DDRNet
motivation
- 现在语义分割模型很多通过消耗时间来提高性能,很多实时的网络
contribution
- 提出了一组用于实时语义分割的高效骨干网,提出的深度双分辨率网络由两个深度分支组成,在两个分支之间进行多次双边融合
- 设计了一种新的上下文信息提取器DAPPM模块,能够扩大感受野和融合多尺度低分辨率的上下文内容
- DDRNets在分割精度和推理速度之间取得了很好的平衡,并且在Cityscapes and CamVid dataset达到了最先进的权衡
architecture
在分类主干上添加一个额外的高分辨率分支,高分辨率分支不包含任何下采样操作,并且与低分辨率分支具有一对一的对应关系,以形成深度高分辨率表示。然后在不同阶段进行多次双侧特征融合,充分融合空间信息和语义信息。
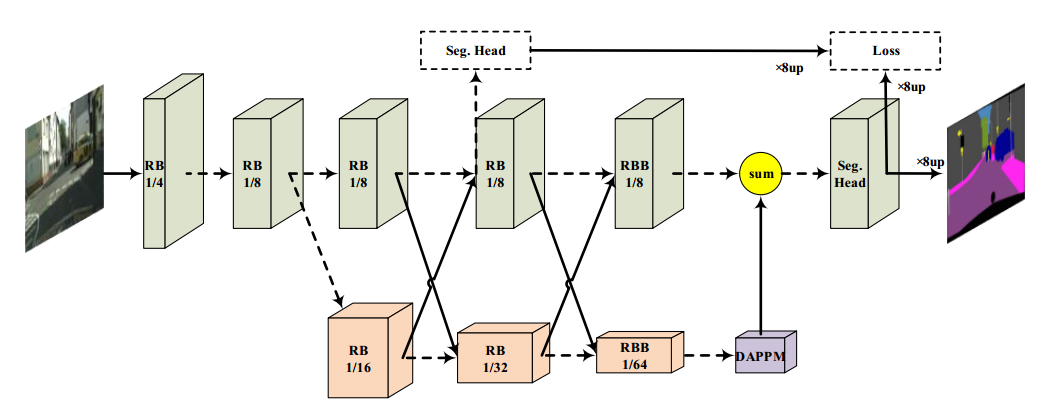
双侧特征融合包括将高分辨率分支融合到低分辨率分支(高到低)和将低分辨率分支融合到高分辨率分支(低到高)。对于高到低的融合,高分辨率特征图在点向求和之前通过3×3卷积序列进行下采样,其步幅为2,对于低到高的融合,低分辨率特征图首先通过1×1卷积进行压缩,然后使用双线性插值进行上采样
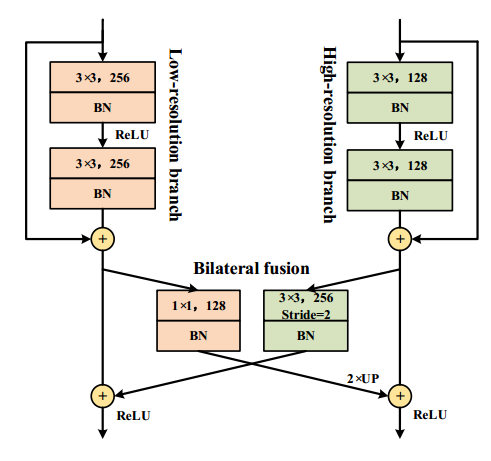
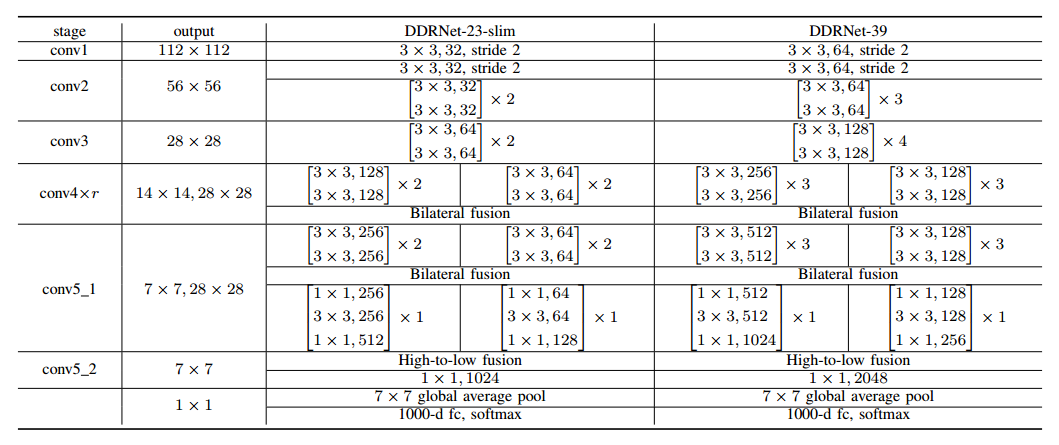
DDRNet结构细节如下表
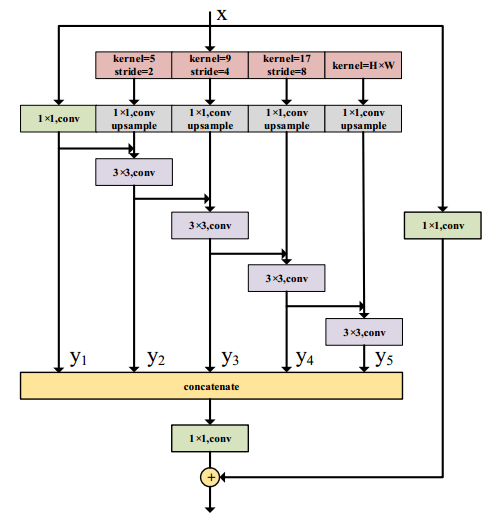
DAPPM
下图是DAPPM的结构,以1/64图像分辨率的特征图为输入,再进行下采样生成1/128,1/256,1/512的特征映射,然后对各个层进行上采样,然后利用3*3的conv进行不同尺度的上下文信息的融合,更大池化核提取的上下文与更深的信息流相融合,不同深度与不同大小池化核的融合形成了多尺度性质,并且由于输入分辨率就仅为原图像的1/64,所以推理速度很快
损失函数
参照PSPNet将α设置为0.4,Lf、Ln、La分别为最终损耗、正态损耗、辅助损耗
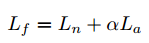
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
# Copyright (c) OpenMMLab. All rights reserved.
import torch.nn as nn
from mmcv.cnn import ConvModule, build_norm_layer
from mmengine.model import BaseModule
from mmseg.models.utils import DAPPM, BasicBlock, Bottleneck, resize
from mmseg.registry import MODELS
from mmseg.utils import OptConfigType
@MODELS.register_module()
class DDRNet(BaseModule):
"""DDRNet backbone.
This backbone is the implementation of `Deep Dual-resolution Networks for
Real-time and Accurate Semantic Segmentation of Road Scenes
<http://arxiv.org/abs/2101.06085>`_.
Modified from https://github.com/ydhongHIT/DDRNet.
Args:
in_channels (int): Number of input image channels. Default: 3.
channels: (int): The base channels of DDRNet. Default: 32.
ppm_channels (int): The channels of PPM module. Default: 128.
align_corners (bool): align_corners argument of F.interpolate.
Default: False.
norm_cfg (dict): Config dict to build norm layer.
Default: dict(type='BN', requires_grad=True).
act_cfg (dict): Config dict for activation layer.
Default: dict(type='ReLU', inplace=True).
init_cfg (dict, optional): Initialization config dict.
Default: None.
"""
def __init__(self,
in_channels: int = 3,
channels: int = 32,
ppm_channels: int = 128,
align_corners: bool = False,
norm_cfg: OptConfigType = dict(type='BN', requires_grad=True),
act_cfg: OptConfigType = dict(type='ReLU', inplace=True),
init_cfg: OptConfigType = None):
super().__init__(init_cfg)
self.in_channels = in_channels
self.ppm_channels = ppm_channels
self.norm_cfg = norm_cfg
self.act_cfg = act_cfg
self.align_corners = align_corners
# stage 0-2
self.stem = self._make_stem_layer(in_channels, channels, num_blocks=2)
self.relu = nn.ReLU()
# low resolution(context) branch
self.context_branch_layers = nn.ModuleList()
for i in range(3):
self.context_branch_layers.append(
self._make_layer(
block=BasicBlock if i < 2 else Bottleneck,
inplanes=channels * 2**(i + 1),
planes=channels * 8 if i > 0 else channels * 4,
num_blocks=2 if i < 2 else 1,
stride=2))
# bilateral fusion
self.compression_1 = ConvModule(
channels * 4,
channels * 2,
kernel_size=1,
norm_cfg=self.norm_cfg,
act_cfg=None)
self.down_1 = ConvModule(
channels * 2,
channels * 4,
kernel_size=3,
stride=2,
padding=1,
norm_cfg=self.norm_cfg,
act_cfg=None)
self.compression_2 = ConvModule(
channels * 8,
channels * 2,
kernel_size=1,
norm_cfg=self.norm_cfg,
act_cfg=None)
self.down_2 = nn.Sequential(
ConvModule(
channels * 2,
channels * 4,
kernel_size=3,
stride=2,
padding=1,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg),
ConvModule(
channels * 4,
channels * 8,
kernel_size=3,
stride=2,
padding=1,
norm_cfg=self.norm_cfg,
act_cfg=None))
# high resolution(spatial) branch
self.spatial_branch_layers = nn.ModuleList()
for i in range(3):
self.spatial_branch_layers.append(
self._make_layer(
block=BasicBlock if i < 2 else Bottleneck,
inplanes=channels * 2,
planes=channels * 2,
num_blocks=2 if i < 2 else 1,
))
self.spp = DAPPM(
channels * 16, ppm_channels, channels * 4, num_scales=5)
def _make_stem_layer(self, in_channels, channels, num_blocks):
layers = [
ConvModule(
in_channels,
channels,
kernel_size=3,
stride=2,
padding=1,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg),
ConvModule(
channels,
channels,
kernel_size=3,
stride=2,
padding=1,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg)
]
layers.extend([
self._make_layer(BasicBlock, channels, channels, num_blocks),
nn.ReLU(),
self._make_layer(
BasicBlock, channels, channels * 2, num_blocks, stride=2),
nn.ReLU(),
])
return nn.Sequential(*layers)
def _make_layer(self, block, inplanes, planes, num_blocks, stride=1):
downsample = None
if stride != 1 or inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(
inplanes,
planes * block.expansion,
kernel_size=1,
stride=stride,
bias=False),
build_norm_layer(self.norm_cfg, planes * block.expansion)[1])
layers = [
block(
in_channels=inplanes,
channels=planes,
stride=stride,
downsample=downsample)
]
inplanes = planes * block.expansion
for i in range(1, num_blocks):
layers.append(
block(
in_channels=inplanes,
channels=planes,
stride=1,
norm_cfg=self.norm_cfg,
act_cfg_out=None if i == num_blocks - 1 else self.act_cfg))
return nn.Sequential(*layers)
def forward(self, x):
"""Forward function."""
#input size [6,3,1024,1024]
out_size = (x.shape[-2] // 8, x.shape[-1] // 8)
# stage 0-2
# stem(x)的维度[6, 64, 128, 128]
x = self.stem(x)
# stage3
# x_c的维度[6, 128, 64, 64],x_s的维度[6, 64, 128, 128]
x_c = self.context_branch_layers[0](x)
x_s = self.spatial_branch_layers[0](x)
comp_c = self.compression_1(self.relu(x_c))
x_c += self.down_1(self.relu(x_s))
x_s += resize(
comp_c,
size=out_size,
mode='bilinear',
align_corners=self.align_corners)
if self.training:
temp_context = x_s.clone()
# stage4
# x_c的维度[6, 128, 64, 64],x_s的维度[6, 64, 128, 128]
x_c = self.context_branch_layers[1](self.relu(x_c))
x_s = self.spatial_branch_layers[1](self.relu(x_s))
comp_c = self.compression_2(self.relu(x_c))
x_c += self.down_2(self.relu(x_s))
x_s += resize(
comp_c,
size=out_size,
mode='bilinear',
align_corners=self.align_corners)
# stage5
# x_c的维度[6, 256, 32, 32],x_s的维度[6, 64, 128, 128]
x_s = self.spatial_branch_layers[2](self.relu(x_s))
x_c = self.context_branch_layers[2](self.relu(x_c))
x_c = self.spp(x_c)
x_c = resize(
x_c,
size=out_size,
mode='bilinear',
align_corners=self.align_corners)
# x_c的维度[6, 128, 128, 128],x_s的维度[6, 128, 128, 128],temp_context的维度[6, 64, 128, 128]
return (temp_context, x_s + x_c) if self.training else x_s + x_c