FCN
首个端到端的针对像素级的全卷积网络
FCN的思想
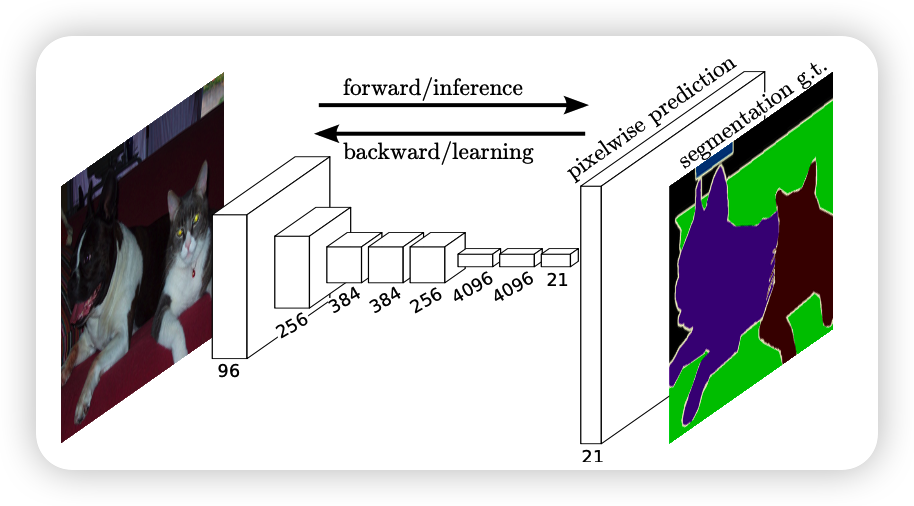
一般使用的分类网络会在最后添加几个全连接层,将多维转化为一维,然后利用softmax得到最后的结果,语义分割要得到的是分割图,所以最后不能要全连接接层
将深层次粗糙的信息和浅层次精细的信息相融合,定义了一种新的“跳过”架构,将深度、粗略的语义信息和浅层、精细的外观信息结合在一起
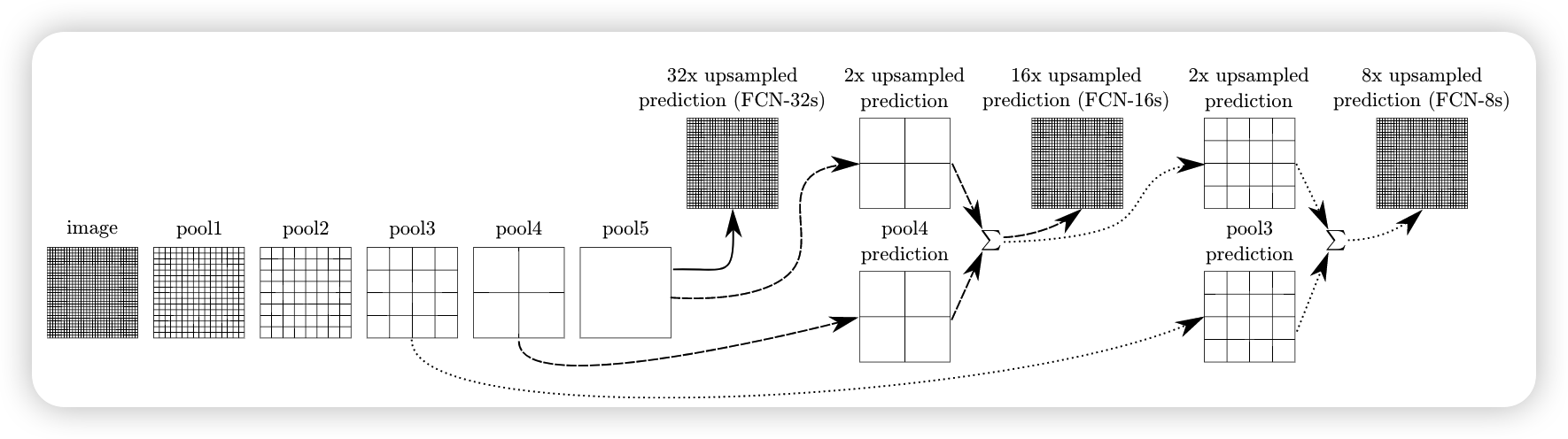
fcn使用vgg作为backbone,将其最后的全连接层改成了几个卷积层,然后进行上采样
对原图像进行卷积conv1、pool1后原图像缩小为1/2;之后对图像进行第二次conv2、pool2后图像缩小为1/4;接着继续对图像进行第三次卷积操作conv3、pool3缩小为原图像的1/8,此时保留pool3的featureMap;接着继续对图像进行第四次卷积操作conv4、pool4,缩小为原图像的1/16,保留pool4的featureMap;最后对图像进行第五次卷积操作conv5、pool5,缩小为原图像的1/32,然后把原来CNN操作中的全连接变成卷积操作conv6、conv7,图像的featureMap数量改变但是图像大小依然为原图的1/32,此时图像不再叫featureMap而是叫heatMap,然后将不同池化层的结果进行上采样,然后对这些结果进行结合输出,分别得到FCN-32s,FCN-16s,FCN-8s
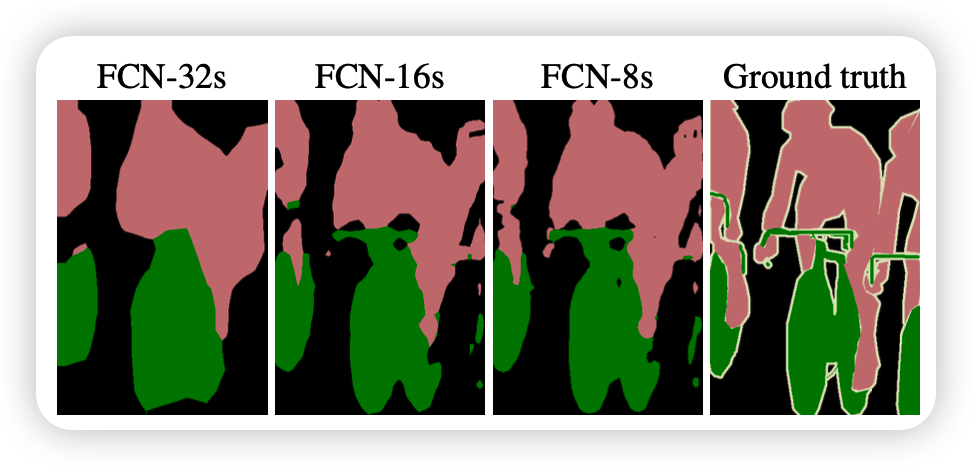
FCN-8s过程
conv7经过一次4x upsample,即使用一个卷积层,特征图输出大小为conv7的4倍,所得4x conv7的大小为4x4。然后pool4需要一次2x upsample,变成2x pool4,大小也为4x4。再把4x conv7,2x pool4与pool3进行fuse,得到求和后的特征图。最后增加一个卷积层,使得输出图片大小为pool3的8倍,也就是8x upsampled prediction的过程,得到一个end to end的图像。实验表明FCN-8s优于FCN-16s,FCN-32s。
缺点:
在使用五个pooling层之后,面积已经缩小32倍了,对于第六次卷积
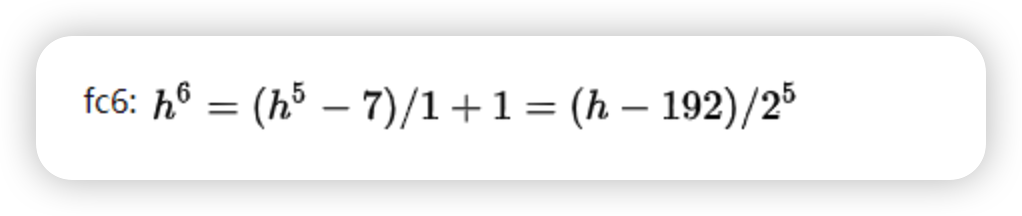
所以如果输入图片面积小于192就不行,所以刚开始就添加padding=100,但会引入很大噪声,但就无法保证像原理图上的1/2,在特征融合时,无法保证feature map一样大,所以要引入crop层进行裁剪
####