的内存块。如果找到的内存块过大,就将其一分为二,分成两个大小相等的伙伴块。如果还是大的话,就继续切分,直到到达合适的大小为止。假设两块相邻的内存块都被释放,系统会将这两个内存块合并,进而形成一个更大的内存块,以便后续的内存分配。这样就可以减少内存碎片的问题,提高内存利用率。
伙伴系统算法解决了外部内存碎片的问题,但是没有解决内部内存碎片的问题,对于内部内存碎片的问题,Linux 采用 SLAB 进行解决
非连续内存管理
- 段式管理:以段(—段连续的物理内存)的形式管理/分配物理内存。应用程序的虚拟地址空间被分为大小不等的段,段是有实际意义的,每个段定义了一组逻辑信息,例如有主程序段 MAIN、子程序段 X、数据段 D 及栈段 S 等。
- 页式管理:把物理内存分为连续等长的物理页,应用程序的虚拟地址空间也被划分为连续等长的虚拟页,是现代操作系统广泛使用的一种内存管理方式。
- 段页式管理机制:结合了段式管理和页式管理的一种内存管理机制,把物理内存先分成若干段,每个段又继续分成若干大小相等的页。
虚拟内存
计算机系统内存管理非常重要的一个技术,本质上来说它只是逻辑存在的,是一个假想出来的内存空间,主要作用是作为进程访问主存(物理内存)的桥梁并简化内存管理。
段式管理
分段管理通过 段表(Segment Table) 映射虚拟地址和物理地址。
分段机制下的虚拟地址由两部分组成:
- 段号:标识着该虚拟地址属于整个虚拟地址空间中的哪一个段。
- 段内偏移量:相对于该段起始地址的偏移量。
具体步骤如下:
- MMU 首先解析得到虚拟地址中的段号;
- 通过段号去该应用程序的段表中取出对应的段信息(找到对应的段表项);
- 从段信息中取出该段的起始地址(物理地址)加上虚拟地址中的段内偏移量得到最终的物理地址
通过段号一定要找到对应的段表项吗?得到最终的物理地址后对应的物理内存一定存在吗?
不一定。段表项可能并不存在:
- 段表项被删除:软件错误、软件恶意行为等情况可能会导致段表项被删除。
- 段表项还未创建:如果系统内存不足或者无法分配到连续的物理内存块就会导致段表项无法被创建。
分段管理也有可能导致内存外部碎片
分段机制容易出现外部内存碎片,即在段与段之间留下碎片空间(不足以映射给虚拟地址空间中的段)。从而造成物理内存资源利用率的降低。
页式管理
分页机制(Paging) 把主存(物理内存)分为连续等长的物理页,应用程序的虚拟地址空间划也被分为连续等长的虚拟页。现代操作系统广泛采用分页机制。
注意:这里的页是连续等长的,不同于分段机制下不同长度的段
分页管理通过 页表(Page Table) 映射虚拟地址和物理地址
分页机制下的虚拟地址由两部分组成:
- 页号:通过虚拟页号可以从页表中取出对应的物理页号;
- 页内偏移量:物理页起始地址+页内偏移量=物理内存地址。
具体步骤:
- MMU 首先解析得到虚拟地址中的虚拟页号;
- 通过虚拟页号去该应用程序的页表中取出对应的物理页号(找到对应的页表项);
- 用该物理页号对应的物理页起始地址(物理地址)加上虚拟地址中的页内偏移量得到最终的物理地址。
如果是单级页表也存在问题,比如以 32 位的环境为例,虚拟地址空间范围共有 2^32(4G)。假设 一个页的大小是 2^12(4KB),那页表项共有 4G / 4K = 2^20 个。每个页表项为一个地址,占用 4 字节,2^20 * 2^2/1024*1024= 4MB。也就是说一个程序啥都不干,页表大小就得占用 4M。
为了解决这个问题,操作系统引入了 多级页表 ,多级页表对应多个页表,每个页表也前一个页表相关联。32 位系统一般为二级页表,64 位系统一般为四级页表。
这里以二级页表为例进行介绍:二级列表分为一级页表和二级页表。一级页表共有 1024 个页表项,一级页表又关联二级页表,二级页表同样共有 1024 个页表项。二级页表中的一级页表项是一对多的关系,二级页表按需加载(只会用到很少一部分二级页表),进而节省空间占用。
一级页表中的一项对应了二级页表中的一块位置,当进行分配查找的时候就到这一块位置中进行轮询查找
多级页表属于时间换空间的典型场景,利用增加页表查询的次数减少页表占用的空间
为了提高虚拟地址到物理地址的转换速度,操作系统在 页表方案 基础之上引入了 转址旁路缓存(TLB)
使用 TLB 之后的地址翻译流程是这样的:
- 用虚拟地址中的虚拟页号作为 key 去 TLB 中查询;
- 如果能查到对应的物理页的话,就不用再查询页表了,这种情况称为 TLB 命中(TLB hit)。
- 如果不能查到对应的物理页的话,还是需要去查询主存中的页表,同时将页表中的该映射表项添加到 TLB 中,这种情况称为 TLB 未命中(TLB miss)。
- 当 TLB 填满后,又要登记新页时,就按照一定的淘汰策略淘汰掉快表中的一个页。
页面置换算法
页缺失
硬性页缺失(Hard Page Fault):物理内存中没有对应的物理页。于是,Page Fault Handler 会指示 CPU 从已经打开的磁盘文件中读取相应的内容到物理内存,而后交由 MMU 建立相应的虚拟页和物理页的映射关系。
软性页缺失(Soft Page Fault):物理内存中有对应的物理页,但虚拟页还未和物理页建立映射。于是,Page Fault Handler 会指示 MMU 建立相应的虚拟页和物理页的映射关系。
当发生硬性页缺失的时候,可以考虑页面置换算法,淘汰一个页面置换出新的页面进行使用
常见的页面置换算法
-
最佳页面置换算法(OPT,Optimal):优先选择淘汰的页面是以后永不使用的,或者是在最长时间内不再被访问的页面,这样可以保证获得最低的缺页率。但由于人们目前无法预知进程在内存下的若干页面中哪个是未来最长时间内不再被访问的,因而该算法无法实现,只是理论最优的页面置换算法,可以作为衡量其他置换算法优劣的标准。
-
先进先出页面置换算法(FIFO,First In First Out) : 最简单的一种页面置换算法,总是淘汰最先进入内存的页面,即选择在内存中驻留时间最久的页面进行淘汰。该算法易于实现和理解,一般只需要通过一个 FIFO 队列即可需求。不过,它的性能并不是很好。
-
最近最久未使用页面置换算法(LRU ,Least Recently Used):LRU 算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 T,当须淘汰一个页面时,选择现有页面中其 T 值最大的,即最近最久未使用的页面予以淘汰。LRU 算法是根据各页之前的访问情况来实现,因此是易于实现的。OPT 算法是根据各页未来的访问情况来实现,因此是不可实现的。
-
最少使用页面置换算法(LFU,Least Frequently Used) : 和 LRU 算法比较像,不过该置换算法选择的是之前一段时间内使用最少的页面作为淘汰页。
-
时钟页面置换算法(Clock):可以认为是一种最近未使用算法,即逐出的页面都是最近没有使用的那个。
分页分段的区别和联系
共同点:
- 都是非连续内存管理的方式。
- 都采用了地址映射的方法,将虚拟地址映射到物理地址,以实现对内存的管理和保护。
区别:
- 分页机制以页面为单位进行内存管理,而分段机制以段为单位进行内存管理。页的大小是固定的,由操作系统决定,通常为 2 的幂次方。而段的大小不固定,取决于我们当前运行的程序。
- 页是物理单位,即操作系统将物理内存划分成固定大小的页面,每个页面的大小通常是 2 的幂次方,例如 4KB、8KB 等等。而段则是逻辑单位,是为了满足程序对内存空间的逻辑需求而设计的,通常根据程序中数据和代码的逻辑结构来划分。
- 页机制解决了外部内存碎片的问题,但仍然可能会出现内部内存碎片。
- 分页机制采用了页表来完成虚拟地址到物理地址的映射,页表通过一级页表和二级页表来实现多级映射;而分段机制则采用了段表来完成虚拟地址到物理地址的映射,每个段表项中记录了该段的起始地址和长度信息。
- 分页机制对程序没有任何要求,程序只需要按照虚拟地址进行访问即可;而分段机制需要程序员将程序分为多个段,并且显式地使用段寄存器来访问不同的段。
段页管理
当程序访问某个地址时,首先通过段表将段号转换为段基址,然后将段内偏移与基址相加得到线性地址。接着,通过页表将线性地址转换为物理地址。
这种方法实际上进行了两次映射:首先是段的映射,然后是页的映射
局部性原理
局部性原理是指在程序执行过程中,数据和指令的访问存在一定的空间和时间上的局部性特点。其中,时间局部性是指一个数据项或指令在一段时间内被反复使用的特点,空间局部性是指一个数据项或指令在一段时间内与其相邻的数据项或指令被反复使用的特点。
时间局部性:由于程序中存在一定的循环或者重复操作,因此会反复访问同一个页或一些特定的页,这就体现了时间局部性的特点。为了利用时间局部性,分页机制中通常采用缓存机制来提高页面的命中率,即将最近访问过的一些页放入缓存中,如果下一次访问的页已经在缓存中,就不需要再次访问内存,而是直接从缓存中读取。
空间局部性:由于程序中数据和指令的访问通常是具有一定的空间连续性的,因此当访问某个页时,往往会顺带访问其相邻的一些页。为了利用空间局部性,分页机制中通常采用预取技术来预先将相邻的一些页读入内存缓存中,以便在未来访问时能够直接使用,从而提高访问速度。
在分页机制中,利用时间局部性和空间局部性,采用缓存和预取技术,可以提高页面的命中率,从而提高内存访问效率
文件系统
文件系统主要负责管理和组织计算机存储设备上的文件和目录
- 存储管理:将文件数据存储到物理存储介质中,并且管理空间分配,以确保每个文件都有足够的空间存储,并避免文件之间发生冲突。
- 文件管理:文件的创建、删除、移动、重命名、压缩、加密、共享等等。
- 目录管理:目录的创建、删除、移动、重命名等等。
- 文件访问控制:管理不同用户或进程对文件的访问权限,以确保用户只能访问其被授权访问的文件,以保证文件的安全性和保密性。
文件链接(File Link)是一种特殊的文件类型,可以在文件系统中指向另一个文件。常见的文件链接类型有两种:
1、硬链接(Hard Link)
- 在 Linux/类 Unix 文件系统中,每个文件和目录都有一个唯一的索引节点(inode)号,用来标识该文件或目录。硬链接通过 inode 节点号建立连接,硬链接和源文件的 inode 节点号相同,两者对文件系统来说是完全平等的(可以看作是互为硬链接,源头是同一份文件),删除其中任何一个对另外一个没有影响,可以通过给文件设置硬链接文件来防止重要文件被误删。
- 只有删除了源文件和所有对应的硬链接文件,该文件才会被真正删除。
- 硬链接具有一些限制,不能对目录以及不存在的文件创建硬链接,并且,硬链接也不能跨越文件系统。
ln命令用于创建硬链接。
2、软链接(Symbolic Link 或 Symlink)
- 软链接和源文件的 inode 节点号不同,而是指向一个文件路径。
- 源文件删除后,软链接依然存在,但是指向的是一个无效的文件路径。
- 软连接类似于 Windows 系统中的快捷方式。
- 不同于硬链接,可以对目录或者不存在的文件创建软链接,并且,软链接可以跨越文件系统。
ln -s命令用于创建软链接。
硬链接为什么不能跨文件系统
硬链接是通过 inode 节点号建立连接的,而硬链接和源文件共享相同的 inode 节点号,由于每个文件系统都有自己的独立 inode 表,且每个 inode 表只维护该文件系统内的 inode。如果在不同的文件系统之间创建硬链接,可能会导致 inode 节点号冲突的问题,即目标文件的 inode 节点号已经在该文件系统中被使用。
磁盘调度算法
磁盘调度算法是操作系统中对磁盘访问请求进行排序和调度的算法,其目的是提高磁盘的访问效率。
-
先来先服务算法(First-Come First-Served,FCFS):按照请求到达磁盘调度器的顺序进行处理,先到达的请求的先被服务。FCFS 算法实现起来比较简单,不存在算法开销。不过,由于没有考虑磁头移动的路径和方向,平均寻道时间较长。同时,该算法容易出现饥饿问题,即一些后到的磁盘请求可能需要等待很长时间才能得到服务。
-
最短寻道时间优先算法(Shortest Seek Time First,SSTF):也被称为最佳服务优先(Shortest Service Time First,SSTF)算法,优先选择距离当前磁头位置最近的请求进行服务。SSTF 算法能够最小化磁头的寻道时间,但容易出现饥饿问题,即磁头附近的请求不断被服务,远离磁头的请求长时间得不到响应。实际应用中,需要优化一下该算法的实现,避免出现饥饿问题。
-
扫描算法(SCAN):也被称为电梯(Elevator)算法,基本思想和电梯非常类似。磁头沿着一个方向扫描磁盘,如果经过的磁道有请求就处理,直到到达磁盘的边界,然后改变移动方向,依此往复。SCAN 算法能够保证所有的请求得到服务,解决了饥饿问题。但是,如果磁头从一个方向刚扫描完,请求才到的话。这个请求就需要等到磁头从相反方向过来之后才能得到处理。
-
循环扫描算法(Circular Scan,C-SCAN):SCAN 算法的变体,只在磁盘的一侧进行扫描,并且只按照一个方向扫描,直到到达磁盘边界,然后回到磁盘起点,重新开始循环。
- 边扫描边观察算法(LOOK):SCAN 算法中磁头到了磁盘的边界才改变移动方向,这样可能会做很多无用功,因为磁头移动方向上可能已经没有请求需要处理了。LOOK 算法对 SCAN 算法进行了改进,如果磁头移动方向上已经没有别的请求,就可以立即改变磁头移动方向,依此往复。也就是边扫描边观察指定方向上还有无请求,因此叫 LOOK。
- 均衡循环扫描算法(C-LOOK):C-SCAN 只有到达磁盘边界时才能改变磁头移动方向,并且磁头返回时也需要返回到磁盘起点,这样可能会做很多无用功。C-LOOK 算法对 C-SCAN 算法进行了改进,如果磁头移动的方向上已经没有磁道访问请求了,就可以立即让磁头返回,并且磁头只需要返回到有磁道访问请求的位置即可。