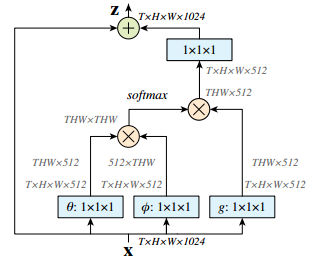
DANet
与之前通过多尺度特征融合捕获上下文的工作不同,作者提出了一种双重注意网络(DANet)来自适应地集成局部特征及其全局依赖性
motivation
- 现有的方法提高像素级辨别能力的,包括结合膨胀卷积,下采样等方式来进行多尺度融合,或者编码器-解码器等方式,这些方式虽然有助于捕获不同比例的对象,但却无法利用全局视图中对象之间的关系
- 为了有效地完成场景分割任务,需要区分一些令人困惑的相似类别,并考虑不同外观的对象
- 有必要提高特征表示对像素级识别的判别能力
contribution
- 提出了双倍注意力机制模块代替了以前的多尺度特征融合,以增强场景分割中特征表示的识别能力
- 提出了位置注意模块来学习特征的空间相互依赖性,设计了通道注意模块来建模通道相互依赖性。它通过在局部特征上建立丰富的上下文依赖关系来显著改善分割结果
architecture
因为卷积操作产生的是局部感受野,导致相同标签的像素对应特征可能不同,这种差异会进而导致类内的不一致性,影响识别的准确率。所以本文提出:在特征之间使用注意力机制建立关联以获取全局上下文信息
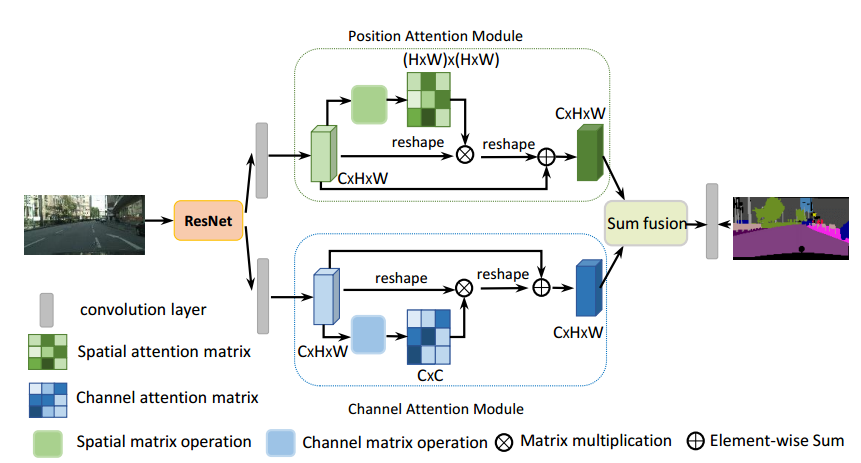
DANet模型的backbone是改进的RedNet网络,改进的点是在resnet的最后两个block使用了膨胀卷积代替了下采样得到的特征图,其大小是原始图像的1/8,然后得到的特征图会平行式的分别进入position attention模块和channel attention模块,分别得到图像的像素间的位置特征和通道间的特征,最后将两个特征融合到最后的特征表示中,得到最后的结果
position attention模块
位置注意模块将更广泛的上下文信息编码为局部特征,从而增强了它们的表示能力
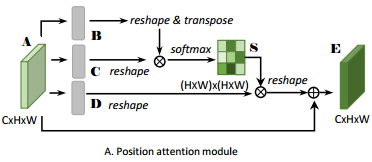
position模块的步骤如下:
- 将backbone得到的特征图首先经过一个卷积进行降维,然后将A进行卷积得到B C D,然后对BC进行reshape,得到维度为C * N,其中N大小为H * W,然后对B进行转置,然后矩阵B与矩阵C相乘,得到大小为N * N的矩阵,然后对该矩阵进行softmax处理,得到S矩阵,S矩阵代表了特征图中各个位置之间的关系
- 然后同样对矩阵D进行reshape,大小为C * N,然后与S矩阵相乘,得到每个像素与其他像素之前的权重关系,再乘以一个尺度参数α
- 然后对该矩阵进行reshape,回复原来的C * H * W的大小,再与矩阵A相加,得到最后的空间注意力map
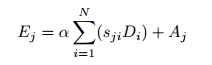
α初始化为0,逐渐学习赋予更多权重
由上面公式可以看出得到的每个位置的特征E是所有位置的特征与原始特征的加权和,因此,它具有全局上下文视图,并根据空间注意图选择性地聚合上下文。相似的语义特征实现了相互增益,从而提高了类内的紧凑性和语义一致性。
举例
假设特征图A为3**22(CHW),经过卷积之后得到的B,C,D reshape之后为34(C*N),N=HW
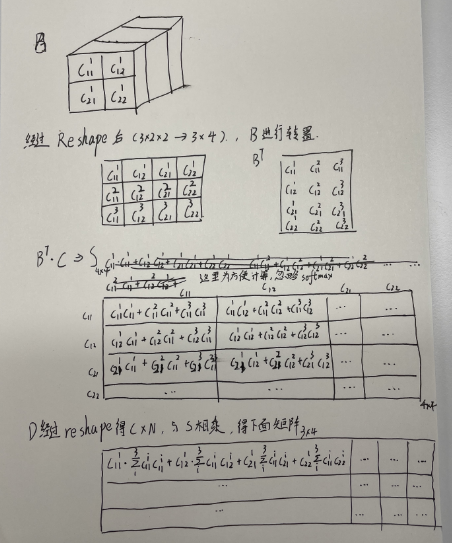
由上图得到的最后一个矩阵可以看出来,矩阵表示了第一个channel的第一个元素与其他元素之间的关系的乘积,即与其他像素的空间权重关系,可以理解为为了放大与其相似的像素的影像,消减与其不相似的像素的影像
channel attention模块
高级特征的每个通道映射可以被重新看作特定于类的响应,并且不同的语义响应彼此相关联。通过利用通道映射之间的相互依赖关系,我们可以强调相互依赖的特征映射,并改进特定语义的特征表示。因此,我们建立了一个通道注意力模块, 以显式的建模通道之间的相互依赖性
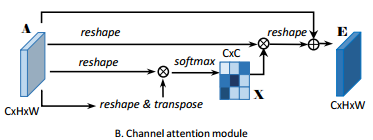
通道模块是挖掘每个通道之间的相似性关系,从而让每个通道都具有全局的语义信息特征,其大致过程和position attention模块一直,区别在于它是直接用backbone得到的特征图进行reshape,然后矩阵相乘的顺序不同,导致生成的channel map是C*****C的
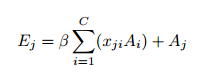
注意,在计算两个通道的关系之前,我们没有使用卷积层来嵌入特征,因为它可以保持不同通道映射之间的关系
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
class PAM_Module(Module):
""" Position attention module"""
#Ref from SAGAN
def __init__(self, in_dim):
super(PAM_Module, self).__init__()
self.chanel_in = in_dim
# 先经过3个卷积层生成3个新特征图B C D (尺寸不变)
self.query_conv = Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1)
self.key_conv = Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1)
self.value_conv = Conv2d(in_channels=in_dim, out_channels=in_dim, kernel_size=1)
self.gamma = Parameter(torch.zeros(1)) # α尺度系数初始化为0,并逐渐地学习分配到更大的权重
self.softmax = Softmax(dim=-1) # 对最后一个维度进行softmax
def forward(self, x):
"""
inputs :
x : input feature maps( B × C × H × W)
returns :
out : attention value + input feature
attention: B × (H×W) × (H×W)
"""
m_batchsize, C, height, width = x.size()
# 生成B矩阵,B -> (N,C,HW) -> (N,HW,C)
# query_conv(x)是对输入特征图x进行卷积,通道数从in_dim变为in_dim//8
# view是对该特征图进行形变,大小变为(m_batchsize, in_dim//8, width * height)
# permute是对特征图维度进行重排,将第1,2维度交换位置,相当于转置
proj_query = self.query_conv(x).view(m_batchsize, -1, width*height).permute(0, 2, 1)
# 生成C矩阵,C -> (N,C,HW)
proj_key = self.key_conv(x).view(m_batchsize, -1, width*height)
# BC矩阵相乘,空间注意图 -> (N,HW,HW)
# torch.bmm() 是 PyTorch 提供的用于执行批次矩阵相乘操作的函数。它接受两个输入张量,假设它们的形状分别为 (batch_size, n, m) 和 (batch_size, m, p),则返回的结果形状为 (batch_size, n, p)
energy = torch.bmm(proj_query, proj_key)
# S = softmax(BC) -> (N,HW,HW)
# 对矩阵的每一行进行softmax,即得到每一个像素与其他位置像素之间的亲密程度
attention = self.softmax(energy)
# 生成矩阵D D -> (N,C,HW)
proj_value = self.value_conv(x).view(m_batchsize, -1, width*height)
# DS -> (N,C,HW) 相乘将像素间的亲密程度与像素值相乘 再加到一起代表这个像素的空间信息
out = torch.bmm(proj_value, attention.permute(0, 2, 1)) # torch.bmm表示批次矩阵乘法
# output -> (N,C,H,W)
out = out.view(m_batchsize, C, height, width)
out = self.gamma*out + x
return out
# CAM_Module特征图刚开始不进行卷积,直接进行reshape然后矩阵相乘
class CAM_Module(Module):
""" Channel attention module"""
def __init__(self, in_dim):
super(CAM_Module, self).__init__()
self.chanel_in = in_dim
self.gamma = Parameter(torch.zeros(1)) # β尺度系数初始化为0,并逐渐地学习分配到更大的权重
self.softmax = Softmax(dim=-1) # 对每一行进行softmax
def forward(self,x):
"""
inputs :
x : input feature maps( B × C × H × W)
returns :
out : attention value + input feature
attention: B × C × C
"""
m_batchsize, C, height, width = x.size()
# A -> (N,C,HW)
proj_query = x.view(m_batchsize, C, -1)
# A -> (N,HW,C)
proj_key = x.view(m_batchsize, C, -1).permute(0, 2, 1)
# 矩阵乘积,通道注意图:X -> (N,C,C)
energy = torch.bmm(proj_query, proj_key)
# 首先提取每一行的最大值然后扩充成energy矩阵大小
# 通过 energy_new - energy 的操作,计算出了 energy 与 energy 中的最大值之间的差异。这个差异表示了相对于最大值的相对能量大小
energy_new = torch.max(energy, -1, keepdim=True)[0].expand_as(energy)-energy
# 最后通过softmax函数得到最终的注意力权重矩阵 attention,其中每个元素表示查询与键之间的关注程度或权重。
attention = self.softmax(energy_new)
# A -> (N,C,HW)
proj_value = x.view(m_batchsize, C, -1)
# XA -> (N,C,HW)
out = torch.bmm(attention, proj_value)
# output -> (N,C,H,W)
out = out.view(m_batchsize, C, height, width)
out = self.gamma*out + x
return out
Non-Local结构