vision-transformer
transformer最开始应用于nlp领域,但其注意力机制的优秀也可以利用在cv领域
architecture
vit可以分为以下三个模块
- Linear Projection of Flattened Patches
- Transformer Encoder
- MLP Head
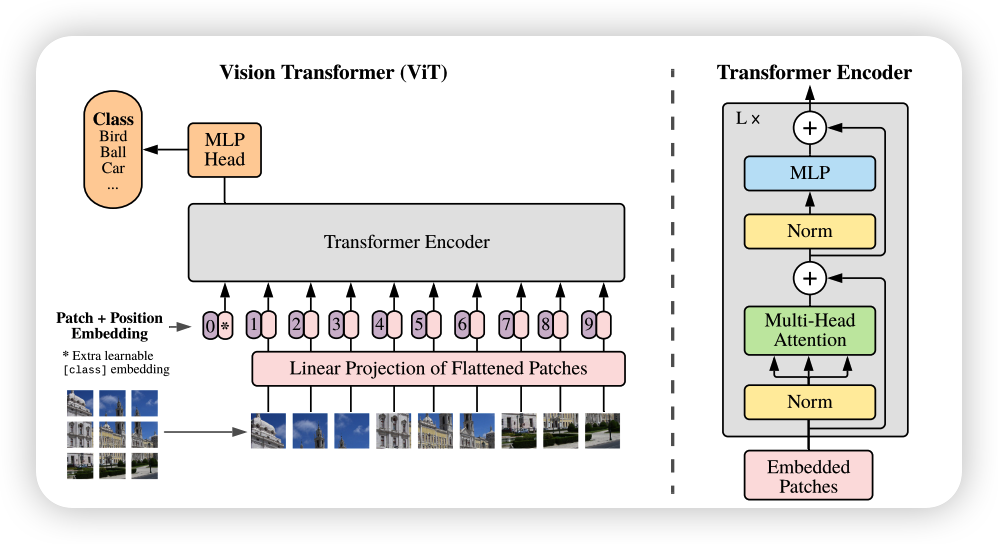
Linear Projection of Flattened Patches
由结构图可以看出输入图像首先进行分块,然后进行线性映射将每个patch映射到一维向量中,成为一个[patches,patch.size]的大小,然后插入一个专门用于分类的[class]token,这个[class]token是一个可训练的参数,数据格式和其他token一样都是一个向量,再加上Position Embedding
Transformer Encoder
Transformer Encoder其实就是重复堆叠Encoder Block L次,主要由以下几部分组成:
-
Norm
-
Multi-Head Attention
-
MLP
MLP就是全连接+GELU激活函数+Dropout

MLP Head
相当于是一个Linear层,转化成最后的类别