Mask2former
motivation
- 希望能提出一种universal的结构能够完成各种分割任务,包括语义分割和实体分割
contribution
- 在Transformer解码器中使用了掩蔽注意力,它将注意力限制在以预测片段为中心的局部特征上,这些片段可以是对象,也可以是区域,这取决于用于分组的特定语义。
- 使用多尺度高分辨率特征来帮助模型分割小对象/区域
- 提出了优化改进措施,如切换自我注意和交叉注意的顺序,使查询特征可学习,并去除了dropout
architecture
一个完整的maskformer结构由三部分组成,一个获取低分辨率图像特征的backbone,一个对backbone得到的低分辨率的特征进行上采样的pixel decoder,最后使用transformer decoder对图像进行解码,以处理对象查询。最后的二进制mask预测从具有对象查询的每个像素embeddings中解码得到
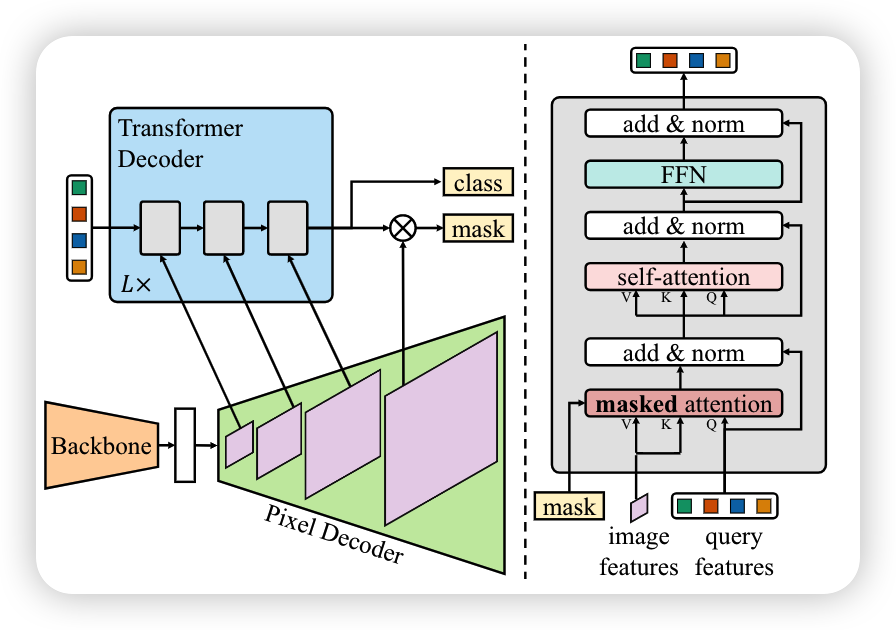
由上图可以看出作者对transformer-decoder进行了一些改变,首先使用了masked attention代替了cross-attention,其次为了更好的处理小目标,提出每次按顺序将多尺度特征中的一个尺度放入transformer-decoder中进行解码再传递给下一个decoder中,最后从图中可以看出切换了自注意力机制和交叉注意力机制的位置,使得查询特征是学习的,并且去掉了dropout来提高效率
Masked attention
上下文特征对于图像分割而言很重要,最近的研究表明transformer收敛慢的原因是交叉注意力层中的全局上下文,需要花很多时间才能获取局部目标区域,所以作者假设只用局部特征就能使得query features可以更新,并且可以通过自我注意力机制就可以收集上下文信息,所以提出masked attention,让每个query只在预测mask的区域中获取,每个像素只和自己同一个类别的,都是同一个qurey的像素,他们之间做attention
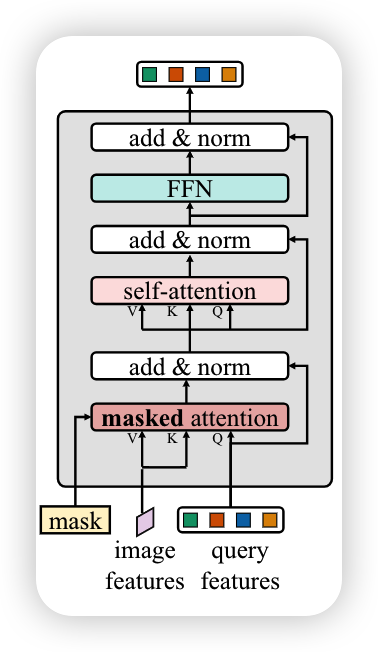
在第0次的时候没有mask,通过把qurey 送到 mlp里边,然后预测出mask出来,再做decoder
标准的cross-attention公式如下
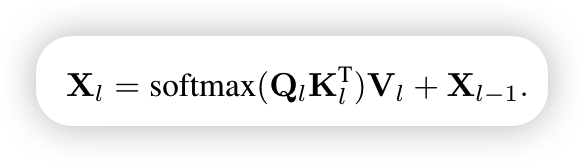
变形之后的cross-attention公式如下
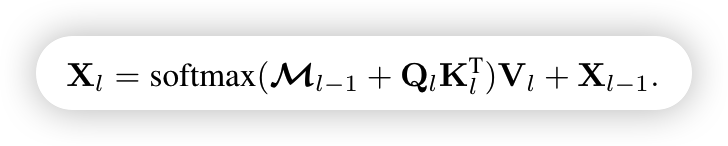
其中attention mask由下面公式获取
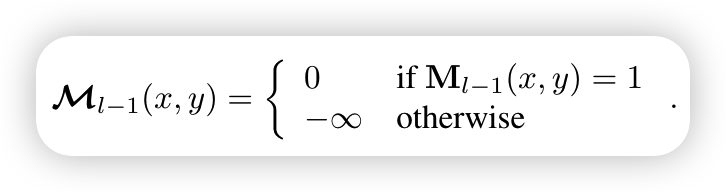
当Ml-1(x,y)为1时,表示是这个区域内的,是有联系的,则mask attention为0,这样照常进行cross attention,如果不是则为负无穷,这样softmax就为0
High-resolution features
高分辨率虽然可以提高对小目标的表现,但是也会增大计算量,所以作者提出使用多尺度的策略来减少计算量,使用由低分辨率和高分辨率特征组成的特征Pyramid,并按顺序将多尺度特征中的一个分辨率提供给Transformer解码器层,进行解码再传递给下一个decoder中
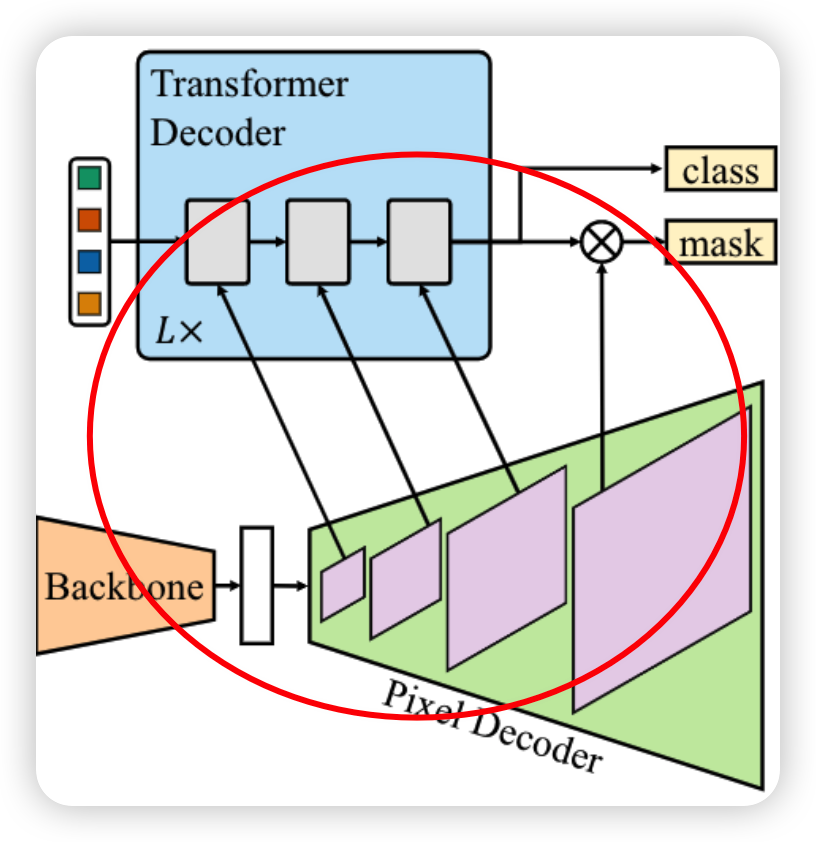
重复这个3层Transformer解码器L次。因此,最后transformer decoder有3 layers。更具体地,前三层接收分辨率为H1=H/32、H2=H/16、H3=H/8和W1=W/32、W2=W/16、W3=W/8的特征图,其中HandWare是原始图像分辨率
Optimization improvements
在decoder中完全去除了dropout以提高效率