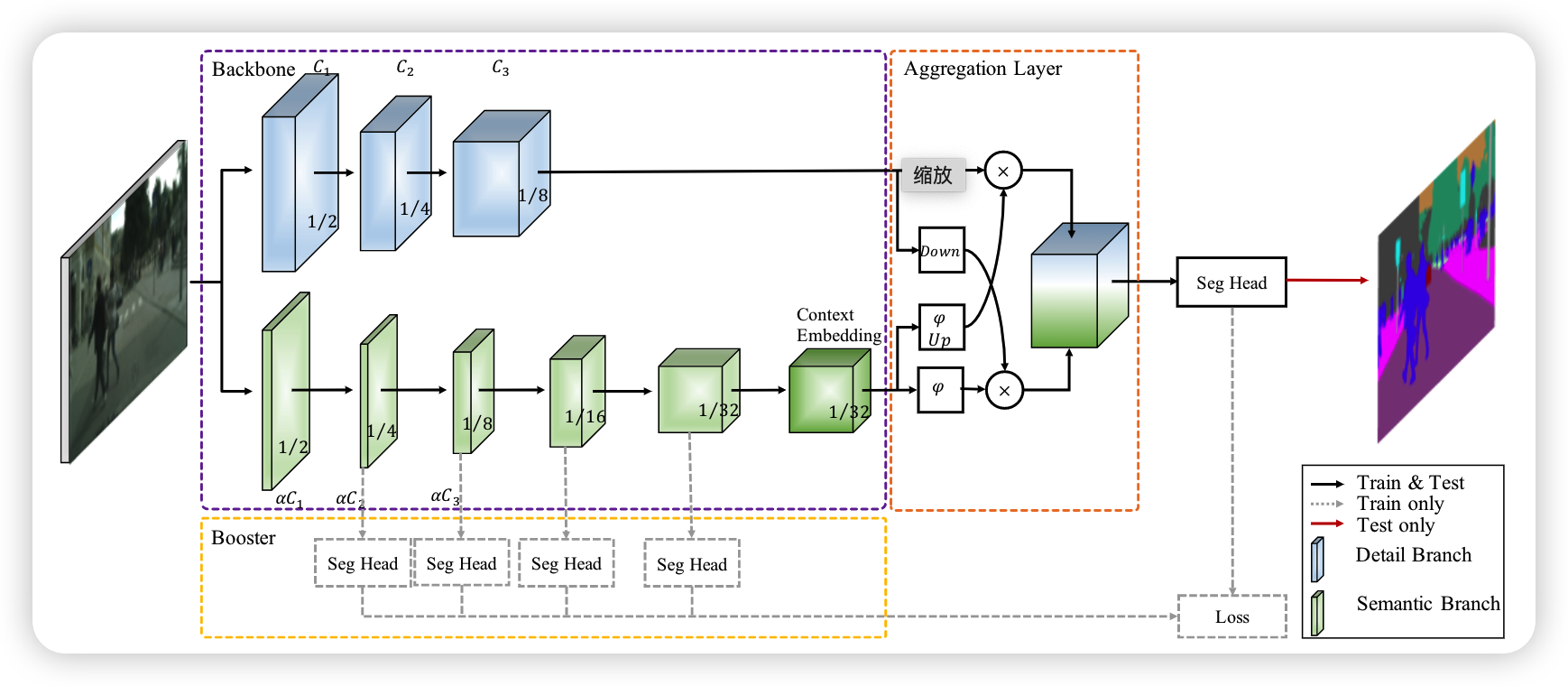
BiseNetV2
低级细节和高级语义对于语义分割任务都是必不可少的
motivation
- 很多语义分割模型实现高精度依赖于他们的backbone,有两种包括使用膨胀卷积的backbone和使用连续下采样的结构,这样的结构因为计算量的问题会增加很多时间
contribution
- 提出了一种高效有效的双向结构,称为双边分割网络,用于实时语义分割,它分别处理空间细节和类别语义
- 对于语义分支,设计了一种新的基于深度卷积的轻量级网络,以增强感受野并捕获丰富的上下文信息
- 引入了一种增强训练策略
architecture
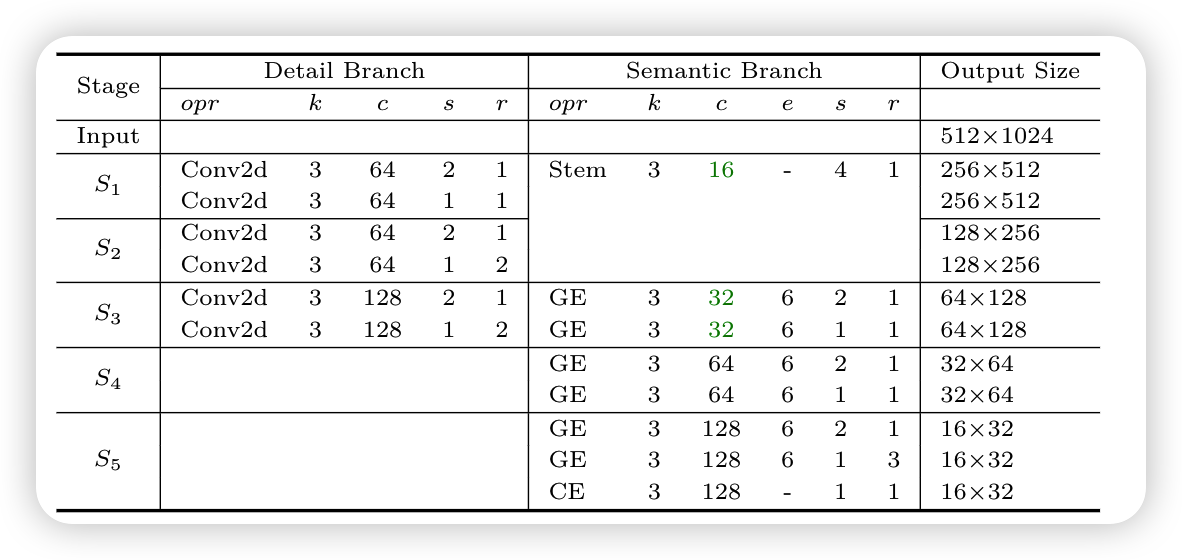
Detail Branch
负责低层次信息,使用丰富的通道信息来丰富空间信息,关键是宽的通道数和浅层次网络,该分支提取的输出特征图是原始输入的1/8。由于通道容量高,该细节分支编码了丰富的空间细节
Semantic Branch
下采样策略可以提高特征表征的水平,快速扩大接受场。高级语义需要更大的接受域
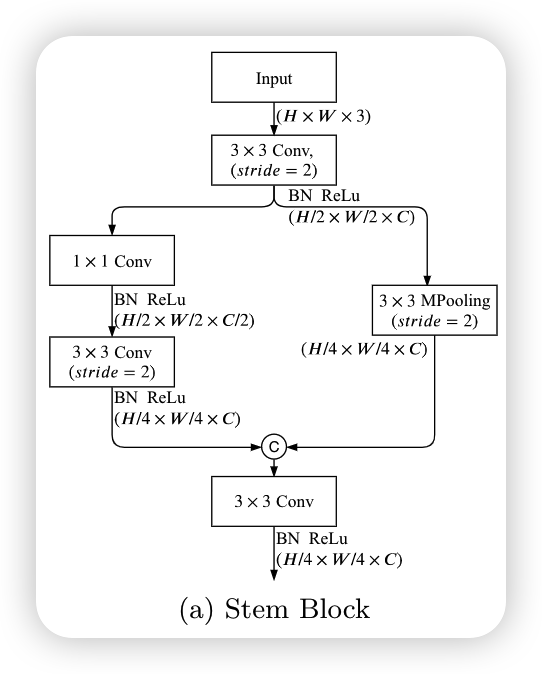
Stem Block
使用stem模块作为语义分支的第一阶段,使用两种不同的方式来收缩特征,将两个分支进行拼接,得到最后的输出
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
class StemBlock(nn.Module):
def __init__(self):
super(StemBlock, self).__init__()
self.conv = ConvBNReLU(3, 16, 3, stride=2)
self.left = nn.Sequential(
ConvBNReLU(16, 8, 1, stride=1, padding=0),
ConvBNReLU(8, 16, 3, stride=2),
)
self.right = nn.MaxPool2d(
kernel_size=3, stride=2, padding=1, ceil_mode=False)
self.fuse = ConvBNReLU(32, 16, 3, stride=1)
def forward(self, x):
feat = self.conv(x)
feat_left = self.left(feat)
feat_right = self.right(feat)
feat = torch.cat([feat_left, feat_right], dim=1)
feat = self.fuse(feat)
return feat
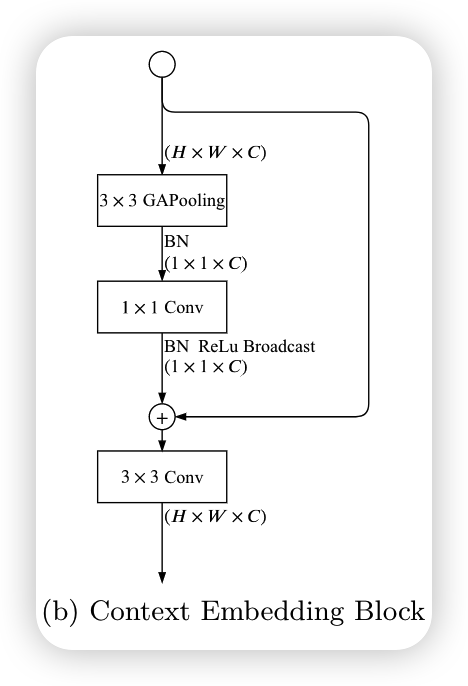
Context Embedding Block
因为semantic分支需要更大的感受野,所以设计了context embedding block来增大感受野,该模块使用了全局平均下采样和残差连接来有效的嵌入全局文本信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
class CEBlock(nn.Module):
def __init__(self):
super(CEBlock, self).__init__()
self.bn = nn.BatchNorm2d(128)
self.conv_gap = ConvBNReLU(128, 128, 1, stride=1, padding=0)
#TODO: in paper here is naive conv2d, no bn-relu
self.conv_last = ConvBNReLU(128, 128, 3, stride=1)
def forward(self, x):
feat = torch.mean(x, dim=(2, 3), keepdim=True)
feat = self.bn(feat)
feat = self.conv_gap(feat)
feat = feat + x
feat = self.conv_last(feat)
return feat
Gather-and-Expansion Layer
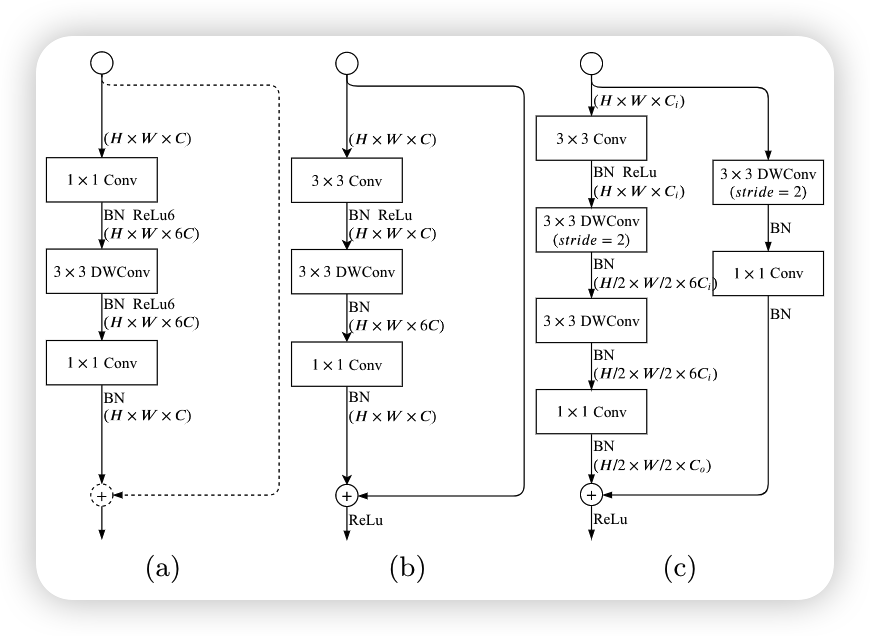
下图a是MobileNetV2的逆瓶颈结构,b和c是Gather and expansion layer, b和c的区别在于输出特征图大小不同,当需要降低输入特征图的分辨率时,使用c结构,如果分辨率不变,使用b结构
b的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
class GELayerS1(nn.Module):
def __init__(self, in_chan, out_chan, exp_ratio=6):
super(GELayerS1, self).__init__()
mid_chan = in_chan * exp_ratio
self.conv1 = ConvBNReLU(in_chan, in_chan, 3, stride=1)
self.dwconv = nn.Sequential(
nn.Conv2d(
in_chan, mid_chan, kernel_size=3, stride=1,
padding=1, groups=in_chan, bias=False),
nn.BatchNorm2d(mid_chan),
nn.ReLU(inplace=True), # not shown in paper
)
self.conv2 = nn.Sequential(
nn.Conv2d(
mid_chan, out_chan, kernel_size=1, stride=1,
padding=0, bias=False),
nn.BatchNorm2d(out_chan),
)
self.conv2[1].last_bn = True
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
feat = self.conv1(x)
feat = self.dwconv(feat)
feat = self.conv2(feat)
feat = feat + x
feat = self.relu(feat)
return feat
c的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
class GELayerS2(nn.Module):
def __init__(self, in_chan, out_chan, exp_ratio=6):
super(GELayerS2, self).__init__()
mid_chan = in_chan * exp_ratio
self.conv1 = ConvBNReLU(in_chan, in_chan, 3, stride=1)
self.dwconv1 = nn.Sequential(
nn.Conv2d(
in_chan, mid_chan, kernel_size=3, stride=2,
padding=1, groups=in_chan, bias=False),
nn.BatchNorm2d(mid_chan),
)
self.dwconv2 = nn.Sequential(
nn.Conv2d(
mid_chan, mid_chan, kernel_size=3, stride=1,
padding=1, groups=mid_chan, bias=False),
nn.BatchNorm2d(mid_chan),
nn.ReLU(inplace=True), # not shown in paper
)
self.conv2 = nn.Sequential(
nn.Conv2d(
mid_chan, out_chan, kernel_size=1, stride=1,
padding=0, bias=False),
nn.BatchNorm2d(out_chan),
)
self.conv2[1].last_bn = True
self.shortcut = nn.Sequential(
nn.Conv2d(
in_chan, in_chan, kernel_size=3, stride=2,
padding=1, groups=in_chan, bias=False),
nn.BatchNorm2d(in_chan),
nn.Conv2d(
in_chan, out_chan, kernel_size=1, stride=1,
padding=0, bias=False),
nn.BatchNorm2d(out_chan),
)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
feat = self.conv1(x)
feat = self.dwconv1(feat)
feat = self.dwconv2(feat)
feat = self.conv2(feat)
shortcut = self.shortcut(x)
feat = feat + shortcut
feat = self.relu(feat)
return feat
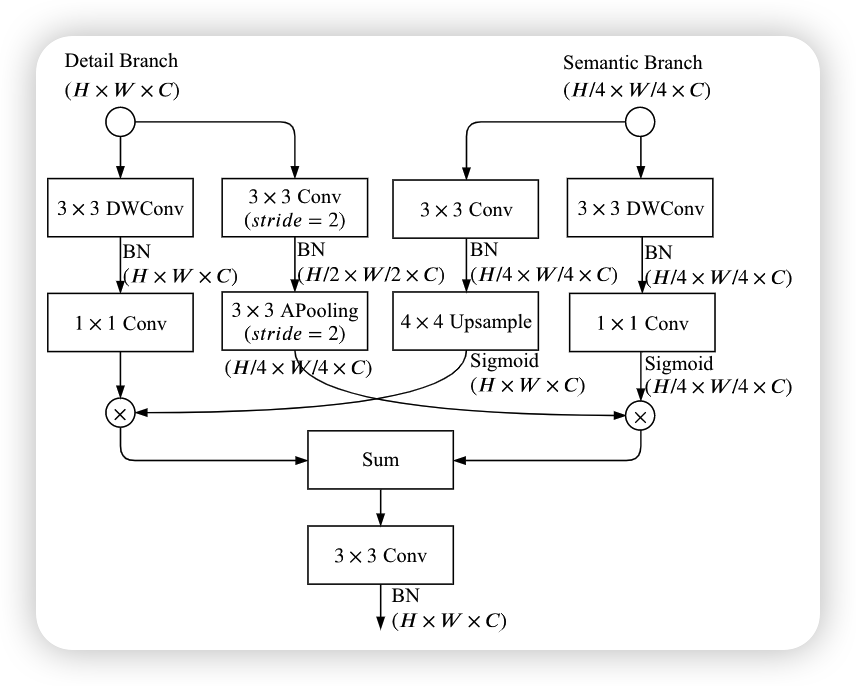
Bilateral Guided Aggregation
对两个分支进行融合
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
class BGALayer(nn.Module):
def __init__(self):
super(BGALayer, self).__init__()
self.left1 = nn.Sequential(
nn.Conv2d(
128, 128, kernel_size=3, stride=1,
padding=1, groups=128, bias=False),
nn.BatchNorm2d(128),
nn.Conv2d(
128, 128, kernel_size=1, stride=1,
padding=0, bias=False),
)
self.left2 = nn.Sequential(
nn.Conv2d(
128, 128, kernel_size=3, stride=2,
padding=1, bias=False),
nn.BatchNorm2d(128),
nn.AvgPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=False)
)
self.right1 = nn.Sequential(
nn.Conv2d(
128, 128, kernel_size=3, stride=1,
padding=1, bias=False),
nn.BatchNorm2d(128),
)
self.right2 = nn.Sequential(
nn.Conv2d(
128, 128, kernel_size=3, stride=1,
padding=1, groups=128, bias=False),
nn.BatchNorm2d(128),
nn.Conv2d(
128, 128, kernel_size=1, stride=1,
padding=0, bias=False),
)
self.up1 = nn.Upsample(scale_factor=4)
self.up2 = nn.Upsample(scale_factor=4)
##TODO: does this really has no relu?
self.conv = nn.Sequential(
nn.Conv2d(
128, 128, kernel_size=3, stride=1,
padding=1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True), # not shown in paper
)
def forward(self, x_d, x_s):
dsize = x_d.size()[2:]
left1 = self.left1(x_d)
left2 = self.left2(x_d)
right1 = self.right1(x_s)
right2 = self.right2(x_s)
right1 = self.up1(right1)
left = left1 * torch.sigmoid(right1)
right = left2 * torch.sigmoid(right2)
right = self.up2(right)
out = self.conv(left + right)
return out
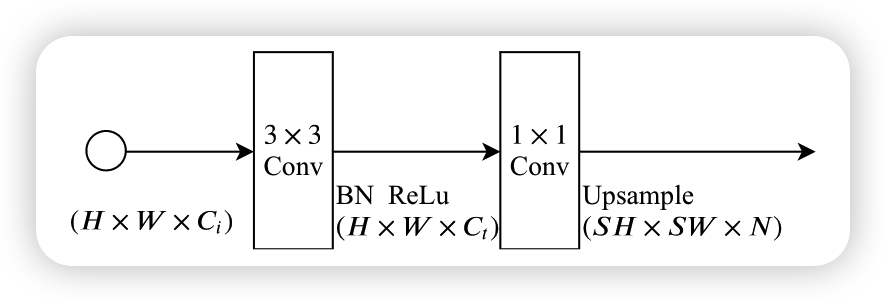
Booster Training Strategy
在训练阶段增强特征表示,并可以在推理阶段进行处理。因此,它增加了推理阶段的计算复杂度,可以将这个模块插在semantic模块的各个位置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
class SegmentHead(nn.Module):
def __init__(self, in_chan, mid_chan, n_classes, up_factor=8, aux=True):
super(SegmentHead, self).__init__()
self.conv = ConvBNReLU(in_chan, mid_chan, 3, stride=1)
self.drop = nn.Dropout(0.1)
self.up_factor = up_factor
out_chan = n_classes
mid_chan2 = up_factor * up_factor if aux else mid_chan
up_factor = up_factor // 2 if aux else up_factor
self.conv_out = nn.Sequential(
nn.Sequential(
nn.Upsample(scale_factor=2),
ConvBNReLU(mid_chan, mid_chan2, 3, stride=1)
) if aux else nn.Identity(),
nn.Conv2d(mid_chan2, out_chan, 1, 1, 0, bias=True),
nn.Upsample(scale_factor=up_factor, mode='bilinear', align_corners=False)
)
def forward(self, x):
feat = self.conv(x)
feat = self.drop(feat)
feat = self.conv_out(feat)
return feat