U-Net
Motivation
- 普遍认为训练深度学习需要大量的数据集
- 在医学影像领域,没有这么多数据集,Ciresan等人在滑动窗口设置中训练了一个网络,通过在像素周围提供一个局部区域(patch)来预测每个像素的类别,但运算量太大,且很冗余
Contribution
- 基于FCN提出的U-net能够仅仅依靠数据增强,就能实现很好的分割效果
- 提出了包含Contracting和Expansive的对称U形结构,并且Expansive的过程中因为有大量的特征通道,这允许网络将上下文信息传播到更高分辨率的层
- 为了能够预测边界区域的像素,采用了镜像的方式,来补充数据
- 通过对图像进行弹性形变来进行数据增强
- 在损失函数中使用加权损失,即给贴近边界点的像素更高的权重,来使分割更明显
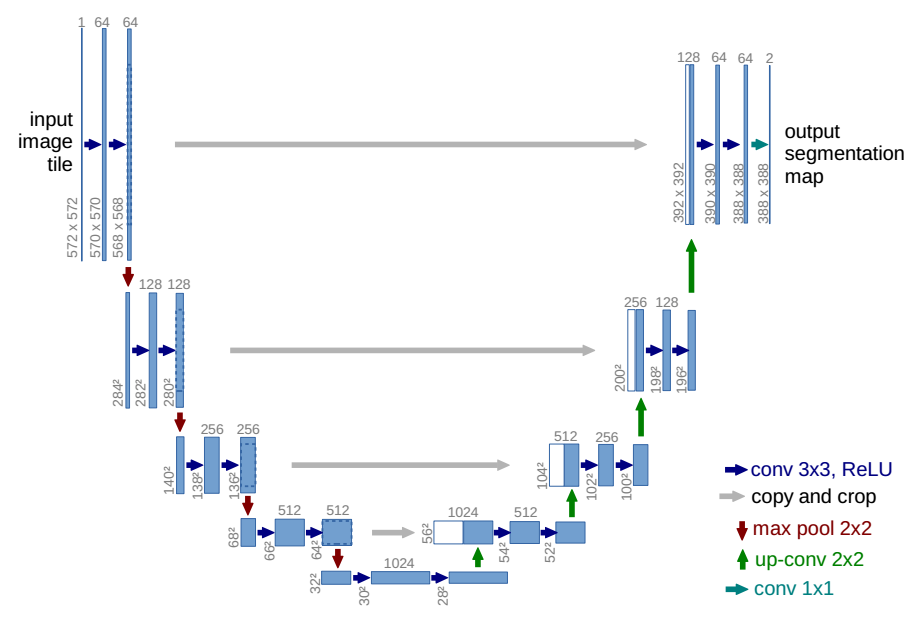
Architecture
-
包括一条Contracting路径和一条Expansive路径。收缩路径遵循卷积网络的典型架构。
-
由两个3x3卷积(未填充卷积)的重复应用组成,每个卷积后面都有一个整流线性单元(ReLU)和一个2x2 max池化操作
-
对于池化操作,步幅为2,用于下采样。在每个降采样步骤中,将特征通道的数量加倍
-
扩展路径中的每一步都包括特征映射的上采样,然后与压缩路径对应拼接,注意因为尺寸不同,所以需要进行裁剪
-
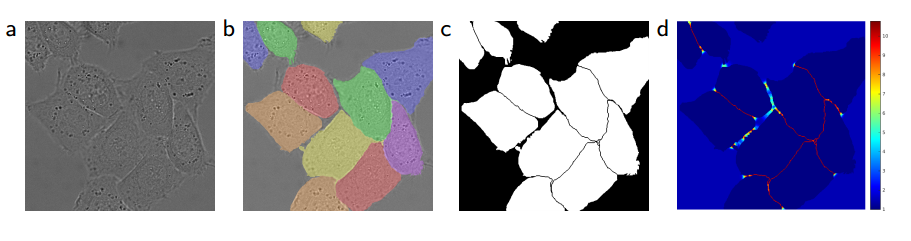
最后是两个特征层,前景(Foreground)代表图像中感兴趣的目标区域或对象,通常是我们希望模型准确分割和识别的区域。
背景(Background)是指与前景相对应的其他部分,即前景以外的图像区域。背景通常包括不感兴趣的图像区域在语义分割任务中,背景的准确分割同样重要,因为它提供了有关前景目标形状和位置的上下文信息。
镜像操作
给输入的图像加对称的边,对于边的宽度,由感受野确定,希望边界点能保留Feature Map
原始图像:512*512
边宽度:
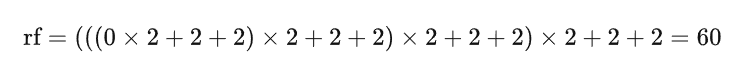
输入图像:512+60=572
损失函数
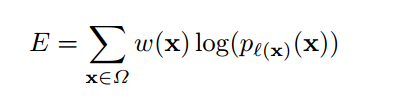
log里面的是每个像素点的损失函数,w(x)是对应的权重
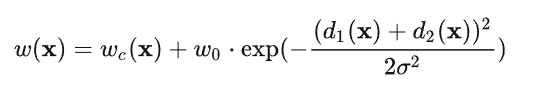
d是像素点离最近细胞的距离,由这个公式可以看出来像素点离细胞越近,其权重越大
Dice Loss
Dice系数是一种用于评估两个样本相似性的度量函数,在图像分割任务中,每个像素需要被分配一个标签,表示其属于哪个类别。Dice Loss通过比较预测的分割结果和真实标签之间的重叠区域来衡量它们的相似度,其值越大意味着这两个样本越相似。
Dice系数的数学表达式如下:
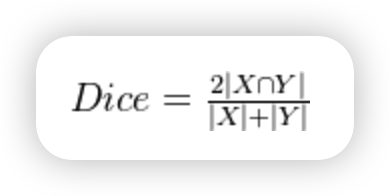
Dice Loss表达式如下:
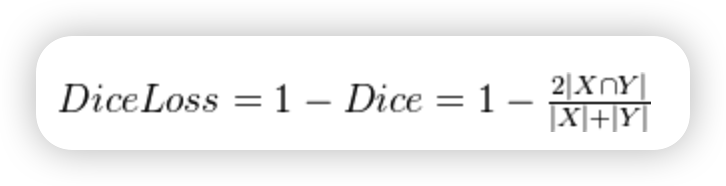
X表示真实分割图像的像素标签,Y表示模型预测分割图像的像素类别
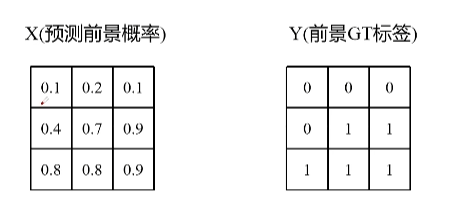
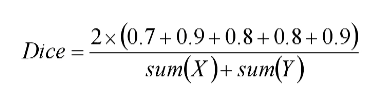
Dice Loss在图像分割任务中得到广泛应用,特别是对于不平衡类别和小目标的分割任务效果较好。它可以作为替代交叉熵损失函数的选择,用于训练分割模型并提高模型的性能。
High Light
- 因为是拼接,所以上采样的时候也有很多特征层,可以有更多的信息传递到分辨率更高的层
- 没有全连接层,不会丢失空间信息,可以进行像素级预测,下采样可以获取更高层次的信息,然后通过skip去融合
- 对于边缘数据,采用镜像输入图像,来弥补缺失的部分
- 采用损失加权
Issue
-
为什么经过的3*3的卷积,不加padding来使得尺寸不变
后来的人实现就用的padding,然后在其基础上加上了bn模块
-
为什么u-net网络就不需要大量的数据集
- 数据增强
- 多次下采样,不同尺度的信息相融合,获取了足够多的信息