DeepLabv3+
Motivation
- 尽管在encode的最后阶段获取了丰富的语义分割信息,但是由于池化或卷积的步长操作,导致细节信息的缺失,使用膨胀卷积虽然能够缓解,但当下采样几倍之后的的计算量是很大的
- encoder-decoder模型在encoder的时候计算更快,在decoder的时候能够逐渐回复清晰的边界,所以尝试将两者进行结合
- 语义分割的两大问题,多尺度信息问题和图像进行下采样之后造成的细节信息损失的问题
Contribution
- 提出了一种新的encoder—decoder的结构,即使用deeplabv3作为encoder模块,使用了一个简单且有效的decoder模块
- 在本文的结构中,通过膨胀卷积能够实现任意控制encoder提取特征的分辨率
- 将Xception模块用于分割任务,并应用depthwise separable convolution在aspp和decoder结构中
Architecture
本文中用到的几个结构如下:
Atrous convolution
在膨胀卷积中,卷积核在采样输入数据时不再直接相邻,而是通过膨胀率来设定采样间隔。膨胀率定义了在输入数据的每个维度上卷积核中相邻元素之间的距离。膨胀率为1时,膨胀卷积即为传统卷积。
通过调整膨胀率,膨胀卷积能够以较小的卷积核尺寸捕捉更大范围的上下文信息,同时有效减少了模型的参数量。例如,在语义分割任务中,使用膨胀卷积可以在感受野较大的情况下保持较高的分辨率。
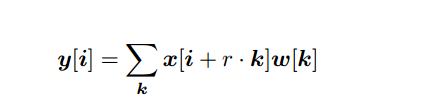
Depthwise separable convolution
深度可分离卷积是一种用于卷积神经网络的卷积操作,旨在减少模型的参数量和计算量,从而提高模型的效率和速度。它由两个步骤组成:深度卷积(depthwise convolution)和逐点卷积(pointwise convolution)
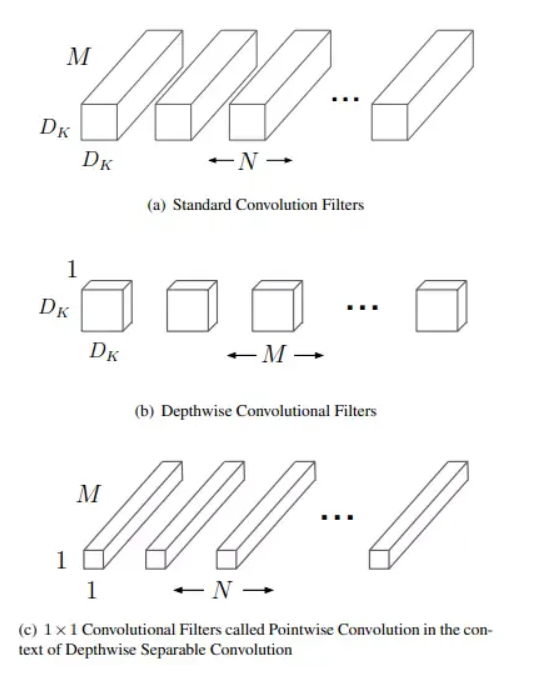
对于标准卷积图a而言 \(输入特征图尺寸D_F*D_F*M,卷积核大小为D_K*D_K*M,输出特征为D_F*D_F*N, 则标准卷积参数量为(D_K*D_K*M)*N\) 对于深度可分离卷积图bc而言
depthwise convolution \(输入特征图尺寸D_F*D_F*M,卷积核大小为D_K*D_K*M,参数数量为D_K*D_K*M\) pointwise convolution \(卷积核大小为1*1*M*N,参数数量为1*1*M*N\) 所以Depthwise separable convolution参数数量为 \(D_K*D_K*M+M*N\) 所以深度卷积的参数数量 / 标准卷积 \(\frac{Depthwise Separable}{standard}=\frac{D_K*D_K*M+M*N}{(D_K*D_K*M)*N}=\frac{1}{N}+\frac{1}{D_K^2}\) Xception网络
Xception模型中的depthwise separable convolution和普通的不太一样,普通的depthwise separable convolution是先进行3x3操作再进行1x1操作(就好像mobileNet中的一样),而Xception模型中则是先进行1x1操作然后再进行3x3操作,中间为了保证数据不被破坏,没有添加relu层,而mobileNet添加了relu层。
对于Xception模型而言,其一共可以分为3个flow,分别是Entry flow、Middle flow、Exit flow
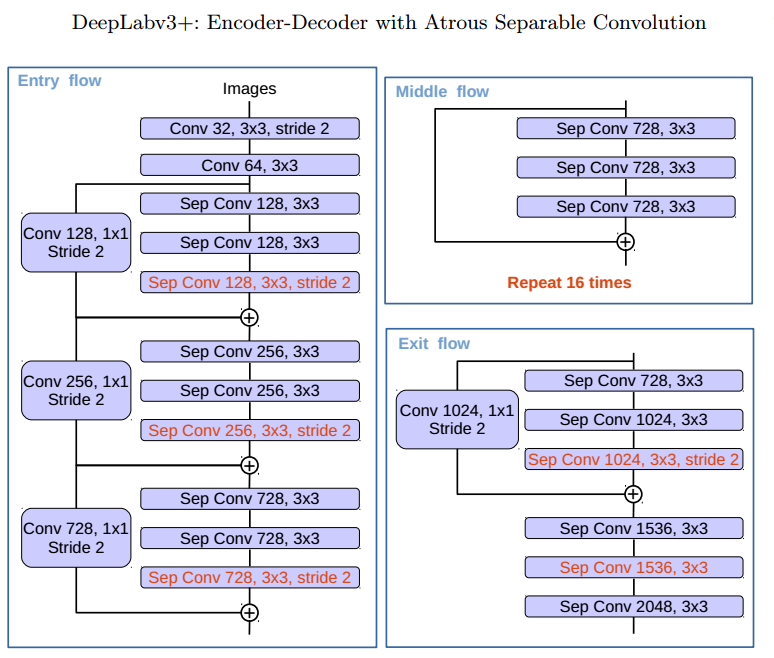
与原有的Xception相比,有如下改进:
- 更深的Xception结构,不同的地方在于不修改entry flow network的结构,为了快速计算和有效的使用内存
- 所有的max pooling结构被stride=2的深度可分离卷积代替
- 每个3x3的depthwise convolution都跟BN和Relu
output stride
是指在进行特征提取过程中,相邻两个输入像素之间的距离与相邻两个输出特征图像素之间的距离之比。较大的输出步幅意味着特征图的尺寸相对于输入图像的尺寸会减小。
下采样的目的是将输入图像的空间分辨率降低,同时保留更高级别的语义信息。可以将输入图像的尺寸减小,并相应地减少特征图的尺寸。
好处:
- 减少计算量:通过降低特征图的分辨率,可以减少后续操作中的计算量
- 扩大感受野:下采样可以扩大每个像素点的感受野,即模型可以”看到”更广阔范围内的上下文信息
- 提取更高层次的语义信息:下采样会消除较低层次的细节信息,从而使模型更关注图像的整体结构和语义内容
坏处:
- 信息丢失:较高的下采样倍数会显著减小输入图像的尺寸,从而丢失了更多的细节信息
- 空间分辨率低:过度下采样会导致特征图的空间分辨率相对较低,从而在进行上采样或反卷积操作时可能无法恢复精细的分割结果
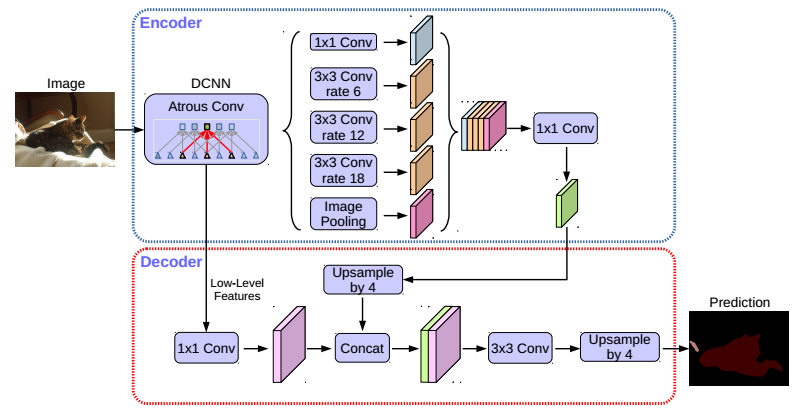
Deeplabv3+结构图
backbone
DeeplabV3+在论文中采用的是Xception系列作为主干特征提取网络,下面代码用的是使用mobilenetv2,mobilenetv2使用的是Inverted resblock,整个mobilenetv2都由Inverted resblock组成
Inverted resblock
Inverted resblock可以分为两个部分:
左边是主干部分,首先利用1x1卷积进行升维,然后利用3x3深度可分离卷积进行特征提取,然后再利用1x1卷积降维
右边是残差边部分,输入和输出直接相接

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
class InvertedResidual(nn.Module):
def __init__(self, inp, oup, stride, expand_ratio):
super(InvertedResidual, self).__init__()
self.stride = stride
assert stride in [1, 2]
hidden_dim = round(inp * expand_ratio)
self.use_res_connect = self.stride == 1 and inp == oup
# 如果不对输入进来的特征层进行升维的话,就将expand_ratio设为1,否则通过1x1卷积进行通道数的上升
if expand_ratio == 1:
self.conv = nn.Sequential(
# --------------------------------------------#
# 进行3x3的逐层卷积,进行跨特征点的特征提取
# --------------------------------------------#
nn.Conv2d(hidden_dim, hidden_dim, 3, stride, 1, groups=hidden_dim, bias=False),
BatchNorm2d(hidden_dim),
nn.ReLU6(inplace=True),
# -----------------------------------#
# 利用1x1卷积进行通道数的调整
# -----------------------------------#
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
BatchNorm2d(oup),
)
else:
self.conv = nn.Sequential(
# -----------------------------------#
# 利用1x1卷积进行通道数的上升,让网络具有更好的特征表征能力
# -----------------------------------#
nn.Conv2d(inp, hidden_dim, 1, 1, 0, bias=False),
BatchNorm2d(hidden_dim),
nn.ReLU6(inplace=True),
# --------------------------------------------#
# 进行3x3的逐层卷积,进行跨特征点的特征提取
# --------------------------------------------#
nn.Conv2d(hidden_dim, hidden_dim, 3, stride, 1, groups=hidden_dim, bias=False),
BatchNorm2d(hidden_dim),
nn.ReLU6(inplace=True),
# -----------------------------------#
# 利用1x1卷积进行通道数的下降,让网络计算更小
# -----------------------------------#
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
BatchNorm2d(oup),
)
def forward(self, x):
# 如果使用了残差边,则进行相加
if self.use_res_connect:
return x + self.conv(x)
else:
return self.conv(x)
class MobileNetV2(nn.Module):
def __init__(self, n_class=1000, input_size=224, width_mult=1.):
super(MobileNetV2, self).__init__()
block = InvertedResidual
input_channel = 32
last_channel = 1280
interverted_residual_setting = [
# t, c, n, s
[1, 16, 1, 1], # 256, 256, 32 -> 256, 256, 16
[6, 24, 2, 2], # 256, 256, 16 -> 128, 128, 24 2
[6, 32, 3, 2], # 128, 128, 24 -> 64, 64, 32 4
[6, 64, 4, 2], # 64, 64, 32 -> 32, 32, 64 7
[6, 96, 3, 1], # 32, 32, 64 -> 32, 32, 96
[6, 160, 3, 2], # 32, 32, 96 -> 16, 16, 160 14
[6, 320, 1, 1], # 16, 16, 160 -> 16, 16, 320
]
assert input_size % 32 == 0
input_channel = int(input_channel * width_mult)
self.last_channel = int(last_channel * width_mult) if width_mult > 1.0 else last_channel
# 首先对输入图像进行一个下采样,512, 512, 3 -> 256, 256, 32
self.features = [conv_bn(3, input_channel, 2)]
# t代表expand_ratio维度扩大的倍数,c代表每一层输出的维度,n代表该层有多少个InvertedResidual结构,s代表stride
for t, c, n, s in interverted_residual_setting:
output_channel = int(c * width_mult)
for i in range(n):
if i == 0:
self.features.append(block(input_channel, output_channel, s, expand_ratio=t))
else:
self.features.append(block(input_channel, output_channel, 1, expand_ratio=t))
input_channel = output_channel
self.features.append(conv_1x1_bn(input_channel, self.last_channel))
self.features = nn.Sequential(*self.features)
self.classifier = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(self.last_channel, n_class),
)
self._initialize_weights()
关于前面论文中提到可以任意控制encoder提取特征的分辨率,通过下面代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
class MobileNetV2(nn.Module):
def __init__(self, downsample_factor=8, pretrained=True):
super(MobileNetV2, self).__init__()
from functools import partial
model = mobilenetv2(pretrained)
self.features = model.features[:-1]
self.total_idx = len(self.features)
# 用于定位到mobilenet对应的层中,方便如果后面选择不同的stride时,对不同的层进行不要stride,使用dilate
# 这个是根据interverted_residual_setting的n计算的,n代表的每一层中block的数量
#刚开始就进行了一次下采样,加上这下面四个一共有五个,本文中用的是4次
self.down_idx = [2, 4, 7, 14]
# 如果下采样系数为8,则要对down_idx中对应的后两个层进行系数上的修改
#通过_nostride_dilate函数,将卷积层的步长修改为1,并设置对应的膨胀系数和填充。
if downsample_factor == 8:
for i in range(self.down_idx[-2], self.down_idx[-1]):
self.features[i].apply(
partial(self._nostride_dilate, dilate=2)
)
for i in range(self.down_idx[-1], self.total_idx):
self.features[i].apply(
partial(self._nostride_dilate, dilate=4)
)
elif downsample_factor == 16:
for i in range(self.down_idx[-1], self.total_idx):
self.features[i].apply(
partial(self._nostride_dilate, dilate=2)
)
ASPP
Decoder
DeepLabv3通常输出步幅为16,然后进行双线性插值回复原图像大小,这种朴素解码器模块可能无法成功地恢复目标分割细节。
所以提出了一种简单有效的decoder模块,如下图所示,编码器是DeepLabV3的编码结构,经过ASPP之后的特征首先以四倍的倍数进行双线性插值(即上采样),然后与来自具有相同空间分辨率的网络骨干的相应低级特征进行拼接。
在底层特征上应用1*1的卷积来减少通道的数量,因为相应的底层特征通常包含大量的通道(例如,256或512),这可能超过丰富的编码器特征的重要性(在我们的模型中只有256个通道),并使训练变得更加困难。
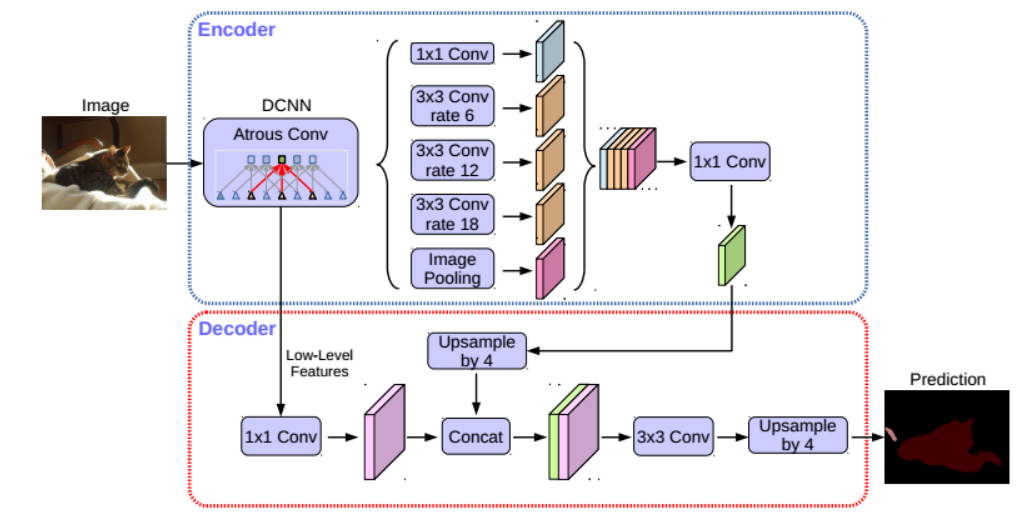
在连接之后,应用一些3 × 3卷积来改进特征,然后再进行一个简单的双线性上采样,上采样倍数为4。
最后作者提到当对编码器模块使用输出stride = 8时,性能略有提高,但代价是额外的计算复杂性。这是因为较大的输出步幅会导致特征图尺寸减小,因为每个输出像素对应于较大范围的输入像素。这样,相邻的像素之间信息的空间分辨率也降低了。换句话说,随着输出步幅的增加,特征图的分辨率相对较低,不能精确地表示输入图像的细节。较小的步幅意味着对输入图像进行更密集的特征提取,需要更多的计算资源和时间来处理图像
Experiment
关于Decoder部分,作者尝试过逐渐上采样然后进行拼接,类似于U-Net网络,得到的效果是没有明显改善的,所以用了上面的简单的decoder结构,最后作者建议将步幅改为4,效果会更好,但是计算量会大大提高