基础语法
变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
package main
import (
"fmt"
"math"
)
func main() {
var a = "initial"
var b, c int = 1, 2
var d = true
var e float64
f := float32(e)
g := a + "foo"
fmt.Println(a, b, c, d, e, f) // initial 1 2 true 0 0
fmt.Println(g) // initialfoo
const s string = "constant"
const h = 500000000
const i = 3e20 / h
fmt.Println(s, h, i, math.Sin(h), math.Sin(i))
}
if else
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
package main
import "fmt"
func main() {
if 7%2 == 0 {
fmt.Println("7 is even")
} else {
fmt.Println("7 is odd")
}
if 8%4 == 0 {
fmt.Println("8 is divisible by 4")
}
if num := 9; num < 0 {
fmt.Println(num, "is negative")
} else if num < 10 {
fmt.Println(num, "has 1 digit")
} else {
fmt.Println(num, "has multiple digits")
}
}
循环
go中没有while、do-while循环,只有for循环
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
package main
import "fmt"
func main() {
i := 1
//死循环
for {
fmt.Println("loop")
break
}
//这里面三段任何一段都可以省略
for j := 7; j < 9; j++ {
fmt.Println(j)
}
for n := 0; n < 5; n++ {
if n%2 == 0 {
continue
}
fmt.Println(n)
}
for i <= 3 {
fmt.Println(i)
i = i + 1
}
}
switch
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
package main
import (
"fmt"
"time"
)
func main() {
a := 2
//go中不需要break,可以用任何类型
switch a {
case 1:
fmt.Println("one")
case 2:
fmt.Println("two")
case 3:
fmt.Println("three")
case 4, 5:
fmt.Println("four or five")
default:
fmt.Println("other")
}
t := time.Now()
//甚至不需要变量
switch {
case t.Hour() < 12:
fmt.Println("It's before noon")
default:
fmt.Println("It's after noon")
}
}
数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
package main
import "fmt"
func main() {
var a [5]int
a[4] = 100
fmt.Println(a[4], len(a))
b := [5]int{1, 2, 3, 4, 5}
//也可以不设置大小值
//b := []int{1, 2, 3, 4, 5}
fmt.Println(b)
var twoD [2][3]int
for i := 0; i < 2; i++ {
for j := 0; j < 3; j++ {
twoD[i][j] = i + j
}
}
fmt.Println("2d: ", twoD)
}
切片
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
package main
import "fmt"
func main() {
s := make([]string, 3)
s[0] = "a"
s[1] = "b"
s[2] = "c"
fmt.Println("get:", s[2]) // c
fmt.Println("len:", len(s)) // 3
s = append(s, "d")
s = append(s, "e", "f")
fmt.Println(s) // [a b c d e f]
c := make([]string, len(s))
copy(c, s)
fmt.Println(c) // [a b c d e f]
fmt.Println(s[2:5]) // [c d e]
fmt.Println(s[:5]) // [a b c d e]
fmt.Println(s[2:]) // [c d e f]
good := []string{"g", "o", "o", "d"}
fmt.Println(good) // [g o o d]
}
map
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
package main
import "fmt"
func main() {
m := make(map[string]int)
m["one"] = 1
m["two"] = 2
fmt.Println(m) // map[one:1 two:2]
fmt.Println(len(m)) // 2
fmt.Println(m["one"]) // 1
fmt.Println(m["unknow"]) // 0
r, ok := m["unknow"]
fmt.Println(r, ok) // 0 false
delete(m, "one")
m2 := map[string]int{"one": 1, "two": 2}
var m3 = map[string]int{"one": 1, "two": 2}
fmt.Println(m2, m3)
}
range
用于快速,简洁遍历数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
package main
import "fmt"
func main() {
nums := []int{2, 3, 4}
sum := 0
for i, num := range nums {
sum += num
if num == 2 {
fmt.Println("index:", i, "num:", num) // index: 0 num: 2
}
}
fmt.Println(sum) // 9
m := map[string]string{"a": "A", "b": "B"}
for k, v := range m {
fmt.Println(k, v) // b B; a A
}
for k := range m {
fmt.Println("key", k) // key a; key b
}
}
函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
package main
import "fmt"
func add(a int, b int) int {
return a + b
}
func add2(a, b int) int {
return a + b
}
func exists(m map[string]string, k string) (v string, ok bool) {
v, ok = m[k]
return v, ok
}
func main() {
res := add(1, 2)
fmt.Println(res) // 3
v, ok := exists(map[string]string{"a": "A"}, "a")
fmt.Println(v, ok) // A true
}
指针
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
package main
import "fmt"
func add2(n int) {
n += 2
}
func add2ptr(n *int) {
*n += 2
}
func main() {
n := 5
add2(n)
fmt.Println(n) // 5
add2ptr(&n)
fmt.Println(n) // 7
}
结构体
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
package main
import "fmt"
type user struct {
name string
password string
}
func main() {
//结构体的几种声明变量的方式
a := user{name: "wang", password: "1024"}
b := user{"wang", "1024"}
c := user{name: "wang"}
c.password = "1024"
var d user
d.name = "wang"
d.password = "1024"
fmt.Println(a, b, c, d) // {wang 1024} {wang 1024} {wang 1024} {wang 1024}
fmt.Println(checkPassword(a, "haha")) // false
fmt.Println(checkPassword2(&a, "haha")) // false
}
//结构体传递可以有指针和非指针两种方式
//这和java不一样,java这种传的都是引用,但go这里如果不传指针形式的话,是不会改变原始值的
func checkPassword(u user, password string) bool {
return u.password == password
}
func checkPassword2(u *user, password string) bool {
return u.password == password
}
结构体方法
在函数名前面的 (u user) 或 (u *user) 称为接收者。接收者指定了这个方法属于哪个类型(例如 user 结构体),因此该方法成为了这个类型的方法。
类似于java的类成员函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
package main
import "fmt"
type user struct {
name string
password string
}
//适合用于不改变结构体内容的场景,如只读操作
func (u user) checkPassword(password string) bool {
return u.password == password
}
//适合用于需要修改结构体内容的场景,如更新密码
func (u *user) resetPassword(password string) {
u.password = password
}
func main() {
a := user{name: "wang", password: "1024"}
a.resetPassword("2048")
fmt.Println(a.checkPassword("2048")) // true
}
错误处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
package main
import (
"errors"
"fmt"
)
type user struct {
name string
password string
}
func findUser(users []user, name string) (v *user, err error) {
for _, u := range users {
if u.name == name {
return &u, nil
}
}
return nil, errors.New("not found")
}
func main() {
//定义函数返回值有err
u, err := findUser([]userwang, "wang")
//所以首先判断err
if err != nil {
fmt.Println(err)
return
}
fmt.Println(u.name) // wang
if u, err := findUser([]userwang, "li"); err != nil {
fmt.Println(err) // not found
return
} else {
fmt.Println(u.name)
}
}
字符串
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
package main
import (
"fmt"
"strings"
)
func main() {
a := "hello"
fmt.Println(strings.Contains(a, "ll")) // true
fmt.Println(strings.Count(a, "l")) // 2
fmt.Println(strings.HasPrefix(a, "he")) // true
fmt.Println(strings.HasSuffix(a, "llo")) // true
fmt.Println(strings.Index(a, "ll")) // 2
fmt.Println(strings.Join([]string{"he", "llo"}, "-")) // he-llo
fmt.Println(strings.Repeat(a, 2)) // hellohello
fmt.Println(strings.Replace(a, "e", "E", -1)) // hEllo
fmt.Println(strings.Split("a-b-c", "-")) // [a b c]
fmt.Println(strings.ToLower(a)) // hello
fmt.Println(strings.ToUpper(a)) // HELLO
fmt.Println(len(a)) // 5
b := "你好"
fmt.Println(len(b)) // 6
}
字符串格式化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
package main
import "fmt"
type point struct {
x, y int
}
func main() {
s := "hello"
n := 123
p := point{1, 2}
fmt.Println(s, n) // hello 123
fmt.Println(p) // {1 2}
//有各种占位符,用%v可以代替各种类型的符
fmt.Printf("s=%v\n", s) // s=hello
fmt.Printf("n=%v\n", n) // n=123
fmt.Printf("p=%v\n", p) // p={1 2}
fmt.Printf("p=%+v\n", p) // p={x:1 y:2}
fmt.Printf("p=%#v\n", p) // p=main.point{x:1, y:2}
f := 3.141592653
fmt.Println(f) // 3.141592653
fmt.Printf("%.2f\n", f) // 3.14
}
JSON处理
结构体中每个字段首字母要大写,就可以用json.Marshal进行序列化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
package main
import (
"encoding/json"
"fmt"
)
type userInfo struct {
Name string
Age int `json:"age"`
Hobby []string
}
func main() {
a := userInfo{Name: "wang", Age: 18, Hobby: []string{"Golang", "TypeScript"}}
//将结构体进行序列化
buf, err := json.Marshal(a)
if err != nil {
panic(err)
}
fmt.Println(buf) // [123 34 97 103 ...]
fmt.Println(string(buf)) // {"Name":"wang","age":18,"Hobby":["Golang","TypeScript"]}
buf, err = json.MarshalIndent(a, "", "\t")
if err != nil {
panic(err)
}
fmt.Println(string(buf)) // 格式化后的 JSON 输出
var b userInfo
//buff反序列化到b中
err = json.Unmarshal(buf, &b)
if err != nil {
panic(err)
}
fmt.Printf("%#v\n", b) // main.userInfo{Name:"wang", Age:18, Hobby:[]string{"Golang", "TypeScript"}}
}
时间处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
package main
import (
"fmt"
"time"
)
func main() {
now := time.Now()
fmt.Println(now) // 当前时间,示例:2022-03-27 18:04:59.433297 +0800 CST m=+0.000087933
t := time.Date(2022, 3, 27, 1, 25, 36, 0, time.UTC)
t2 := time.Date(2022, 3, 27, 2, 30, 36, 0, time.UTC)
fmt.Println(t) // 2022-03-27 01:25:36 +0000 UTC
fmt.Println(t.Year(), t.Month(), t.Day(), t.Hour(), t.Minute()) // 输出各时间字段,例如:2022 March 27 1 25
fmt.Println(t.Format("2006-01-02 15:04:05")) // 格式化时间输出:2022-03-27 01:25:36
//得到时间段
diff := t2.Sub(t)
fmt.Println(diff) // 时间差,示例:1h5m0s
fmt.Println(diff.Minutes(), diff.Seconds()) // 时间差的分钟数和秒数,例如:65 3900
t3, err := time.Parse("2006-01-02 15:04:05", "2022-03-27 01:25:36")
if err != nil {
panic(err)
}
fmt.Println(t3 == t) // true,判断解析的时间是否等于原始时间
//获取时间戳
fmt.Println(now.Unix()) // 输出当前时间的 Unix 时间戳,例如:1648378800
}
字符串数字间转化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
package main
import (
"fmt"
"strconv"
)
func main() {
//strconv.ParseFloat:将字符串解析为浮点数。参数 64 表示转换为 float64 类型
f, _ := strconv.ParseFloat("1.234", 64)
fmt.Println(f) // 1.234
//strconv.ParseInt:将字符串解析为指定进制的整数。参数 10 表示十进制,0 表示自动识别进制(如 "0x" 前缀会识别为十六进制)。参数 64 指定目标类型为 int64
n, _ := strconv.ParseInt("111", 10, 64)
fmt.Println(n) // 111
n, _ = strconv.ParseInt("0x1000", 0, 64)
fmt.Println(n) // 4096
//专门用于将十进制字符串转换为整数,返回 int 类型
n2, _ := strconv.Atoi("123")
fmt.Println(n2) // 123
//解析失败
n2, err := strconv.Atoi("AAA")
fmt.Println(n2, err) // 0 strconv.Atoi: parsing "AAA": invalid syntax
}
进程信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
package main
import (
"fmt"
"os"
"os/exec"
)
func main() {
// go run example/20-env/main.go a b c d
//os.Args是切片,所以可以用args := os.Args[1:]获取输入参数
fmt.Println(os.Args) // 输出程序参数,例如:[path/to/exe a b c d]
fmt.Println(os.Getenv("PATH")) // 获取环境变量 PATH,例如:/usr/local/go/bin...
fmt.Println(os.Setenv("AA", "BB")) // 设置环境变量 AA=BB
buf, err := exec.Command("grep", "127.0.0.1", "/etc/hosts").CombinedOutput()
if err != nil {
panic(err)
}
fmt.Println(string(buf)) // 输出 grep 结果,例如:127.0.0.1 localhost
}
go实战案例
猜谜游戏
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
package main
import(
"fmt"
"math/rand"
"bufio"
"strings"
"os"
"strconv"
)
func main(){
maxNum:=100
secretNum:=rand.Intn(maxNum)
fmt.Println("input your guess")
reader:=bufio.NewReader(os.Stdin)
for{
input,err:=reader.ReadString('\n')
if err != nil{
fmt.Println("An error occured while inputing",err)
continue
}
input=strings.TrimSuffix(input,"\n")
guess,err:=strconv.Atoi(input)
if err!=nil{
fmt.Println("Invalid input")
continue
}
fmt.Println("your guess is",guess)
if guess > secretNum{
fmt.Println("bigger")
}else if guess<secretNum{
fmt.Println("smaller")
}else{
fmt.Println("bingo")
break
}
}
}
命令行词典
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
package main
import (
"fmt"
"io/ioutil"
"log"
"net/http"
"strings"
)
func main() {
client := &http.Client{}
//创建一个包含 JSON 格式数据的 io.Reader 类型的数据流,用于 HTTP 请求的请求体中
var data = strings.NewReader(`{"trans_type":"en2zh","source":"good"}`)
//创建请求
req, err := http.NewRequest("POST", "https://api.interpreter.caiyunapp.com/v1/dict", data)
if err != nil {
log.Fatal(err)
}
//设置请求头
req.Header.Set("Connection", "keep-alive")
req.Header.Set("DNT", "1")
req.Header.Set("sec-ch-ua-mobile", "?0")
req.Header.Set("User-Agent", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36")
req.Header.Set("app-name", "xy")
req.Header.Set("Content-Type", "application/json;charset=UTF-8")
req.Header.Set("Accept", "application/json, text/plain, */*")
req.Header.Set("device-id", "")
req.Header.Set("os-type", "web")
req.Header.Set("X-Authorization", "token:qgemv4jiy38j4gv6uvhj")
req.Header.Set("Referer", "https://fanyi.caiyunapp.com/")
req.Header.Set("Accept-Language", "zh-CN,zh;q=0.9")
req.Header.Set("Cookie", "_ym_uid=1645984782032859353; _ym_d=1645984782")
//发送请求
resp, err := client.Do(req)
if err != nil {
log.Fatal(err)
}
//避免资源泄漏,手动关闭流
defer resp.Body.Close()
//读取响应
bodyText, err := ioutil.ReadAll(resp.Body)
if err != nil {
log.Fatal(err)
}
fmt.Printf("%s\n", bodyText)
}
但上面的是固定参数,所以这里可以设计一个结构体,将参数传入结构体中,然后调用json.Marshal进行序列化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
package main
import (
"bytes"
"encoding/json"
"fmt"
"io/ioutil"
"log"
"net/http"
"strings"
)
type DictRequest struct {
TransType string `json:"trans_type"`
Source string `json:"source"`
UserID string `json:"user_id"`
}
func main() {
client := &http.Client{}
request := DictRequest{TransType: "en2zh", Source: "good"}
buf, err := json.Marshal(request)
if err != nil {
log.Fatal(err)
}
var data = bytes.NewReader(buf)
req, err := http.NewRequest("POST", "https://api.interpreter.caiyunapp.com/v1/dict", data)
if err != nil {
log.Fatal(err)
}
req.Header.Set("Connection", "keep-alive")
req.Header.Set("DNT", "1")
req.Header.Set("sec-ch-ua-mobile", "?0")
req.Header.Set("User-Agent", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36")
req.Header.Set("app-name", "xy")
req.Header.Set("Content-Type", "application/json;charset=UTF-8")
req.Header.Set("Accept", "application/json, text/plain, */*")
req.Header.Set("device-id", "")
req.Header.Set("os-type", "web")
req.Header.Set("X-Authorization", "token:qgemv4jiy38j4gv6uvhj")
req.Header.Set("Referer", "https://fanyi.caiyunapp.com/")
req.Header.Set("Accept-Language", "zh-CN,zh;q=0.9")
req.Header.Set("Cookie", "_ym_uid=1645984782032859353; _ym_d=1645984782")
resp, err := client.Do(req)
if err != nil {
log.Fatal(err)
}
defer resp.Body.Close()
bodyText, err := ioutil.ReadAll(resp.Body)
if err != nil {
log.Fatal(err)
}
fmt.Printf("%s\n", bodyText)
}
接着设置响应体,进行解析,总代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
package main
import (
"bytes"
"encoding/json"
"fmt"
"io/ioutil"
"log"
"net/http"
"strings"
)
type DictRequest struct {
TransType string `json:"trans_type"`
Source string `json:"source"`
UserID string `json:"user_id"`
}
type DictResponse struct {
Rc int `json:"rc"`
Wiki struct {
KnownInLanguages int `json:"known_in_languages"`
Description struct {
Source string `json:"source"`
Target interface{} `json:"target"`
} `json:"description"`
ID string `json:"id"`
Item struct {
Source string `json:"source"`
Target string `json:"target"`
} `json:"item"`
ImageURL string `json:"image_url"`
IsSubject string `json:"is_subject"`
Sitelink string `json:"sitelink"`
} `json:"wiki"`
Dictionary struct {
Prons struct {
EnUs string `json:"en-us"`
En string `json:"en"`
} `json:"prons"`
Explanations []string `json:"explanations"`
Synonym []string `json:"synonym"`
Antonym []string `json:"antonym"`
WqxExample []string `json:"wqx_example"`
Entry string `json:"entry"`
Type string `json:"type"`
Related interface{} `json:"related"`
Source string `json:"source"`
} `json:"dictionary"`
}
func query(word string) {
client := &http.Client{}
//设置结构体,便于序列化
request := DictRequest{TransType: "en2zh", Source: word}
//序列化
buf, err := json.Marshal(request)
if err != nil {
log.Fatal(err)
}
//将buf包装为io.Reader 类型的数据流对象 data,可以让数据被逐字节地读取,适合用作 HTTP 请求体
var data = bytes.NewReader(buf)
//创建了一个新的 HTTP 请求对象 req,请求方法为 POST
req, err := http.NewRequest("POST", "https://api.interpreter.caiyunapp.com/v1/dict", data)
if err != nil {
log.Fatal(err)
}
//设置请求头
req.Header.Set("Connection", "keep-alive")
req.Header.Set("DNT", "1")
req.Header.Set("sec-ch-ua-mobile", "?0")
req.Header.Set("User-Agent", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36")
req.Header.Set("app-name", "xy")
req.Header.Set("Content-Type", "application/json;charset=UTF-8")
req.Header.Set("Accept", "application/json, text/plain, */*")
req.Header.Set("device-id", "")
req.Header.Set("os-type", "web")
req.Header.Set("X-Authorization", "token:qgemv4jiy38j4gv6uvhj")
req.Header.Set("Referer", "https://fanyi.caiyunapp.com/")
req.Header.Set("Accept-Language", "zh-CN,zh;q=0.9")
req.Header.Set("Cookie", "_ym_uid=1645984782032859353; _ym_d=1645984782")
//进行网络请求
resp, err := client.Do(req)
if err != nil {
log.Fatal(err)
}
defer resp.Body.Close()
//读取响应
bodyText, err := ioutil.ReadAll(resp.Body)
if err != nil {
log.Fatal(err)
}
if resp.StatusCode != 200 {
log.Fatal("bad StatusCode:", resp.StatusCode, "body", string(bodyText))
}
//定义响应体
var dictResponse DictResponse
//反序列化
err = json.Unmarshal(bodyText, &dictResponse)
if err != nil {
log.Fatal(err)
}
fmt.Println(word, "UK:", dictResponse.Dictionary.Prons.En, "US:", dictResponse.Dictionary.Prons.EnUs)
for _, item := range dictResponse.Dictionary.Explanations {
fmt.Println(item)
}
}
func main(){
if(len(os.Args)!=2){
fmt.Println("error")
os.Exit(1)
}
word:=query(os.Args[1])
fmt.Println(word)
}
Socks5代理服务器
作用是在防火墙中开一个端口,便于通过这个端口去访问资源
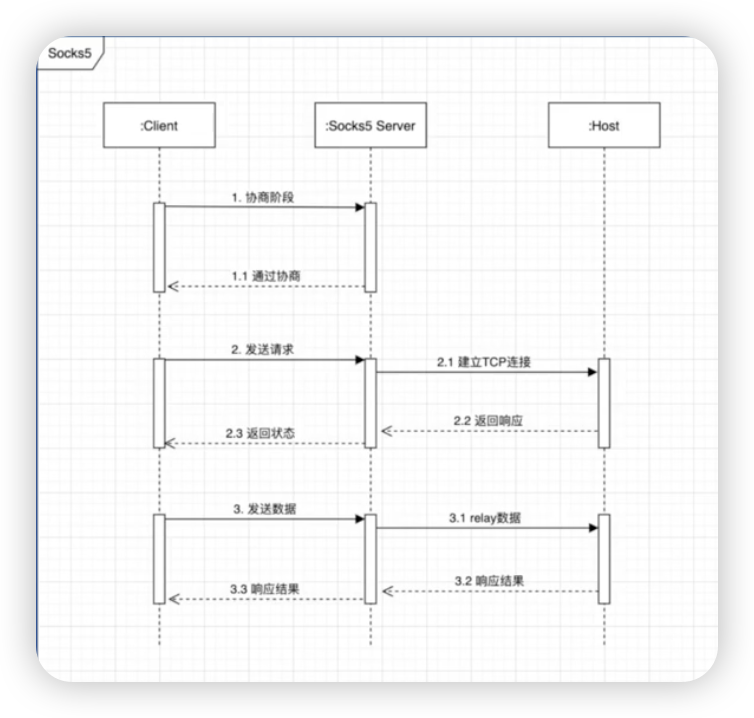
TCP echo server
实现监听,读取信息,打印信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
package main
import (
"bufio"
"log"
"net"
)
func main() {
//监听端口
server, err := net.Listen("tcp", "127.0.0.1:1080")
if err != nil {
panic(err)
}
//在死循环里面用server接受请求
for {
client, err := server.Accept()
if err != nil {
log.Printf("Accept failed %v", err)
continue
}
//启用的gorutinue
go process(client)
}
}
//处理连接
func process(conn net.Conn) {
//关掉连接,连接的生命周期就是函数的声明周期
defer conn.Close()
reader := bufio.NewReader(conn)
for {
b, err := reader.ReadByte()
if err != nil {
break
}
_, err = conn.Write([]byte{b})
if err != nil {
break
}
}
}
实现auth函数,修改源代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
package main
import (
"bufio"
"log"
"net"
)
func main() {
//监听端口
server, err := net.Listen("tcp", "127.0.0.1:1080")
if err != nil {
panic(err)
}
//在死循环里面用server接受请求
for {
client, err := server.Accept()
if err != nil {
log.Printf("Accept failed %v", err)
continue
}
//启用的gorutinue
go process(client)
}
}
// process 函数
func process(conn net.Conn) {
//使用 defer conn.Close() 确保函数退出时自动关闭客户端连接。
defer conn.Close()
//使用 bufio.NewReader 包装客户端连接,方便后续逐字节读取数据
reader := bufio.NewReader(conn)
//调用 auth 函数进行认证
err := auth(reader, conn)
if err != nil {
log.Printf("client %v auth failed: %v", conn.RemoteAddr(), err)
return
}
//授权后,进行连接
err = connect(reader, conn)
if err != nil {
log.Printf("client %v auth failed: %v", conn.RemoteAddr(), err)
return
}
}
// connect 函数
func connect(reader *bufio.Reader, conn net.Conn) (err error) {
// VER | CMD | RSV | ATYP | DST.ADDR | DST.PORT
//之前使用newByte进行读,这里可以先创建一个长度为4的缓冲区
buf := make([]byte, 4)
//接着使用io.ReadFull来填充满
_, err = io.ReadFull(reader, buf)
if err != nil {
return fmt.Errorf("read header failed: %w", err)
}
//接下来就验证每个type的正确性
ver, cmd, atyp := buf[0], buf[1], buf[3]
//检查 ver 是否为 socks5Ver(即 0x05)
if ver != socks5Ver {
return fmt.Errorf("not supported ver: %v", ver)
}
//检查cmd 是否为 cmdBind(即 0x01)
if cmd != cmdBind {
return fmt.Errorf("not supported cmd: %v", ver)
}
var addr string
//使用 switch 语句根据 atyp 的值(地址类型)来选择不同的地址解析方式
switch atyp {
case atypIPv4:
buf = make([]byte, 4)
err = io.ReadFull(reader, buf)
if err != nil {
return fmt.Errorf("read atyp failed: %w", err)
}
addr = fmt.Sprintf("%d.%d.%d.%d", buf[0], buf[1], buf[2], buf[3])
case atypHOST:
//当 atyp 等于 atypHOST(即 0x03)时,首先读取一个字节 hostSize,表示主机名的长度
hostSize, err := reader.ReadByte()
if err != nil {
return fmt.Errorf("read hostSize failed: %w", err)
}
//创建一个长度为 hostSize 的字节数组 host,然后从 reader 中读取指定长度的主机名
host := make([]byte, hostSize)
_, err = io.ReadFull(reader, host)
if err != nil {
return fmt.Errorf("read host failed: %w", err)
}
//将读取到的字节数组转换为字符串形式,存储在 addr 中
addr = string(host)
case atypIPv6:
return errors.New("IPv6: no supported yet")
default:
return errors.New("invalid atyp")
}
//创建一个长度为 2 的字节数组 buf 用于读取端口号
buf = make([]byte, 2)
_, err = io.ReadFull(reader, buf)
if err != nil {
return fmt.Errorf("read port failed: %w", err)
}
//使用 binary.BigEndian.Uint16(buf) 将 2 字节数据转换为无符号的 16 位整数(即端口号),并存储在 port 中
port := binary.BigEndian.Uint16(buf)
//使用 net.Dial("tcp", fmt.Sprintf("%v:%v", addr, port)) 建立一个 TCP 连接
dest, err := net.Dial("tcp", fmt.Sprintf("%v:%v", addr, port))
if err != nil {
return fmt.Errorf("dial dst failed: %w", err)
}
defer dest.Close()
log.Println("dial", addr, port)
// 响应 VER | REP | RSV | ATYP | BND.ADDR | BND.PORT
//向客户端发送一个成功响应,表示代理服务器接受了客户端的请求
_, err = conn.Write([]byte{0x05, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00})
if err != nil {
return fmt.Errorf("write failed: %w", err)
}
return nil
}
// auth 函数实现了 SOCKS5 的认证流程,主要负责协议版本的校验和认证方法的选择
func auth(reader *bufio.Reader, conn net.Conn) (err error) {
// VER | NMETHODS | METHODS
//从客户端读取第一个字节(ver),表示 SOCKS 协议的版本号
ver, err := reader.ReadByte()
if err != nil {
return fmt.Errorf("read ver failed: %w", err)
}
if ver != socks5Ver {
return fmt.Errorf("not supported ver: %v", ver)
}
//从客户端读取一个字节,表示客户端支持的认证方法数量
methodSize, err := reader.ReadByte()
if err != nil {
return fmt.Errorf("read methodSize failed: %w", err)
}
//根据 methodSize 的大小,创建一个字节数组 method,用于存储客户端支持的认证方法
//创建io的缓冲区
method := make([]byte, methodSize)
//ReadFull来填充满,指定数量的字节(即 methodSize 个字节)到 method 数组中
_, err = io.ReadFull(reader, method)
if err != nil {
return fmt.Errorf("read method failed: %w", err)
}
log.Println("ver", ver, "method", method)
// 返回 VER | METHOD
//服务器在认证阶段完成后,向客户端发送一个响应,表示协议版本和认证状态
_, err = conn.Write([]byte{socks5Ver, 0x00})
if err != nil {
return fmt.Errorf("write failed: %w", err)
}
//接下来就可以浏览器服务器间进行双向数据转化
//正常如果就创建两个go线程进行数据交换,主线程就会直接到最后一行导致函数结束,所以这里需要用到context,主线程会停止在Done那里,直到等到context执行完成,即某一方完成或发生错误时,将会调用 cancel(),解除阻塞,主 goroutine 继续执行,进而退出当前函数。
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
go func() {
_, _ = io.Copy(dest, reader)
cancel()
}()
go func() {
_, _ = io.Copy(conn, dest)
cancel()
}()
<-ctx.Done()
return nil
}
工程实践
并发编程
CSP强调通过通信的方式实现多个独立进程之间的协作。
Go语言中采用了CSP的理念,通过goroutine和channel来实现并发编程的简单化和高效化
channel用于gorountinue之间进行数据交换
Channel
Channel可以分为无缓冲channel和有缓冲channel两种
-
无缓冲Channel
无缓冲channel在发送和接收时都会阻塞,直到另一方准备好为止。它要求发送者和接收者必须在同一时刻准备好,才能完成数据传递。这种同步特性确保了goroutine之间的严格时序依赖
1
ch := make(chan int) // 无缓冲channel
-
有缓冲Channel
有缓冲channel允许在channel中暂时存储一定数量的数据,从而使得发送者和接收者不必完全同步
1
ch := make(chan int, 3) // 创建一个缓冲区大小为3的channel
channel使用实例
这里考虑的是一个生产者消费者的问题,打印作为消费者,dest属于生产者,考虑消费者可能要慢一些
可以使用带缓冲的通道,即用于生产者和消费者速率不一致,且希望能暂存数据,避免发送者频繁地阻塞等待接收者,用于需要提高系统的吞吐量,减少不必要的阻塞
无缓冲channel适合需要严格同步行为,发送和接收必须在同一时间发生
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
func CalSquare() {
src := make(chan int)
dest := make(chan int, 3)
go func() {
defer close(src)
for i := 0; i < 10; i++ {
src <- i
}
}()
go func() {
defer close(dest)
for i := range src {
dest <- i * i
}
}()
for i := range dest {
// 复杂操作
println(i)
}
}
defer close(dest) 是 Go 语言中的一种延迟操作,结合 defer 和 close 函数,它的作用是确保 dest 这个 channel 在函数退出前被关闭
Lock
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
package main
import (
"fmt"
"sync"
"time"
)
var (
x int64
lock sync.Mutex
)
func addWithLock() {
for i := 0; i < 2000; i++ {
lock.Lock()
x += 1
lock.Unlock()
}
}
func addWithoutLock() {
for i := 0; i < 2000; i++ {
x += 1
}
}
func Add() {
x = 0
for i := 0; i < 5; i++ {
go addWithoutLock()
}
//休息一秒
time.Sleep(time.Second)
//8382
fmt.Println("WithoutLock:", x)
x = 0
for i := 0; i < 5; i++ {
go addWithLock()
}
time.Sleep(time.Second)
//10000
fmt.Println("WithLock:", x)
}
func main() {
Add()
}
上面让线程等待用的sleep,其实是可以使用WaitGroup 是一个常用的工具,用于管理多个goroutine之间的同步,确保所有的goroutine都完成后再继续执行主goroutine
WaitGroup
WaitGroup 有三个主要的方法:
• Add(delta int):用于设置等待的goroutine数量。
• Done():表示一个goroutine完成,WaitGroup的计数器减一。
• Wait():阻塞主goroutine,直到所有被等待的goroutine完成。
1
2
3
4
5
6
7
8
9
10
11
12
13
func ManyGoWait() {
var wg sync.WaitGroup
wg.Add(5)
for i := 0; i < 5; i++ {
go func(j int) {
defer wg.Done()
hello(j)
}(i)
}
wg.Wait()
}
依赖管理
go的依赖管理有三个阶段:GOPATH-Go Vendor-Go Module
GOPATH

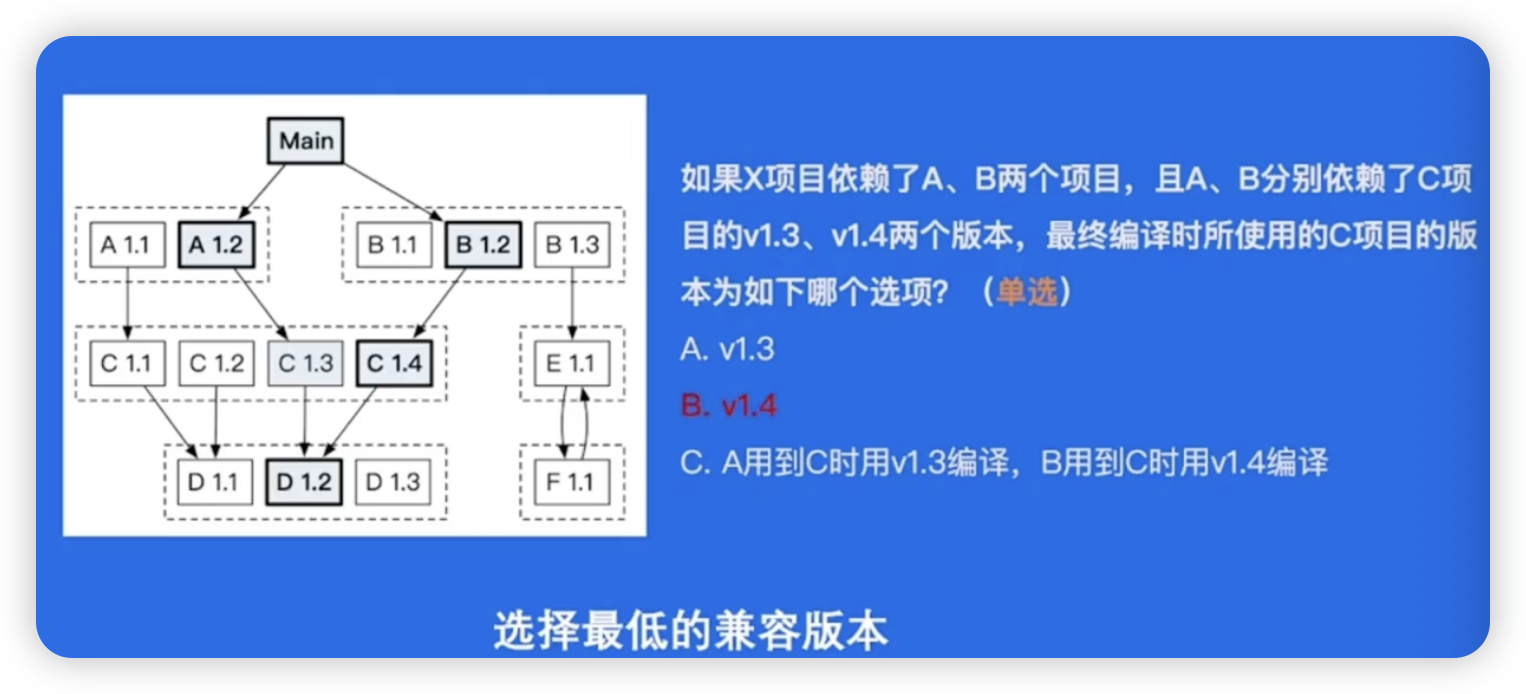
弊端:如果两个项目依赖于某一个package的不同版本,就无法实现package的多版本控制
Go Vendor

弊端:如果项目A依赖于项目B和C,这是可以写到vendor中的,但如果项目B依赖于项目D的v1版本,项目c依赖于项目D的v2版本,这样就可能造成依赖冲突,导致编译错误
Go Module
- 通过 go.mod 文件管理依赖包版本
- 通过 go get/go mod 指令工具管理依赖包
依赖管理的三要素
- 配置文件,描述依赖 go.mod
- 中心仓库管理依赖库 Proxy
- 本地工具 go get/go mod
一个go.mod文件包含下面部分
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// Go 模块系统中的一条声明语句,用于定义当前项目的模块名称
module example/project/app // 依赖管理基本单元
go 1.16 // 使用 Go 1.16 版本
//当前项目的依赖
require (
example/lib1 v1.0.2
example/lib2 v1.0.0 // indirect
example/lib3 v0.1.0-20190725025543-5a5fe074e612
example/lib4 v0.0.0-20180306012644-bacd9c7ef1dd // indirect
example/lib5/v3 v3.0.2
example/lib6 v3.2.0+incompatible
)
indirect
用于标识非直接依赖
incompatible
用于表示该模块的版本与 Go 模块系统不完全兼容,尤其是指这个模块没有符合模块化版本管理的要求,但仍然可以被使用
依赖分发
Go Proxy(代理)是一个模块代理服务器,它从源代码仓库(如 GitHub、GitLab 等)获取模块并缓存下来,以便更快速和更可靠地提供给开发者
当你在项目中添加一个新的依赖(比如运行 go get 命令)时,Go 工具链首先会尝试从 Proxy 中获取该模块。如果 Proxy 找不到这个模块,才会去模块的源代码仓库下载
1
export GOPROXY="https://proxy1.cn,https://proxy2.cn,direct"
go工具
-
go mod init:
- 用于初始化模块并创建 go.mod 文件。
- 通过执行这个命令,你可以为当前项目开启模块支持,并创建一个 go.mod 文件来管理模块的依赖和版本。
-
go mod download:
-
下载项目中依赖的模块到本地缓存。
-
这个命令会读取 go.mod 文件中的依赖信息,并将这些模块的源代码下载到本地,以便在编译和构建过程中使用。
-
-
go mod tidy:
- 自动整理模块依赖。
- 它会扫描项目中的代码文件,检查所有实际使用到的模块,并将其添加到 go.mod 文件中。同时,它还会删除那些不再使用的依赖模块,使 go.mod 文件保持整洁。
测试
单元测试
规则:
-
所有测试文件以_test.go结尾
-
func TestXxx(* testing.T)
1 2 3 4 5 6 7 8 9 10 11
package main import "testing" func TestHelloTom(t *testing.T) { output := HelloTom() expectOutput := "Tom" if output != expectOutput { t.Errorf("Expected %s do not match actual %s", expectOutput, output) } }
-
初始化逻辑放到TestMain中
1 2 3 4 5 6 7
func TestMain(m *testing.M) { // 测试前:数据装载、配置初始化等前置工作 //这个代码标识跑这个package下的所有测试 code := m.Run() // 测试后:释放资源等收尾工作 os.Exit(code) }
执行流程:
当你运行 go test 命令时,Go 会自动:
1. 加载测试文件(文件名以 _test.go 结尾)。
2. 查找测试函数(函数名以 Test 开头,并且接收 *testing.T 参数)。
3. 自动调用这些测试函数并执行测试逻辑。
测试框架实际上会生成一个临时的 main 函数来启动整个测试过程。这个临时的 main 函数由 Go 的 testing 包生成,并且会调用所有符合条件的测试函数。
覆盖率
使用 go test 命令的 -cover 和相关选项来生成代码覆盖率报告,从而了解测试代码对程序代码的覆盖程度。
Mock测试
在测试环境中模拟依赖组件的行为,以隔离和验证系统的某个部分。Mock的核心思想是用“伪造的对象”(Mock对象)代替真实的依赖对象,以便控制测试场景和验证代码逻辑
允许你只关注被测试的代码,而不依赖外部组件(如数据库、API、文件系统等)。这能避免外部依赖的不确定性对测试结果的干扰
函数级别的打桩
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
package main
import (
"fmt"
"time"
"bou.ke/monkey"
)
func GetCurrentTime() string {
return time.Now().Format("2006-01-02 15:04:05")
}
func main() {
// 打桩:用自定义函数替换 time.Now
monkey.Patch(time.Now, func() time.Time {
return time.Date(2022, 1, 1, 0, 0, 0, 0, time.UTC)
})
// 调用打桩后的函数
fmt.Println(GetCurrentTime()) // 输出固定时间:2022-01-01 00:00:00
// 恢复原始函数
monkey.Unpatch(time.Now)
// 调用恢复后的函数
fmt.Println(GetCurrentTime()) // 输出真实系统时间
}
方法级别的打桩
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
package main
import (
"fmt"
"github.com/stretchr/testify/mock"
)
// 定义一个接口
type Database interface {
Query(sql string) string
}
// 一个真实的实现
type RealDatabase struct{}
func (db *RealDatabase) Query(sql string) string {
return "Real database result"
}
// 模拟的实现(打桩)
type MockDatabase struct {
mock.Mock
}
func (db *MockDatabase) Query(sql string) string {
args := db.Called(sql)
return args.String(0)
}
func main() {
// 使用 MockDatabase 打桩
mockDB := new(MockDatabase)
mockDB.On("Query", "SELECT * FROM users").Return("Mock result")
// 测试代码调用
result := mockDB.Query("SELECT * FROM users")
fmt.Println(result) // 输出:Mock result
}
基准测试
通过测试某段代码的性能,评估其在特定条件下的执行效率。它的目的是衡量代码的运行速度或资源消耗,比如执行时间、CPU占用率或内存使用量等
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
//进行单线程的基准测试
func BenchmarkSelect(b *testing.B) {
//初始化一些资源
InitServerIndex()
//清除初始化阶段的时间消耗,确保只记录测试代码的执行时间
b.ResetTimer()
//使用 for 循环运行 b.N 次(b.N 是基准测试框架自动调整的运行次数),测试 Select() 函数的性能
for i := 0; i < b.N; i++ {
Select()
}
}
//进行并发的基准测试
func BenchmarkSelectParallel(b *testing.B) {
InitServerIndex()
b.ResetTimer()
//RunParallel 会启动多个 Goroutine,并行运行测试代码
b.RunParallel(func(pb *testing.PB) {
//每个 Goroutine 会调用 pb.Next() 来确定是否还有剩余的测试任务
for pb.Next() {
Select()
}
})
}
社区项目
也是采用MVC三层结构,用到Gin web框架,使用Go Mod管理依赖
-
使用 go mod init进行go项目初始化
-
接着 go get gopkg.in/gin-gonic/gin.v1@v1.3.0 创建gin项目
-
创建repository层
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67
package repository import ( "github.com/Moonlight-Zhao/go-project-example/util" "gorm.io/gorm" "sync" "time" ) type Post struct { Id int64 `gorm:"column:id"` ParentId int64 `gorm:"parent_id"` UserId int64 `gorm:"column:user_id"` Content string `gorm:"column:content"` DiggCount int32 `gorm:"column:digg_count"` CreateTime time.Time `gorm:"column:create_time"` } func (Post) TableName() string { return "post" } type PostDao struct { } var postDao *PostDao var postOnce sync.Once func NewPostDaoInstance() *PostDao { postOnce.Do( func() { postDao = &PostDao{} }) return postDao } func (*PostDao) QueryPostById(id int64) (*Post, error) { var post Post err := db.Where("id = ?", id).Find(&post).Error if err == gorm.ErrRecordNotFound { return nil, nil } if err != nil { util.Logger.Error("find post by id err:" + err.Error()) return nil, err } return &post, nil } func (*PostDao) QueryPostByParentId(parentId int64) ([]*Post, error) { var posts []*Post err := db.Where("parent_id = ?", parentId).Find(&posts).Error if err != nil { util.Logger.Error("find posts by parent_id err:" + err.Error()) return nil, err } return posts, nil } func (*PostDao) CreatePost(post *Post) error { if err := db.Create(post).Error; err != nil { util.Logger.Error("insert post err:" + err.Error()) return err } return nil }
-
创建service层
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136
package service import ( "errors" "fmt" "github.com/Moonlight-Zhao/go-project-example/repository" "sync" ) type TopicInfo struct { Topic *repository.Topic User *repository.User } type PostInfo struct { Post *repository.Post User *repository.User } type PageInfo struct { TopicInfo *TopicInfo PostList []*PostInfo } func QueryPageInfo(topicId int64) (*PageInfo, error) { return NewQueryPageInfoFlow(topicId).Do() } func NewQueryPageInfoFlow(topId int64) *QueryPageInfoFlow { return &QueryPageInfoFlow{ topicId: topId, } } type QueryPageInfoFlow struct { topicId int64 pageInfo *PageInfo topic *repository.Topic posts []*repository.Post userMap map[int64]*repository.User } func (f *QueryPageInfoFlow) Do() (*PageInfo, error) { if err := f.checkParam(); err != nil { return nil, err } if err := f.prepareInfo(); err != nil { return nil, err } if err := f.packPageInfo(); err != nil { return nil, err } return f.pageInfo, nil } func (f *QueryPageInfoFlow) checkParam() error { if f.topicId <= 0 { return errors.New("topic id must be larger than 0") } return nil } func (f *QueryPageInfoFlow) prepareInfo() error { //获取topic信息 var wg sync.WaitGroup wg.Add(2) var topicErr, postErr error go func() { defer wg.Done() topic, err := repository.NewTopicDaoInstance().QueryTopicById(f.topicId) if err != nil { topicErr = err return } f.topic = topic }() //获取post列表 go func() { defer wg.Done() posts, err := repository.NewPostDaoInstance().QueryPostByParentId(f.topicId) if err != nil { postErr = err return } f.posts = posts }() wg.Wait() if topicErr != nil { return topicErr } if postErr != nil { return postErr } //获取用户信息 uids := []int64{f.topic.Id} for _, post := range f.posts { uids = append(uids, post.Id) } userMap, err := repository.NewUserDaoInstance().MQueryUserById(uids) if err != nil { return err } f.userMap = userMap return nil } func (f *QueryPageInfoFlow) packPageInfo() error { //topic info userMap := f.userMap topicUser, ok := userMap[f.topic.UserId] if !ok { return errors.New("has no topic user info") } //post list postList := make([]*PostInfo, 0) for _, post := range f.posts { postUser, ok := userMap[post.UserId] if !ok { return errors.New("has no post user info for " + fmt.Sprint(post.UserId)) } postList = append(postList, &PostInfo{ Post: post, User: postUser, }) } f.pageInfo = &PageInfo{ TopicInfo: &TopicInfo{ Topic: f.topic, User: topicUser, }, PostList: postList, } return nil }
-
创建controller层,也可以写成handler层
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39
package handler import ( "strconv" "github.com/Moonlight-Zhao/go-project-example/service" ) type PageData struct { Code int64 `json:"code"` Msg string `json:"msg"` Data interface{} `json:"data"` } func QueryPageInfo(topicIdStr string) *PageData { //参数转换 topicId, err := strconv.ParseInt(topicIdStr, 10, 64) if err != nil { return &PageData{ Code: -1, Msg: err.Error(), } } //获取service层结果 pageInfo, err := service.QueryPageInfo(topicId) if err != nil { return &PageData{ Code: -1, Msg: err.Error(), } } return &PageData{ Code: 0, Msg: "success", Data: pageInfo, } }
-
创建sever.go函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53
package main import ( "github.com/Moonlight-Zhao/go-project-example/handler" "github.com/Moonlight-Zhao/go-project-example/repository" "github.com/Moonlight-Zhao/go-project-example/util" "gopkg.in/gin-gonic/gin.v1" "os" ) func main() { if err := Init(); err != nil { os.Exit(-1) } r := gin.Default() r.Use(gin.Logger()) r.GET("/ping", func(c *gin.Context) { c.JSON(200, gin.H{ "message": "pong", }) }) r.GET("/community/page/get/:id", func(c *gin.Context) { topicId := c.Param("id") data := handler.QueryPageInfo(topicId) c.JSON(200, data) }) r.POST("/community/post/do", func(c *gin.Context) { uid, _ := c.GetPostForm("uid") topicId, _ := c.GetPostForm("topic_id") content, _ := c.GetPostForm("content") data := handler.PublishPost(uid, topicId, content) c.JSON(200, data) }) err := r.Run() if err != nil { return } } func Init() error { if err := repository.Init(); err != nil { return err } if err := util.InitLogger(); err != nil { return err } return nil }
-
运行 go run sever.go
编码规范
异常处理
-
errors.New
用于创建一个简单的错误,返回值是一个 error 类型
-
errors.As
用于类型断言,检查一个错误是否可以转换为特定的错误类型,并在可能的情况下提取该错误类型
-
errors.Is
用于判断一个错误是否等于另一个错误(或者是否可以解包为某个特定错误)。
-
fmt.Errorf
用于创建一个格式化的错误消息,支持嵌套和包裹其他错误
Go 中提供了 panic 和 recover 来处理不可恢复的错误,但不建议在常规错误处理中使用。
注意:defer语句会在函数返回前调用,多个defer语句是后进先出
性能优化
性能优化建议
Slice
尽可能在使用make()初始化切片时提供容量信息
另一个陷阱:大内存未释放
-
在已有切片基础上创建切片,不会创建新的底层数组
-
场景
原切片较大,代码在原切片基础上新建小切片
原底层数组在内存中有引用,得不到释放
-
可使用 copy 替代 re-slice
Strings.Builder
-
使用 + 拼接性能最差,strings.Builder、bytes.Buffer 相近,strings.Buffer 更快
-
分析
- 字符串在 Go 语言中是不可变类型,占用内存大小是固定的
- 使用 + 每次都会重新分配内存
- strings.Builder、bytes.Buffer 底层都是 []byte 数组
- 内存扩容策略,不需要每次拼接重新分配内存
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
package main
import (
"fmt"
"strings"
)
func main() {
var builder strings.Builder
// 写入字符串
builder.WriteString("Hello, ")
builder.WriteString("World!")
// 写入单个字符
builder.WriteByte(' ')
// 追加更多内容
builder.WriteString("Go is great.")
// 获取最终的字符串
result := builder.String()
fmt.Println(result) // 输出:Hello, World! Go is great.
// 检查容量和长度
fmt.Println("Length:", builder.Len())
fmt.Println("Capacity:", builder.Cap())
}
空结构体(struct{})
空结构体节省内存来实现 Set 数据结构
在 Go 中,struct{} 是一种特殊的结构体类型,它不包含任何字段,因此它的内存占用为零。这可以用于 map 的值类型,以替代其他类型(如 bool),从而节省内存
在实现 Set 时,只需要用到键,而不关心值,可以利用 map[KeyType]struct{},其中键是需要存储的元素,值是空结构体struct{}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
package main
import "fmt"
// Set 定义
type Set[T comparable] struct {
data map[T]struct{}
}
// NewSet 创建一个新的 Set
func NewSet[T comparable]() *Set[T] {
return &Set[T]{data: make(map[T]struct{})}
}
// Add 添加元素到 Set 中
func (s *Set[T]) Add(item T) {
s.data[item] = struct{}{} // 使用空结构体作为值
}
// Remove 从 Set 中移除元素
func (s *Set[T]) Remove(item T) {
delete(s.data, item)
}
// Contains 检查元素是否在 Set 中
func (s *Set[T]) Contains(item T) bool {
_, exists := s.data[item]
return exists
}
// Size 返回 Set 的大小
func (s *Set[T]) Size() int {
return len(s.data)
}
// 示例使用
func main() {
set := NewSet[string]()
set.Add("Go")
set.Add("Python")
set.Add("Java")
fmt.Println("Set contains 'Go':", set.Contains("Go")) // 输出: true
fmt.Println("Set size:", set.Size()) // 输出: 3
set.Remove("Python")
fmt.Println("Set contains 'Python':", set.Contains("Python")) // 输出: false
fmt.Println("Set size:", set.Size()) // 输出: 2
}
atomic包
使用atomic包,而避免使用锁,能提高效率
1
2
3
4
5
6
7
type atomicCounter struct {
i int32
}
func AtomicAddOne(c *atomicCounter) {
atomic.AddInt32(&c.i, 1)
}
性能优化分析工具
性能调优原则
- 要依靠数据不是猜测
- 要定位最大瓶颈而不是细枝末节
- 不要过早优化
- 不要过度优化
性能分析工具pprof
测试项目运行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
package main
import (
"log"
"net/http"
_ "net/http/pprof"
"os"
"runtime"
)
func main() {
log.SetFlags(log.Lshortfile | log.LstdFlags)
log.SetOutput(os.Stdout)
// 配置运行时参数
runtime.GOMAXPROCS(1) // 限制 CPU 使用数
runtime.SetMutexProfileFraction(1) // 开启锁调用跟踪
runtime.SetBlockProfileRate(1) // 开启阻塞调用跟踪
// 启动 HTTP 服务,用于 pprof 分析
go func() {
log.Println("Starting pprof server on :6060")
if err := http.ListenAndServe(":6060", nil); err != nil {
log.Fatal(err)
}
}()
// 阻止程序退出
select {} // 主协程阻塞
}
cpu排查
-
在终端输入
1
go tool pprof "http://localhost:6060/debug/pprof/profile?seconds=10"
-
输入top
Flat==Cum:Flat是函数本身的消耗,相等说明没有其他的调用
Flat==0:函数只有其他函数的调用
-
list xx
定位消耗
内存排查
-
在终端输入
1
go tool pprof --http=:8080 "http://localhost:6060/debug/pprof/heap"
pprof采样过程
CPU
- 操作系统
- 每10ms向进程发送一次SIGPROF信号
- 进程
- 每次接收到SIGPROF会记录调用堆栈
- 写缓冲
- 每100ms读取已经记录的调用堆栈并写入输出流
Heap - 堆内存
- 采样程序通过内存分配器在堆上分配和释放的内存,记录分配/释放的大小和数量
- 采样率:每分配512KB记录一次,可在运行开头修改,1为每次分配均记录
- 采样时间:从程序运行开始到采样时
- 采样指标:alloc_space, alloc_objects, inuse_space, inuse_objects
- 计算方式:inuse = alloc - free
Goroutine - 协程 & ThreadCreate - 线程创建
- Goroutine
- 记录所有用户发起且在运行中的goroutine(即入口非runtime开头的)
- runtime.main的调用栈信息
- ThreadCreate
- 记录程序创建的所有系统线程的信息
自动内存管理
垃圾回收器
- Mutator:业务线程,分配新对象,修改对象指向关系
- Collector:GC线程,找到存活对象,回收死亡对象的内存空间
- Serial GC:只有一个collector
- Parallel GC:支持多个collectors同时回收的GC算法
- Concurrent GC:mutator和collector可以同时执行
评价GC算法参数
-
安全性(Safety):
基本要求是不能回收存活的对象。也就是说,GC在工作时不能误回收程序中还在使用的对象,否则会导致程序出错。
-
吞吐率(Throughput):
定义为:1 - (GC时间 / 程序执行总时间)
吞吐率衡量的是程序花费在业务逻辑执行上的时间比例,GC时间越短,吞吐率越高。
-
暂停时间(Pause Time):
Stop the World (STW)。GC运行时会暂停所有程序执行,暂停时间越短,业务受到的影响越小。
-
内存开销(Space Overhead):
指的是垃圾回收需要的额外内存,如元数据开销。GC算法要尽可能减少额外的内存使用。
GC策略:
-
追踪垃圾回收(Tracing Garbage Collection)
利用可达性分析来判断哪些对象是垃圾
通过遍历引用图来判断哪些对象是垃圾,例如标记-清除(Mark-Sweep)、复制(Copying)等算法。
对于选择哪种垃圾回收算法,可以使用分代垃圾回收算法,分为年轻代,老年代,对于年轻代可以使用标记复制,对于老年代使用标记清除
-
引用计数(Reference Counting):
通过计数对象被引用的次数来判断对象是否可以回收。优点是即时回收,缺点是无法处理循环引用。
优点:内存管理的操作被平摊到程序执行过程中,内存管理不需要了解runtime的实现细节
缺点:如果成环,就无法回收
相关书籍:THE GARBAGE COLLECTION HANDBOOK
Go内存分配
分块思想
需要在堆上分配内存时,Go语言的内存管理器会通过分块机制提高分配效率,并尽量减少系统调用的频率
流程如下:
-
调用系统接口申请大块内存:
Go语言使用系统调用(如mmap())向操作系统申请大块的内存,一次性分配较大的内存区域,例如4MB。
这样做可以避免频繁向操作系统申请小块内存,提高效率。
-
将内存分成更小的块(mspan):
申请到的大块内存会被进一步划分成固定大小的内存块,例如 8KB。
这些固定大小的内存块被称为 mspan,是Go语言内存分配的基本单位。
-
根据对象大小划分更小的内存单元:
每个mspan会继续细分成特定大小的更小内存单元(8字节、16字节、24字节等),这些内存单元专门用于对象分配。
通过这种分级管理,可以快速找到适合的内存块,提高分配效率。

缓存思想
流程如下:
-
快速分配(mcache):
当Goroutine需要分配内存时,优先从P的mcache中分配。
mcache会根据对象的大小选择合适的mspan,直接从中分配内存块。
-
mspan耗尽时(向mcentral申请):
如果mcache中的某个mspan分配完毕,mcache会向mcentral申请新的mspan。
mcentral是共享的,负责为多个P提供未使用的mspan。
-
mcentral不足时(向mheap申请):
如果mcentral中也没有合适的mspan,它会从mheap中申请新的Heap Arena(通常是大块内存,比如4MB),然后切分成多个mspan,返回给mcentral。
-
未使用的mspan处理:
当mspan中没有未分配的内存块时,mspan会被缓存到mcentral,供其他P使用,而不是立即释放给操作系统。
这种做法减少了对操作系统的频繁调用,提高了内存分配效率。
g指的Goroutine,m是Machine,线程,p是Processor,处理器
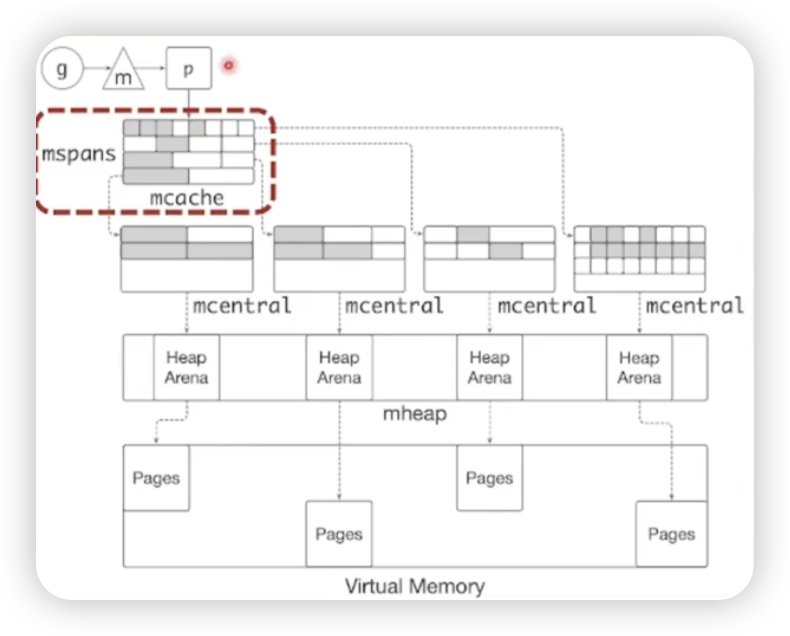
Go内存管理优化
对象分配的特点:
- 对象分配是非常高频的操作:每秒分配GB级别的内存
- 小对象占比高
- Go内存分配比较耗时,分配路径很长:g-m-p-mcache-mspan-memory block-return pointer
优化方案:Balanced GC
-
每个 g 都绑定一大块内存(1 KB),称作 goroutine allocation buffer (GAB)
-
GAB 用于 noscan 类型的小对象分配:< 128 B
-
使用三个指针维护 GAB:base, end, top
分配大小为size,每次判断top+size和end的大小关系,来判断是否进行分配
-
Bump pointer(指针碰撞)风格对象分配
- 无须和其他分配请求互斥
- 分配动作简单高效
这种方式相当于把多个小对象的分配合并成一次大对象的分配,但缺点也很明显,就是可能存在内存碎片,并且回收的时候肯定是要整体回收的,所以如果一整个gap里面只有一个对象存活,那其他的空间也不能回收
针对这个问题,采用了移动对象的方式进行解决,即GAB总大小超过一定阈值的时候,将GAB中存活的对象复制到另外分配的GAB中,原来的GAB就可以直接释放
编译器优化
静态分析
1、控制流和数据流
发现程序的性质,进而进行程序的优化
2、过程内分析和过程间分析
过程内分析:仅在函数内存分析
过程见分析:考虑函数调用时参数传递和返回值的数据流和控制流
函数内联
- 内联:将被调用函数的函数体(callee)的副本替换到调用位置(caller)上,同时重写代码以反映参数的绑定
- 优点:
- 消除函数调用开销,例如传递参数、保存寄存器等
- 将过程间分析转化为过程内分析,帮助其他优化,例如逃逸分析
- 缺点:
- 函数体变大
- 编译生成的Go镜像变大
逃逸分析
分析代码中指针动态作用域
- 从对象分配处出发,沿着控制流,观察对象的数据流
- 若发现指针p在当前作用域,发生如下情况
- 作为参数传递给其他函数
- 传递给全局变量
- 传递给其他goroutine
- 传递给已逃逸的指针指向的对象
- 则指针p指向的对象逃逸
优化方式:比如通过函数内联,扩展函数边界,使得对象不再逃逸,那么就可以在栈上进行分配
GORM
database/sql
基本用法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
import (
//统一的接口
"database/sql"
//不同的数据库使用不同的驱动
//_是一个匿名标识符,,表示“引入但不直接使用”
//对于导入包时的_,它的作用是触发包的初始化(init()函数),而不直接通过包名引用它的功能
//即引入github.com/go-sql-driver/mysql包,但我们不会直接通过mysql名称调用它的函数或方法
_ "github.com/go-sql-driver/mysql"
)
func main() {
db, err := sql.Open("mysql", "user:password@tcp(127.0.0.1:3306)/hello")
if err != nil {
// xxx
}
rows, err := db.Query("select id, name from users where id = ?", 1)
if err != nil {
// xxx
}
//每次操作完 需要释放链接
defer rows.Close()
var users []User
for rows.Next() {
var user User
//将 rows 结果集中当前行的第一个列值赋值到 user.ID,第二个列值赋值到 user.Name
err := rows.Scan(&user.ID, &user.Name)
if err != nil {
// ...
}
users = append(users, user)
}
//不是数据相关的错误 从这里返回
if rows.Err() != nil {
// ...
}
}
ORM框架使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
import (
"gorm.io/gorm"
"gorm.io/driver/mysql"
)
func main() {
db, err := gorm.Open(
mysql.Open("user:password@tcp(127.0.0.1:3306)/hello"),
)
if err != nil {
panic(err)
}
var users []User
err = db.Select("id", "name").Find(&users, 1).Error
if err != nil {
panic(err)
}
}
基本用法
-
操作数据库
1 2
db.AutoMigrate(&Product{}) // 自动迁移,创建或更新表结构 db.Migrator().CreateTable(&Product{}) // 手动创建表
-
创建记录
1 2 3 4 5 6 7 8 9 10 11
user := User{ Name: "Jinzhu", Age: 18, Birthday: time.Now(), } result := db.Create(&user) // 将 user 数据插入到数据库中 // 创建后的返回值 user.ID // 返回主键 ID(last insert id) result.Error // 返回错误信息(若无错误为 nil) result.RowsAffected // 返回影响的行数
-
批量创建
1 2 3 4 5 6 7 8 9 10 11 12
var users = []User{ {Name: "jinzhu1"}, {Name: "jinzhu2"}, {Name: "jinzhu3"}, } db.Create(&users) // 一次性创建所有用户 db.CreateInBatches(users, 100) // 分批创建用户,每批 100 个 // 遍历插入结果 for _, user := range users { user.ID // 插入后,每个 user 的 ID 自动更新 }
-
读取数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14
var product Product // 查询 id 为 1 的 product db.First(&product, 1) // 查询 code 为 "L1212" 的 product db.First(&product, "code = ?", "L1212") // 查询多个记录 result := db.Find(&users, []int{1, 2, 3}) result.RowsAffected // 返回找到的记录数 // 检查是否未找到记录 errors.Is(result.Error, gorm.ErrRecordNotFound) // 检查是否是未找到记录的错误
-
更新字段
1 2
db.Model(&product).Update("Price", 2000) // 更新单个字段 db.Model(&product).UpdateColumn("Price", 2000) // 更新单个字段(直接更新数据库,不触发钩子)
-
更新多个字段
1 2
db.Model(&product).Updates(Product{Price: 2000, Code: "L1212"}) // 使用结构体更新多个字段 db.Model(&product).Updates(map[string]interface{}{"Price": 2000, "Code": "L1212"}) // 使用 Map 更新多个字段
-
批量更新
1
db.Model(&Product{}).Where("price < ?", 2000).Updates(map[string]interface{}{"Price": 2000})
-
删除
1
db.Delete(&product) // 删除指定的 product 记录
模型定义
1
2
3
4
5
6
7
8
9
10
11
12
type User struct {
ID uint // 用户 ID(无符号整数,通常为主键)
Name string // 用户名
Email *string // 用户邮箱(可为空,使用指针类型)
Age uint8 // 用户年龄(8 位无符号整数)
Birthday *time.Time // 生日(可为空,使用指针类型)
MemberNumber sql.NullString // 会员编号(支持 NULL 值的字符串)
ActivatedAt sql.NullTime // 激活时间(支持 NULL 值的时间类型)
CreatedAt time.Time // 创建时间(通常自动填充)
UpdatedAt time.Time // 更新时间(通常自动填充)
DeletedAt gorm.DeletedAt `gorm:"index"` // 删除时间(用于软删除,带索引)
}
也可以嵌套
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
type User struct {
gorm.Model // 嵌套 GORM 的基础模型字段(包括 ID、CreatedAt 等)
Name string // 用户名
Email *string // 邮箱,指针类型,表示可以为空
Age uint8 // 年龄,无符号 8 位整数
Birthday *time.Time // 生日,指针类型,表示可以为空
MemberNumber sql.NullString // 会员编号,可为空
ActivatedAt sql.NullTime // 激活时间,可为空
}
// gorm.io/gorm
type Model struct {
ID uint `gorm:"primaryKey"` // 主键
CreatedAt time.Time // 创建时间,自动填充
UpdatedAt time.Time // 更新时间,自动填充
DeletedAt gorm.DeletedAt `gorm:"index"` // 软删除时间,带索引
}
关联操作
即多表操作时,可以通过Preload/Joins操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
package main
import (
"fmt"
"gorm.io/driver/sqlite"
"gorm.io/gorm"
)
// 模型定义
type User struct {
ID uint
Name string
Orders []Order `gorm:"foreignKey:UserID"` // 一对多关联
Profile Profile `gorm:"foreignKey:UserID"` // 一对一关联
}
type Profile struct {
ID uint
UserID uint
Age int
Bio string
}
type Order struct {
ID uint
UserID uint
OrderName string
State string
OrderItems []OrderItem `gorm:"foreignKey:OrderID"` // 一对多关联
}
type OrderItem struct {
ID uint
OrderID uint
ProductID uint
Product Product `gorm:"foreignKey:ID"` // 一对一关联
}
type Product struct {
ID uint
Name string
Price float64
}
func main() {
// 初始化数据库连接
db, err := gorm.Open(sqlite.Open("test.db"), &gorm.Config{})
if err != nil {
panic("failed to connect database")
}
// 自动迁移,创建表
db.AutoMigrate(&User{}, &Profile{}, &Order{}, &OrderItem{}, &Product{})
// 数据准备
initData(db)
// 查询并预加载数据
var users []User
//如果不使用预加载的话就会懒加载,不加载其他数据
// 示例 1: 基础预加载
db.Preload("Orders").Preload("Profile").Find(&users)
fmt.Println("基础预加载:")
for _, user := range users {
fmt.Printf("User: %s, Orders: %d, Profile: %v\n", user.Name, len(user.Orders), user.Profile)
}
// 示例 2: 多级预加载
db.Preload("Orders.OrderItems.Product").Find(&users)
fmt.Println("\n多级预加载:")
for _, user := range users {
fmt.Printf("User: %s\n", user.Name)
for _, order := range user.Orders {
fmt.Printf(" Order: %s\n", order.OrderName)
for _, item := range order.OrderItems {
fmt.Printf(" Product: %s, Price: %.2f\n", item.Product.Name, item.Product.Price)
}
}
}
// 示例 3: 条件预加载
db.Preload("Orders", "state = ?", "completed").Find(&users)
fmt.Println("\n条件预加载:")
for _, user := range users {
fmt.Printf("User: %s, Orders (completed): %d\n", user.Name, len(user.Orders))
}
// 示例 4: 自定义预加载排序
db.Preload("Orders", func(db *gorm.DB) *gorm.DB {
return db.Order("orders.id DESC")
}).Find(&users)
fmt.Println("\n自定义预加载排序:")
for _, user := range users {
fmt.Printf("User: %s, Orders: %d\n", user.Name, len(user.Orders))
}
// 示例 5: 使用 Joins
var user User
db.Joins("Profile").Joins("Orders").First(&user, 1)
fmt.Println("\n联表查询:")
fmt.Printf("User: %s, Profile: %v, Orders: %d\n", user.Name, user.Profile, len(user.Orders))
}
func initData(db *gorm.DB) {
// 清空数据
db.Exec("DELETE FROM users")
db.Exec("DELETE FROM profiles")
db.Exec("DELETE FROM orders")
db.Exec("DELETE FROM order_items")
db.Exec("DELETE FROM products")
// 创建产品
product1 := Product{Name: "Product1", Price: 10.99}
product2 := Product{Name: "Product2", Price: 20.99}
db.Create(&product1)
db.Create(&product2)
// 创建用户及关联数据
user := User{
Name: "Alice",
Profile: Profile{
Age: 30,
Bio: "Developer",
},
Orders: []Order{
{
OrderName: "Order1",
State: "completed",
OrderItems: []OrderItem{
{ProductID: product1.ID},
{ProductID: product2.ID},
},
},
{
OrderName: "Order2",
State: "pending",
OrderItems: []OrderItem{
{ProductID: product2.ID},
},
},
},
}
db.Create(&user)
}
GORM设计原理
SQL生成
GORM API方法添加Clauses至GORM Statement
1
2
3
4
5
db.Where("role <> ?", "manager").
Where("age > ?", 35).
Limit(100).
Order("age desc").
Find(&user)
GORM Finisher方法执行GORM Statement
插件扩展
ConnPool
Dialector
GORM最佳实践
1、数据序列化和SQL表达式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
//方法1:通过 gorm.Expr 使用 SQL 表达式
db.Model(User{}).Create(map[string]interface{}{
"Name": "jinzhu",
"Location": gorm.Expr("ST_PointFromText(?)", "POINT(100 100)"),
})
// INSERT INTO "user_with_points" ("name", "location") VALUES ("jinzhu", ST_PointFromText("POINT(100 100)"));
db.Model(&product).Update("price", gorm.Expr("price * ? + ?", 2, 100))
// UPDATE "products" SET "price" = price * 2 + 100 WHERE ...
//方法2:使用 GORMValuer 自定义 SQL 表达式
type Location struct {
X, Y int
}
func (loc Location) GormValue(ctx context.Context, db *gorm.DB) clause.Expr {
return gorm.Expr("ST_PointFromText(?)", fmt.Sprintf("POINT(%d %d)", loc.X, loc.Y))
}
db.Create(User{Name: "jinzhu", Location: Location{X: 100, Y: 100}})
// INSERT INTO "users" ("name", "location") VALUES ("jinzhu", ST_PointFromText("POINT(100 100)"));
db.Model(&User{ID: 1}).Updates(User{Name: "jinzhu", Location: Location{X: 100, Y: 100}})
// UPDATE "users" SET "name" = "jinzhu", "location" = ST_PointFromText("POINT(100 100)") WHERE "id" = 1;
//方法3:通过 *gorm.DB 使用子查询
subQuery := db.Model(&Company{}).Select("name").Where("companies.id = users.company_id")
db.Model(&user).Updates(map[string]interface{}{
"company_name": subQuery,
})
// UPDATE "users" SET "company_name" = (SELECT name FROM companies WHERE companies.id = users.company_id);
2、批量操作数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
//1、批量创建
var users = []User{
{Name: "jinzhu1"},
{Name: "jinzhu2"},
{Name: "jinzhu3"},
}
db.Create(&users)
db.CreateInBatches(users, 100)
for _, user := range users {
user.ID // 1, 2, 3
}
//2、批量查询
rows, err := db.Model(&User{}).Where("role = ?", "admin").Rows()
for rows.Next() {
// 方法 1: 使用 sql.Rows 的 Scan 方法
rows.Scan(&name, &age, &email) // NULL 值如何处理?
// 方法 2: 使用 GORM 提供的 ScanRows 方法
db.ScanRows(rows, &user)
// xxx (对数据进行处理)
}
//3、FindInBatches 批量查询和处理
DB.Where("role = ?", "admin").FindInBatches(&results, 100, func(tx *gorm.DB, batch int) error {
// 批量处理逻辑
return nil
})
3、分库分表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
// 使用传入数据分表
func TableOfYear(user *User, year int) func(db *gorm.DB) *gorm.DB {
return func(db *gorm.DB) *gorm.DB {
tableName := user.TableName() + strconv.Itoa(year)
return db.Table(tableName)
}
}
DB.Scopes(TableOfYear(user, 2019)).Find(&users)
// SELECT * FROM users_2019;
// 使用传入数据分库(同一个连接)
func TableOfOrg(user *User, dbName string) func(db *gorm.DB) *gorm.DB {
return func(db *gorm.DB) *gorm.DB {
tableName := dbName + "." + user.TableName()
return db.Table(tableName)
}
}
DB.Scopes(TableOfOrg(user, "org1")).Find(&users)
// SELECT * FROM org1.users;
// 使用对象信息获取表名 / interface
func TableOfUser(user *User) func(db *gorm.DB) *gorm.DB {
return func(db *gorm.DB) *gorm.DB {
year := getYearInfoFromUserID(user.ID)
return db.Table(user.TableName() + strconv.Itoa(year))
}
}
Go框架三件套
GORM
Gorm基本使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
type Product struct {
Code string
Price uint
}
//通过实现 TableName() 返回表名
func (p Product) TableName() string {
return "product"
}
func main() {
//连接数据库
db, err := gorm.Open(mysql.Open("user:pass@tcp(127.0.0.1:3306)/dbname?charset=utf8mb4&parseTime=True&loc=Local"), &gorm.Config{})
if err != nil {
panic("failed to connect database")
}
// 创建数据
db.Create(&Product{Code: "D42", Price: 100})
// 查询数据
var product Product
//First只能查询单条数据
db.First(&product, 1) // 查询主键为 1 的记录
db.First(&product, "code = ?", "D42") // 查询 code 字段为 "D42" 的记录
// Update - 更新单个字段
db.Model(&product).Update("Price", 200)
// Update - 更新多个字段
db.Model(&product).Updates(Product{Price: 200, Code: "F42"}) // 非零值字段
db.Model(&product).Updates(map[string]interface{}{"Price": 200, "Code": "F42"})
// Delete - 删除记录
db.Delete(&product)
}
Gorm的约定:
- Gorm使用ID字段作为主键
- 使用结构体的蛇形负数为表名
- 字段名的蛇形为列名
GORM数据创建
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
package main
import (
"fmt"
"gorm.io/driver/mysql"
"gorm.io/gorm"
)
type Product struct {
ID uint `gorm:"primaryKey"`
Code string `gorm:"column:code"`
//将 Price 字段映射到数据库中的 user_id 列
Price uint `gorm:"column:user_id"`
}
func main() {
// 连接数据库
db, err := gorm.Open(mysql.Open("username:password@tcp(localhost:9910)/database?charset=utf8"), &gorm.Config{})
if err != nil {
panic("failed to connect database")
}
// 创建单条记录
p := &Product{Code: "D42"}
res := db.Create(p)
fmt.Println(res.Error) // 输出错误信息(如果有)
fmt.Println(p.ID) // 输出插入后的主键
// 批量创建记录
products := []Product{
{Code: "D41"},
{Code: "D42"},
{Code: "D43"},
}
res = db.Create(products)
fmt.Println(res.Error) // 输出错误信息(如果有)
// 遍历打印插入的记录 ID
for _, p := range products {
fmt.Println(p.ID)
}
}
如果遇到唯一索引冲突的处理方式
1
2
3
// 使用 clause.OnConflict 处理数据冲突
p := &Product{Code: "D42", ID: 1}
db.Clauses(clause.OnConflict{DoNothing: true}).Create(&p)
DoNothing: true 表示如果出现冲突(例如主键或唯一键冲突),则不进行任何操作。
关于使用默认值
1
2
3
4
5
type User struct {
ID int64 // 主键字段
Name string `gorm:"default:galeone"` // 字符串字段的默认值
Age int64 `gorm:"default:18"` // 整数字段的默认值
}
gorm:”default:
GORM查询数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
db, err := gorm.Open(mysql.Open("username:password@tcp(localhost:9910)/database?charset=utf8"), &gorm.Config{})
if err != nil {
panic("failed to connect database")
}
// 获取第一条记录(按主键排序),查询不到数据则返回 ErrRecordNotFound
u := &User{}
db.First(u) // SELECT * FROM users ORDER BY id LIMIT 1;
// 查询多条数据
users := make([]User, 0)
// 条件查询
// SELECT * FROM users WHERE age > 10;
result := db.Where("age > ?", 10).Find(&users)
fmt.Println(result.RowsAffected) // 返回匹配的记录数,等同于 len(users)
fmt.Println(result.Error) // 返回错误信息
// IN 查询
// SELECT * FROM users WHERE name IN ('Jinzhu', 'Jinzhu 2');
db.Where("name IN ?", []string{"Jinzhu", "Jinzhu 2"}).Find(&users)
// LIKE 查询
// SELECT * FROM users WHERE name LIKE '%Jin%';
db.Where("name LIKE ?", "%Jin%").Find(&users)
// AND 查询
// SELECT * FROM users WHERE name = 'Jinzhu' AND age >= 22;
db.Where("name = ? AND age >= ?", "Jinzhu", 22).Find(&users)
// 使用结构体查询
// SELECT * FROM users WHERE name = 'Jinzhu' AND age = 0;
db.Where(&User{Name: "Jinzhu", Age: 0}).Find(&users)
// 使用 map 查询
// SELECT * FROM users WHERE name = 'Jinzhu' AND age = 0;
db.Where(map[string]interface{}{"Name": "Jinzhu", "Age": 0}).Find(&users)
尽量使用Find,查询不到数据不会返回错误
GORM更新数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
// 条件更新单个列
// UPDATE users SET name='hello', updated_at='2013-11-17 21:34:10' WHERE age > 18;
//.Model() 的主要作用就是 明确设置操作的模型或者表
db.Model(&User{ID: 111}).Where("age > ?", 18).Update("name", "hello")
// 更新多个列(基于 struct 更新非零值字段)
// UPDATE users SET name='hello', age=18, updated_at='2013-11-17 21:34:10' WHERE id=111;
db.Model(&User{ID: 111}).Updates(User{Name: "hello", Age: 18})
// 更新多个列(基于 map 更新指定字段)
// UPDATE users SET name='hello', age=18, actived=false, updated_at='2013-11-17 21:34:10' WHERE id=111;
db.Model(&User{ID: 111}).Updates(map[string]interface{}{"name": "hello", "age": 18, "actived": false})
// 更新特定字段
// UPDATE users SET name='hello' WHERE id=111;
db.Model(&User{ID: 111}).Select("name").Updates(map[string]interface{}{"name": "hello", "age": 18, "actived": false})
// ***使用 SQL 表达式更新
// UPDATE "products" SET "price" = price * 2 + 100, "updated_at" = '2013-11-17 21:34:10' WHERE "id" = 3;
//id:111是为了兜底
db.Model(&User{ID: 111}).Update("age", gorm.Expr("age * ? + ?", 2, 100))
注意:当通过结构体(struct)来更新记录时,Gorm 只会更新非零值字段,不会更新字段的零值(零值包括 0、”“、false 等)。
示例如下:Age 是零值(0),因此 Gorm 不会更新 Age 字段。
1
2
3
4
5
6
7
type User struct {
Name string
Age int
Email string
}
//UPDATE users SET name = 'Alice' WHERE id = 1;
db.Model(&User{ID: 1}).Updates(User{Name: "Alice", Age: 0})
如果需要更新包含零值的字段,可以通过以下两种方式实现:
-
Map
使用 map[string]interface{} 显式指定要更新的字段和值,Gorm 会忽略值是否为零值,直接更新
1 2
//UPDATE users SET name = 'Alice', age = 0 WHERE id = 1; db.Model(&User{}).Updates(map[string]interface{}{"name": "Alice", "age": 0})
-
Select
通过 Select 方法明确指定要更新的字段,即使字段值为零值,也会被更新
1 2
//UPDATE users SET name = 'Alice', age = 0 WHERE id = 1; db.Model(&User{ID: 1}).Select("Name", "Age").Updates(User{Name: "Alice", Age: 0})
GORM删除数据
物理删除
一般不推荐
1
2
3
4
5
6
7
8
9
10
11
// 删除主键为 10 的记录
db.Delete(&User{}, 10)
// 或者
db.Delete(&User{}, "10")
// 删除主键在 [1, 2, 3] 范围内的记录
db.Delete(&User{}, []int{1, 2, 3})
// 根据条件删除记录
db.Where("name LIKE ?", "%jinzhu%").Delete(&User{})
db.Delete(&User{}, "email LIKE ?", "%jinzhu%")
软删除
当调用 Delete 方法时,记录不会被从数据库中真正移除,而是将 DeletedAt 字段更新为当前时间,之后的普通查询会自动排除被软删除的记录
使用 Unscoped() 方法,可以查询或操作已被软删除的记录
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
package main
import (
"gorm.io/driver/mysql"
"gorm.io/gorm"
)
type User struct {
ID int64
Name string `gorm:"default:galeone"`
Age int64 `gorm:"default:18"`
DeletedAt gorm.DeletedAt // 用于软删除
}
func main() {
// 数据库连接
db, err := gorm.Open(mysql.Open("username:password@tcp(localhost:9910)/database?charset=utf8"), &gorm.Config{})
if err != nil {
panic("failed to connect database")
}
// 删除记录(软删除)
u := User{ID: 111}
db.Delete(&u)
// UPDATE users SET deleted_at = '当前时间' WHERE id = 111;
// 查询未删除记录
users := make([]User, 0)
db.Where("age > ?", 26).Find(&users)
// SELECT * FROM users WHERE age > 26 AND deleted_at IS NULL;
// 查询已删除记录
deletedUsers := make([]User, 0)
db.Unscoped().Where("age > ?", 26).Find(&deletedUsers)
// SELECT * FROM users WHERE age > 26;
}
GORM事务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
package main
import (
"gorm.io/driver/mysql"
"gorm.io/gorm"
)
func main() {
// 数据库连接
db, err := gorm.Open(mysql.Open("username:password@tcp(localhost:9910)/database?charset=utf8"), &gorm.Config{})
if err != nil {
panic("failed to connect database")
}
// 开始事务
//这里要使用tx,使用固化的链接
tx := db.Begin()
// **在事务中执行一些数据库操作,使用 `tx` 而不是 `db`
if err := tx.Create(&User{Name: "name"}).Error; err != nil {
tx.Rollback() // 遇到错误时回滚事务
return
}
if err := tx.Create(&User{Name: "name1"}).Error; err != nil {
tx.Rollback() // 遇到错误时回滚事务
return
}
// 提交事务
tx.Commit()
}
也提供Transaction方法用于自动提交事务,避免漏写Commit、Rollback
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
package main
import (
"gorm.io/driver/mysql"
"gorm.io/gorm"
)
func main() {
// 数据库连接
db, err := gorm.Open(mysql.Open("username:password@tcp(localhost:9910)/database?charset=utf8"), &gorm.Config{})
if err != nil {
panic("failed to connect database")
}
// 使用事务
if err = db.Transaction(func(tx *gorm.DB) error {
// 创建第一个用户
if err := tx.Create(&User{Name: "name"}).Error; err != nil {
return err // 返回错误,事务将回滚
}
// 创建第二个用户
if err := tx.Create(&User{Name: "name1"}).Error; err != nil {
return err // 返回错误,事务将回滚
}
return nil // 返回 nil 表示成功,事务将提交
}); err != nil {
// 如果事务中有错误,记录错误或处理逻辑
return
}
}
GORM Hook
在 Gorm 中,Hook 是模型生命周期中的钩子方法(Callback)。它们允许开发者在模型的特定生命周期阶段执行自定义逻辑,例如在保存、更新、删除等操作之前或之后执行一些额外操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
type User struct {
ID int64 `gorm:"primaryKey"`
Name string `gorm:"default:galeone"`
Age int64 `gorm:"default:18"`
}
type Email struct {
ID int64
Name string
Email string
}
// BeforeCreate Hook: 在创建记录前进行验证
func (u *User) BeforeCreate(tx *gorm.DB) (err error) {
if u.Age < 0 {
return errors.New("can't save invalid data")
}
return
}
// AfterCreate Hook: 在创建记录后执行操作
func (u *User) AfterCreate(tx *gorm.DB) (err error) {
return tx.Create(&Email{
ID: u.ID,
Email: u.Name + "@***.com",
}).Error
}
如果任何Hook返回错误,GORM将停止后续操作并回滚事务
GORM性能提高
- 在不需要考虑数据完整性时,可以使用SkipDefaultTransaction关闭事务
- 使用PrepareStmt,开启预编译语句缓存
1
2
3
4
5
6
7
db, err := gorm.Open(mysql.Open("username:password@tcp(localhost:9910)/database?charset=utf8"), &gorm.Config{
SkipDefaultTransaction: true, // 关闭默认事务
PrepareStmt: true, // 缓存预编译语句
})
if err != nil {
panic("failed to connect database")
}
Kitex
安装Kitex生成工具
1
2
go install github.com/cloudwego/kitex/tool/cmd/kitex@latest
go install github.com/cloudwego/thriftgo@latest
在执行上面命令前需要设置go模块代理
1
2
3
4
5
6
//使用国内的 Go 模块代理(推荐使用 goproxy.cn):
go env -w GOPROXY=https://goproxy.cn,direct
//验证代理是否已生效:
go env | grep GOPROXY
//输出结果应该类似于:
GOPROXY="https://goproxy.cn,direct"
安装之后,输入kitex –version看是否出现版本,如果是not found,那就可能是没有配置好路径,可以检查是zsh还是bash,再手动进行配置
1
2
echo 'export PATH=$PATH:$(go env GOPATH)/bin' >> ~/.zshrc
source ~/.zshrc
定义IDL
IDL是接口定义语言,是一种用于定义系统中服务接口的规范语言
在分布式系统中,不同服务之间可能由不同的语言实现,如何定义和标准化它们的接口成为一个问题,IDL主要解决下面问题
- 接口定义:统一描述服务的接口,包括方法名、参数和返回值类型
- 语言无关性:通过定义一次接口,自动生成多语言(如 Go、Java、Python 等)的代码
- 数据序列化:描述数据结构的格式,使不同语言的系统能够互相理解传输的数据
//namespace 用于定义生成代码时的目标语言命名空间
namespace go api
//描述了接口使用的数据类型
struct Request {
1: string message
}
struct Response {
1: string message
}
//定义了 RPC 服务的调用方法,包括方法名、输入参数和返回值
//这个接口定义了一个 echo 方法,接收一个 Request 类型的参数,返回一个 Response 类型
service Echo {
Response echo(1: Request req)
}
上面代码可以用.thrift结尾,接着使用thrift生成相关语言的版本,就可以进行接口调用
1
thriftgo -out . --gen go idl/echo.thrift
目录结构可以如下所示
1
2
3
4
5
6
7
8
9
10
my-project/
│
├── idl/
│ └── echo.thrift
├── api/
│ ├── echo.go (生成的代码)
├── server/
│ └── main.go (服务端代码)
├── client/
│ └── main.go (客户端代码)
使用kitex生成服务端代码
1
kitex -module example -service example echo.thrift
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
.
├── build.sh // 构建脚本
├── echo.thrift // IDL 文件
├── kitex_gen //Kitex 自动生成的目录,包含服务的核心代码(客户端、服务端和接口)
│ └── api
│ └── echo
│ ├── client.go // 客户端代码
│ ├── echo.go // 生成的服务接口和结构
│ ├── invoker.go // 客户端调用封装
│ ├── server.go // 服务端代码
│ └── k-echo.go // RPC 通信逻辑
├── handler.go // 用户在该文件里实现IDL service定义的方法
├── main.go // 程序入口
└── script
├── bootstrap.sh // 脚本工具
└── settings.py // 配置脚本
handler.go是服务逻辑的核心文件,开发者需要在此实现 IDL 中定义的服务方法
服务默认监听8888端口
handler.go就类似于spring中的controller层,负责处理客户端请求并返回结果
以在项目中自行实现 MVC 三层架构,并在 handler.go 中调用 Service 层 和 Repository 层 来实现更清晰的分层结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
package main
import (
"context"
"example/kitex_gen/api"
)
type EchoImpl struct{}
// 实现 IDL 中定义的 Echo 方法
func (e *EchoImpl) Echo(ctx context.Context, req *api.Request) (*api.Response, error) {
//填写自己的逻辑
return &api.Response{Message: "Hello, " + req.Message}, nil
}
main.go代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
package main
import (
"example/kitex_gen/api/echo"
"log"
)
func main() {
server := echo.NewServer(new(EchoImpl))
err := server.Run()
if err != nil {
log.Fatal(err)
}
}
Kitex Client发起请求
即RPC中的调用方
-
创建Client
客户端会通过 Kitex 生成的 NewClient 方法初始化,指定目标服务名和连接地址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
import ( "example/kitex_gen/api/echo" "github.com/cloudwego/kitex/client" "log" ) func main() { // 初始化 Kitex 客户端,连接到服务端 //NewClient("example"):初始化一个连接到 example 服务的客户端 c, err := echo.NewClient("example", client.WithHostPorts("0.0.0.0:8888")) if err != nil { log.Fatal(err) // 如果初始化失败,记录日志并退出 } // 发起请求的逻辑... }
-
发起请求
调用生成的客户端方法(如 Echo),将请求发送到服务端,等待并处理返回结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
import ( "context" "example/kitex_gen/api" "github.com/cloudwego/kitex/client/callopt" "log" "time" ) func sendRequest(c api.EchoClient) { // 构造请求对象 //请求构造:构造一个 Request 对象,并设置请求参数(例如 Message 字段) req := &api.Request{Message: "my request"} // 发起 RPC 请求,并设置超时时间 //调用客户端的 Echo 方法,发送请求到服务端,并接收返回的 Response。 resp, err := c.Echo( context.Background(), req, //超时设置:使用 callopt.WithRPCTimeout 设置 RPC 调用的最大超时时间为 3 秒 callopt.WithRPCTimeout(3*time.Second), // 设置 RPC 超时时间为 3 秒 ) if err != nil { log.Fatal(err) // 处理错误 } // 输出服务端响应 log.Println("Response:", resp.Message) }
Kitex服务注册与发现
将server注册到注册中心中,client从注册中心里获取数据,实现一系列负载均衡算法
server服务注册
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
package main
import (
"context"
"log"
"example/kitex_gen/api"
"github.com/cloudwego/kitex/server"
"github.com/cloudwego/kitex/pkg/rpcinfo"
"github.com/cloudwego/kitex/registry/etcd"
)
type HelloImpl struct{}
// 实现 Echo 方法
func (h *HelloImpl) Echo(ctx context.Context, req *api.Request) (*api.Response, error) {
resp := &api.Response{
Message: req.Message, // 将请求消息直接返回
}
return resp, nil
}
func main() {
// 创建 Etcd 注册中心
//指定etcd集群的地址
r, err := etcd.NewEtcdRegistry([]string{"127.0.0.1:2379"})
if err != nil {
log.Fatal(err) // 注册中心初始化失败
}
// 初始化服务
server := api.NewServer(
//将前面的实现注入进来,因为用的interface解耦的,所以直接注入
new(HelloImpl),
server.WithRegistry(r), // 使用注册中心
server.WithServerBasicInfo(&rpcinfo.EndpointBasicInfo{
ServiceName: "Hello", // 服务名称
}),
)
// 启动服务
err = server.Run()
if err != nil {
log.Fatal(err) // 服务运行失败
}
}
client服务发现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
package main
import (
"context"
"log"
"time"
"example/kitex_gen/api"
"github.com/cloudwego/kitex/client"
"github.com/cloudwego/kitex/client/callopt"
"github.com/cloudwego/kitex/registry/etcd"
)
func main() {
// 初始化 Etcd 解析器,用于服务发现
r, err := etcd.NewEtcdResolver([]string{"127.0.0.1:2379"})
if err != nil {
log.Fatal(err) // 如果解析器初始化失败,记录日志并退出
}
// 创建客户端,绑定服务名和解析器
client := api.MustNewClient("Hello", client.WithResolver(r))
// 持续发送请求
for {
// 设置超时上下文
ctx, cancel := context.WithTimeout(context.Background(), 3*time.Second)
defer cancel()
// 调用远程服务
resp, err := client.Echo(ctx, &api.Request{Message: "Hello"})
if err != nil {
log.Fatal(err) // 如果调用失败,记录错误并退出
}
// 打印响应结果
log.Println(resp)
// 每隔 1 秒发送一次请求
time.Sleep(time.Second)
}
}
Hertz
Hertz 提供了运行 HTTP 服务的能力, 定义路由规则,处理不同 URL 路径的请求(如 /ping),提供封装(如 app.RequestContext)来处理请求数据、生成响应(如返回 JSON)
Hertz 提供了一个轻量级的框架,允许开发者快速创建和启动 HTTP 服务,并将路由(业务逻辑)绑定到特定路径。
可以理解为主要是实现 HTTP 请求的路由映射,并根据路由规则调用对应的处理方法
hertz相比于gin是有两个上下文,Context主要用来接收数据,RequestContext主要用于封装 HTTP 请求和响应的细节
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
package main
import (
"context"
"github.com/cloudwego/hertz/pkg/app"
"github.com/cloudwego/hertz/pkg/app/server"
"github.com/cloudwego/hertz/pkg/common/utils"
"github.com/cloudwego/hertz/pkg/protocol/consts"
)
func main() {
//server.Default() 用于创建一个 Hertz 服务器实例
h := server.Default(server.WithHostPorts("127.0.0.1:8080"))
//注册一个 HTTP GET 请求的路由,路径为 /ping
//处理函数接收两个参数:
//c:上下文 context.Context,通常用于处理请求生命周期的上下文控制。
//ctx:app.RequestContext,封装了 HTTP 请求和响应相关的功能。
h.GET("/ping", func(c context.Context, ctx *app.RequestContext) {
ctx.JSON(consts.StatusOK, utils.H{"ping": "pong"})
})
//h.Spin() 是 Hertz 的方法,用于启动 HTTP 服务器并阻塞当前线程,直到服务器关闭。
h.Spin()
}
Hertz路由
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
func RegisterRoute(h *server.Hertz) {
h.GET("/get", func(ctx context.Context, c *app.RequestContext) {
c.String(consts.StatusOK, "get")
})
h.POST("/post", func(ctx context.Context, c *app.RequestContext) {
c.String(consts.StatusOK, "post")
})
h.PUT("/put", func(ctx context.Context, c *app.RequestContext) {
c.String(consts.StatusOK, "put")
})
h.DELETE("/delete", func(ctx context.Context, c *app.RequestContext) {
c.String(consts.StatusOK, "delete")
})
h.PATCH("/patch", func(ctx context.Context, c *app.RequestContext) {
c.String(consts.StatusOK, "patch")
})
h.HEAD("/head", func(ctx context.Context, c *app.RequestContext) {
c.String(consts.StatusOK, "head")
})
h.OPTIONS("/options", func(ctx context.Context, c *app.RequestContext) {
c.String(consts.StatusOK, "options")
})
}
路由分组
使用 h.Group(relativePath: “/v1”) 和 h.Group(relativePath: “/v2”) 创建了两个路由分组。
分组的路径分别是 /v1 和 /v2,这些路径会作为组内路由的前缀
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// Simple group: v1
v1 := h.Group(relativePath: "/v1") {
// loginEndpoint is a handler func
v1.POST(relativePath: "/login", loginEndpoint)
v1.POST(relativePath: "/submit", submitEndpoint)
v1.POST(relativePath: "/streaming_read", readEndpoint)
}
// Simple group: v2
v2 := h.Group(relativePath: "/v2") {
v2.POST(relativePath: "/login", loginEndpoint)
v2.POST(relativePath: "/submit", submitEndpoint)
v2.POST(relativePath: "/streaming_read", readEndpoint)
}
参数路由
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// This handler will match: "/hertz/version", but will not match: "/hertz/" or "/hertz"
h.GET("/hertz/:version", func(ctx context.Context, c *app.RequestContext) {
version := c.Param("version")
c.String(consts.StatusOK, "Hello %s", version)
})
// However, this one will match "/hertz/v1/" and "/hertz/v2/send"
h.GET("/hertz/:version/*action", func(ctx context.Context, c *app.RequestContext) {
version := c.Param("version")
action := c.Param("action")
message := version + " is " + action
c.String(consts.StatusOK, message)
})
// For each matched request Context will hold the route definition
h.POST("/hertz/:version/*action", func(ctx context.Context, c *app.RequestContext) {
// c.FullPath() == "/hertz/:version/*action" // true
c.String(consts.StatusOK, c.FullPath())
})
路由优先级:静态路由》命令路由〉通配路由
Hertz参数绑定
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
type Args struct {
Query string `query:"query"`
QuerySlice []string `query:"q"`
Path string `path:"path"`
Header string `header:"Header"`
Form string `form:"form"`
Json string `json:"json"`
Vd int `query:"vd" vd:"$=0|$=1"`
}
func main() {
h := server.Default(server.WithHostPorts("127.0.0.1:8080"))
h.POST(":path/bind", func(ctx context.Context, c *app.RequestContext) {
var arg Args
//这里是传递指针
err := c.BindAndValidate(&arg)
if err != nil {
panic(err)
}
fmt.Println(arg)
})
h.Spin()
}
BindAndValidate 方法用于自动将 HTTP 请求中的数据绑定到结构体字段中
Hertz中间件
下面是一个服务端中间件
中间件是一个 app.HandlerFunc 类型的函数,用于在处理请求前后执行一些通用逻辑
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
func MyMiddleware() app.HandlerFunc {
return func(ctx context.Context, c *app.RequestContext) {
// pre-handle
fmt.Println("pre-handle")
c.Next(ctx) // call the next middleware (handler)
// post-handle
fmt.Println("post-handle")
}
}
func main() {
h := server.Default(server.WithHostPorts("127.0.0.1:8080"))
h.Use(MyMiddleware())
h.GET("/middleware", func(ctx context.Context, c *app.RequestContext) {
c.String(consts.StatusOK, "Hello hertz!")
})
h.Spin()
}
Hertz Client
Hertz 的 HTTP Client 提供了简洁的 API,用于高效地发送 HTTP 请求。通过 Get 和 Post 等方法,可以轻松处理常见的 HTTP 操作,并通过上下文和参数灵活配置请求
1
2
3
4
5
6
7
8
9
10
11
12
13
14
c, err := client.NewClient()
if err != nil {
return
}
// send http get request
status, body, _ := c.Get(context.Background(), nil, "http://www.example.com")
fmt.Printf("status=%v body=%v\n", status, string(body))
// send http post request
var postArgs protocol.Args
postArgs.Set("arg", "a") // Set post args
status, body, _ = c.Post(context.Background(), nil, "http://www.example.com", &postArgs)
fmt.Printf("status=%v body=%v\n", status, string(body))
Hertz代码生成工具
Hertz提供了代码生成工具Hz,通过定义IDL文件即可生成对应的基础代码
namespace go hello.example
struct HelloReq {
1: string Name (api.query="name");
}
struct HelloResp {
1: string RespBody;
}
service HelloService {
HelloResp HelloMethod(1: HelloReq request) (api.get="/hello");
}
目录结构如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
biz/
handler/
hello/
example/
hello_service.go
ping.go
model/
hello/
example/
hello.go
router/
hello/
example/
hello.go
middleware.go
register.go
main.go
router.go
router_gen.go
生成文件
对 /hello 路由的处理逻辑
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
import (
"context"
"github.com/cloudwego/hertz/pkg/app"
"hertz-examples/hz/thrift/biz/model/hello/example"
)
// HelloMethod .
// @router /hello [GET]
func HelloMethod(ctx context.Context, c *app.RequestContext) {
var err error
var req example.HelloReq
err = c.BindAndValidate(&req)
if err != nil {
c.String(400, err.Error())
return
}
resp := new(example.HelloResp)
c.JSON(200, resp)
}
实战案例介绍
笔记项目,做一个具备一定业务的后端API项目
RPC框架分层设计
基本概念
RPC需要解决的问题:
- 函数映射
- 数据转化成字节流(参数传递)
- 网络传输
概念模型
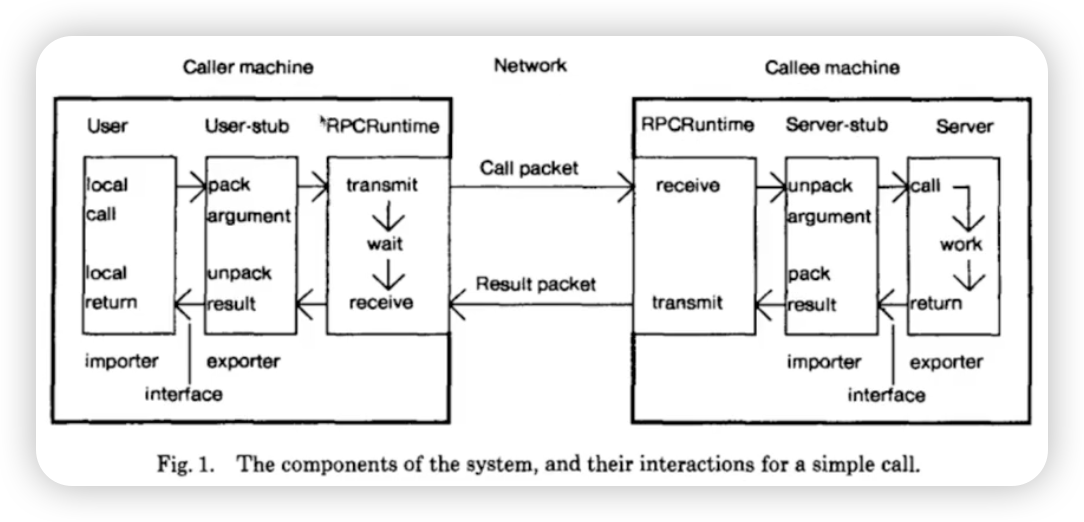
一次RPC的完整过程
IDL文件
通过一种中立的方式来描述接口,使得不同平台上运行的对象和用不同语言编写的程序可以相互通信
生成代码
通过编译器工具把IDL文件转化为语言对应的静态库
编解码
从内存中表示到字节序列的转化为编码,反之为解码,也可以称为序列化和反序列化
通信协议
规范了数据在网络中的传输内容和格式,除必须的请求和响应数据外,通常还会包含额外的元数据
网络传输
通常机遇成熟的网络库走TCP/UDP传输
RPC框架
采用分层设计的结构
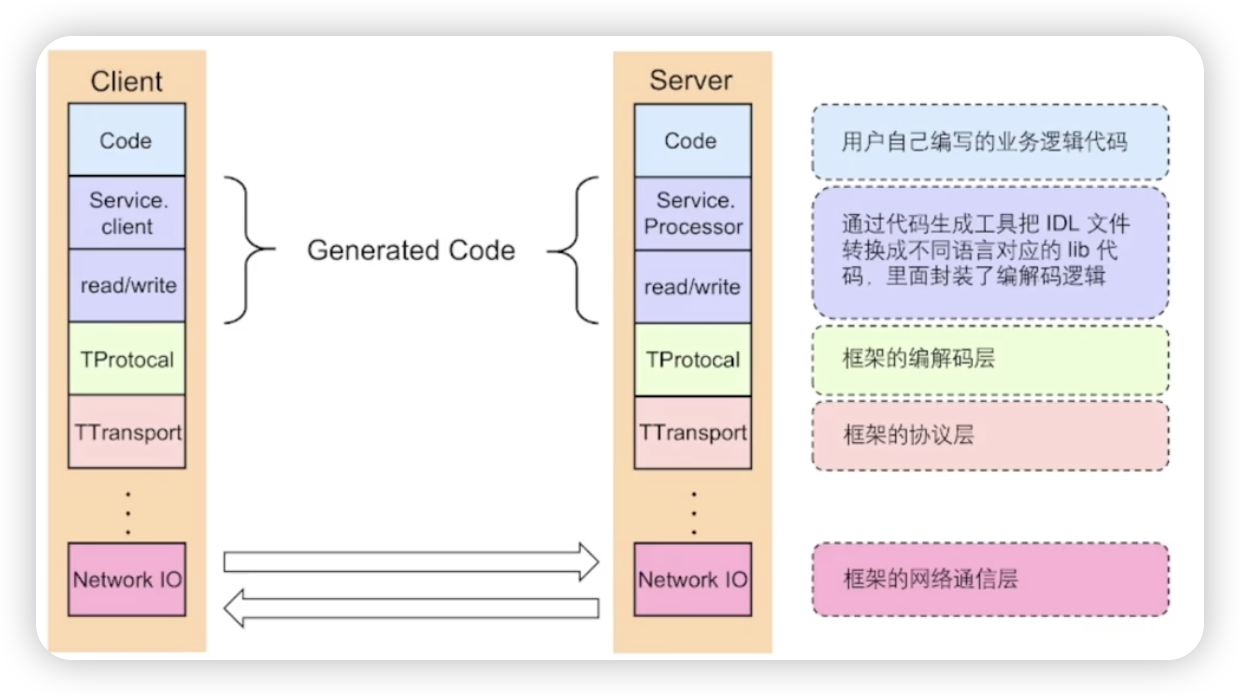
编解码层
客户端和服务端使用同一份IDL文件,生成不同语言的版本
TLV编码
通过 Type(类型)、Length(长度)和 Value(值)的组合来描述每一段数据
1. Type(类型):
• 表示数据的类型,通常以固定的编码值表示。
• 比如:一个协议中可能规定 0x01 表示字符串,0x02 表示整数,0x03 表示布尔值。
• 通常用 1 字节或更多字节表示。
2. Length(长度):
• 表示值(Value)的长度,通常是字节单位。
• 例如:字符串 “Hello” 的长度是 5(因为它包含 5 个字符,每个字符 1 字节)。
• 长度字段可以是固定长度(如 1 字节或 2 字节)或动态长度(用特定规则决定长度字段本身的大小)。
3. Value(值):
• 实际的数据内容。
• 数据的值类型由 Type 决定,长度由 Length 指定。
协议层
协议层相关参数
- LENGTH:数据包大小,不包含自身
- HEADER MAGIC:标识版本信息,协议解析时候快速校验
- SEQUENCE NUMBER:表示数据包的 seqID,可用于多路复用,单连接内递增
- HEADER SIZE:头部长度,从第14个字节开始计算一直到 PAYLOAD前
- PROTOCOL ID:编解码方式,有 Binary 和Compact 两种
- TRANSFORM ID:压缩方式,如 zlib 和 snappy
- INFO ID: 传递一些定制的 meta 信息
- PAYLOAD: 消息体
网络通信层
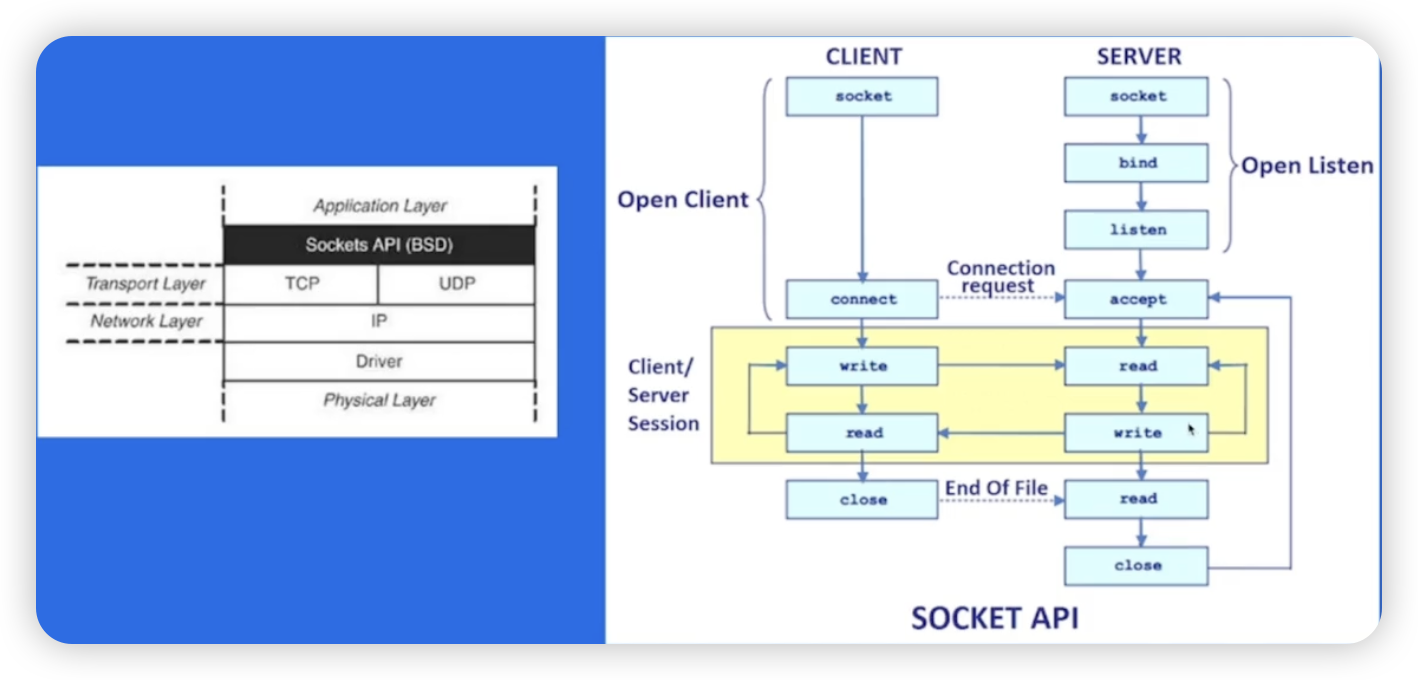
Redis
redis使用案例
首先需要打开redis
1
2
3
4
//打开redis
redis-server
//测试是否联通
redis-cli ping
1.连续签到
在go项目中一个会创建一个redis_client.go的文件,用于初始化连接redis
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
package example
import (
"github.com/go-redis/redis/v9"
)
var RedisClient *redis.Client
func init() {
rdb := redis.NewClient(&redis.Options{
Addr: "127.0.0.1:6379",
})
RedisClient = rdb
}
在go中init方法会在包被首次导入时自动执行,而不需要显式调用,所以,只要项目启动了,并且加载了包含 init 函数的包,Redis 客户端 RedisClient 就会自动初始化
接着就可以编写连续签到的逻辑,然后在main函数中调用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
package example
import (
"context"
"fmt"
"strconv"
"time"
)
var ctx = context.Background()
const continuesCheckKey = "cc_uid_%d"
// Ex01 连续签到天数
func Ex01(ctx context.Context, params []string) {
if userID, err := strconv.ParseInt(params[0], 10, 64); err == nil {
addContinuesDays(ctx, userID)
} else {
fmt.Printf("参数错误, params=%v, error: %v\n", params, err)
}
}
// addContinuesDays 为用户签到续期
func addContinuesDays(ctx context.Context, userID int64) {
key := fmt.Sprintf(continuesCheckKey, userID)
// 1. 连续签到数+1
err := RedisClient.Incr(ctx, key).Err()
if err != nil {
fmt.Errorf("用户[%d]连续签到失败", userID)
} else {
expAt := beginningOfDay().Add(48 * time.Hour)
// 2. 设置签到记录在后天的0点到期
if err := RedisClient.ExpireAt(ctx, key, expAt).Err(); err != nil {
panic(err)
} else {
// 3. 打印用户续签后的连续签到天数
day, err := getUserCheckInDays(ctx, userID)
if err != nil {
panic(err)
}
fmt.Printf("用户[%d]连续签到:%d(天), 过期时间:%s", userID, day, expAt.Format("2006-01-02 15:04:05"))
}
}
}
// getUserCheckInDays 获取用户连续签到天数
func getUserCheckInDays(ctx context.Context, userID int64) (int64, error) {
key := fmt.Sprintf(continuesCheckKey, userID)
days, err := RedisClient.Get(ctx, key).Result()
if err != nil {
return 0, err
}
if daysInt, err := strconv.ParseInt(days, 10, 64); err != nil {
panic(err)
} else {
return daysInt, nil
}
}
// beginningOfDay 获取今天0点时间
func beginningOfDay() time.Time {
now := time.Now()
y, m, d := now.Date()
return time.Date(y, m, d, 0, 0, 0, 0, time.Local)
}
2.消息通知
用list作为消息队列
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
package example
import (
"context"
"fmt"
"strings"
"time"
"gitee.com/wedone/redis_course/example/common"
)
const ex04ListenList = "ex04_list_0" // lpush ex04_list_0 AA BB
// Ex04Params Ex04的自定义函数
type Ex04Params struct {
}
func Ex04(ctx context.Context) {
eventLogger := &common.ConcurrentEventLogger{}
// new一个并发执行器
// routineNums是消费端的数量,多消费的场景,可以使用ex04ConsumerPop,使用ex04ConsumerRange存在消息重复消费的问题。
cInst := common.NewConcurrentRoutine(1, eventLogger)
// 并发执行用户自定义函数work
cInst.Run(ctx, Ex04Params{}, ex04ConsumerPop)
// 按日志时间正序打印日志
eventLogger.PrintLogs()
}
// ex04ConsumerPop 使用rpop逐条消费队列中的信息,数据从队列中移除
// 生成端使用:lpush ex04_list_0 AA BB
func ex04ConsumerPop(ctx context.Context, cInstParam common.CInstParams) {
routine := cInstParam.Routine
for {
items, err := RedisClient.BRPop(ctx, 0, ex04ListenList).Result()
if err != nil {
panic(err)
}
fmt.Println(common.LogFormat(routine, "读取文章[%s]标题、正文,发送到ES更新索引", items[1]))
// 将文章内容推送到ES
time.Sleep(1 * time.Second)
}
}
// ex04ConsumerRange 使用lrange批量消费队列中的数据,数据保留在队列中
// 生成端使用:rpush ex04_list_0 AA BB
// 消费端:
// 方法1 lrange ex04_list_0 -3 -1 // 从FIFO队尾中一次消费3条信息
// 方法2 rpop ex04_list_0 3
func ex04ConsumerRange(ctx context.Context, cInstParam common.CInstParams) {
routine := cInstParam.Routine
consumeBatchSize := int64(3) // 一次取N个消息
for {
// 从index(-consumeBatchSize)开始取,直到最后一个元素index(-1)
items, err := RedisClient.LRange(ctx, ex04ListenList, -consumeBatchSize, -1).Result()
if err != nil {
panic(err)
}
if len(items) > 0 {
fmt.Println(common.LogFormat(routine, "收到信息:%s", strings.Join(items, "->")))
// 清除已消费的队列
// 方法1 使用LTrim
// 保留从index(0)开始到index(-(consumeBatchSize + 1))的部分,即为未消费的部分
// RedisClient.LTrim(ctx, ex04ListenList, 0, -(consumeBatchSize + 1))
// 方法2 使用RPop
RedisClient.RPopCount(ctx, ex04ListenList, int(consumeBatchSize))
}
time.Sleep(3 * time.Second)
}
}
3.计数
使用hash结构进行存储
rehash:将ht[0]的数据全部迁移到ht[1]中,数据量小的场景下,拷贝是比较快的,但如果是数据量比较大的情况就会阻塞,所以引入了渐进式rehash
渐进式rehash:每次用户访问时都会迁移少量数据,将整个迁移过程,平摊到所有的访问用户请求的过程中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
package example
import (
"context"
"fmt"
"os"
"strconv"
"github.com/go-redis/redis/v9"
)
const Ex05UserCountKey = "ex05_user_count"
// Ex05 hash数据结果的运用(参考掘金应用)
// go run main.go init 初始化用户计数值
// go run main.go get 1556564194374926 // 打印用户(1556564194374926)的所有计数值
// go run main.go incr_like 1556564194374926 // 点赞数+1
// go run main.go incr_collect 1556564194374926 // 点赞数+1
// go run main.go decr_like 1556564194374926 // 点赞数-1
// go run main.go decr_collect 1556564194374926 // 点赞数-1
func Ex05(ctx context.Context, args []string) {
if len(args) == 0 {
fmt.Printf("args can NOT be empty\n")
os.Exit(1)
}
arg1 := args[0]
switch arg1 {
case "init":
Ex06InitUserCounter(ctx)
case "get":
userID, err := strconv.ParseInt(args[1], 10, 64)
if err != nil {
panic(err)
}
GetUserCounter(ctx, userID)
case "incr_like":
userID, err := strconv.ParseInt(args[1], 10, 64)
if err != nil {
panic(err)
}
IncrByUserLike(ctx, userID)
case "incr_collect":
userID, err := strconv.ParseInt(args[1], 10, 64)
if err != nil {
panic(err)
}
IncrByUserCollect(ctx, userID)
case "decr_like":
userID, err := strconv.ParseInt(args[1], 10, 64)
if err != nil {
panic(err)
}
DecrByUserLike(ctx, userID)
case "decr_collect":
userID, err := strconv.ParseInt(args[1], 10, 64)
if err != nil {
panic(err)
}
DecrByUserCollect(ctx, userID)
}
}
func Ex06InitUserCounter(ctx context.Context) {
pipe := RedisClient.Pipeline()
userCounters := []map[string]interface{}{
{"user_id": "1556564194374926", "got_digg_count": 10693, "got_view_count": 2238438, "followee_count": 176, "follower_count": 9895, "follow_collect_set_count": 0, "subscribe_tag_count": 95},
{"user_id": "1111", "got_digg_count": 19, "got_view_count": 4},
{"user_id": "2222", "got_digg_count": 1238, "follower_count": 379},
}
for _, counter := range userCounters {
uid, err := strconv.ParseInt(counter["user_id"].(string), 10, 64)
key := GetUserCounterKey(uid)
rw, err := pipe.Del(ctx, key).Result()
if err != nil {
fmt.Printf("del %s, rw=%d\n", key, rw)
}
_, err = pipe.HMSet(ctx, key, counter).Result()
if err != nil {
panic(err)
}
fmt.Printf("设置 uid=%d, key=%s\n", uid, key)
}
// 批量执行上面for循环设置好的hmset命令
_, err := pipe.Exec(ctx)
if err != nil { // 报错后进行一次额外尝试
_, err = pipe.Exec(ctx)
if err != nil {
panic(err)
}
}
}
func GetUserCounterKey(userID int64) string {
return fmt.Sprintf("%s_%d", Ex05UserCountKey, userID)
}
func GetUserCounter(ctx context.Context, userID int64) {
pipe := RedisClient.Pipeline()
GetUserCounterKey(userID)
pipe.HGetAll(ctx, GetUserCounterKey(userID))
cmders, err := pipe.Exec(ctx)
if err != nil {
panic(err)
}
for _, cmder := range cmders {
counterMap, err := cmder.(*redis.MapStringStringCmd).Result()
if err != nil {
panic(err)
}
for field, value := range counterMap {
fmt.Printf("%s: %s\n", field, value)
}
}
}
// IncrByUserLike 点赞数+1
func IncrByUserLike(ctx context.Context, userID int64) {
incrByUserField(ctx, userID, "got_digg_count")
}
// IncrByUserCollect 收藏数+1
func IncrByUserCollect(ctx context.Context, userID int64) {
incrByUserField(ctx, userID, "follow_collect_set_count")
}
// DecrByUserLike 点赞数-1
func DecrByUserLike(ctx context.Context, userID int64) {
decrByUserField(ctx, userID, "got_digg_count")
}
// DecrByUserCollect 收藏数-1
func DecrByUserCollect(ctx context.Context, userID int64) {
decrByUserField(ctx, userID, "follow_collect_set_count")
}
func incrByUserField(ctx context.Context, userID int64, field string) {
change(ctx, userID, field, 1)
}
func decrByUserField(ctx context.Context, userID int64, field string) {
change(ctx, userID, field, -1)
}
func change(ctx context.Context, userID int64, field string, incr int64) {
redisKey := GetUserCounterKey(userID)
before, err := RedisClient.HGet(ctx, redisKey, field).Result()
if err != nil {
panic(err)
}
beforeInt, err := strconv.ParseInt(before, 10, 64)
if err != nil {
panic(err)
}
if beforeInt+incr < 0 {
fmt.Printf("禁止变更计数,计数变更后小于0. %d + (%d) = %d\n", beforeInt, incr, beforeInt+incr)
return
}
fmt.Printf("user_id: %d\n更新前\n%s = %s\n--------\n", userID, field, before)
_, err = RedisClient.HIncrBy(ctx, redisKey, field, incr).Result()
if err != nil {
panic(err)
}
// fmt.Printf("更新记录[%d]:%d\n", userID, num)
count, err := RedisClient.HGet(ctx, redisKey, field).Result()
if err != nil {
panic(err)
}
fmt.Printf("user_id: %d\n更新后\n%s = %s\n--------\n", userID, field, count)
}
4.排行榜
使用zset结构进行排序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
package example
import (
"context"
"fmt"
"strconv"
"time"
"github.com/go-redis/redis/v9"
)
// 0(最高位不用)|
// __000000 00000000 00000000(22bit表示分值),最大有效值 2,097,151
// 0 00000000 00000000 00000000 00000000 00000000(41bit表示毫秒级时间戳,毫秒级时间戳占用41bit)
const Ex062RankKey = "ex062_rank_zset"
const MaxTime = (1 << 41) - 1 // 1 11111111 11111111 11111111 11111111 11111111
// GetScoreWithTime 获取携带时间信息的分值
func GetScoreWithTime(ctx context.Context, score int64) int64 {
scoreWithTime := score << 41
now := time.Now().UnixMilli()
scoreWithTime |= MaxTime - now // 写入时间约晚,(MaxTime - now)越小,使得后写入的数据低位越小。相同分值情况下,后写入的排序就越靠后
return scoreWithTime
}
// GetScoreWithoutTime 去除数值中的时间信息
func GetScoreWithoutTime(ctx context.Context, scoreWithTime int64) int64 {
score := scoreWithTime >> 41
return score
}
// Ex06_2 排行榜,支持同分值按写入时间序排序
// go run main.go init // 初始化积分
// go run main.go rev_order // 输出完整榜单
// go run main.go order_page // 逆序分页输出
// go run main.go order_page 1 // 逆序分页输出,offset=1
// go run main.go add_user_score judy 23
// zadd ex062_rank_zset 15 andy
// zincrby ex062_rank_zset -9 andy // andy 扣9分,排名掉到最后一名
func Ex06_2(ctx context.Context, args []string) {
arg1 := args[0]
switch arg1 {
case "init":
Ex062InitUserScore(ctx)
case "rev_order":
GetRevOrderAllList062(ctx, 0, -1)
case "order_page":
pageSize := int64(2)
offset := int64(0)
var err error
if len(args[1]) > 0 {
offset, err = strconv.ParseInt(args[1], 10, 64)
if err != nil {
panic(err)
}
}
GetOrderListByPage062(ctx, offset, pageSize)
case "get_rank":
GetUserRankByName062(ctx, args[1])
case "get_score":
GetUserScoreByName062(ctx, args[1])
case "add_user_score":
score, err := strconv.ParseInt(args[2], 10, 64)
if err != nil {
panic(err)
}
AddUserScore062(ctx, args[1], score)
}
return
}
// Ex062InitUserScore 初始化榜单
func Ex062InitUserScore(ctx context.Context) {
initList := []redis.Z{
{Member: "user1", Score: float64(GetScoreWithTime(ctx, 10))},
{Member: "user2", Score: float64(GetScoreWithTime(ctx, 232))},
{Member: "user3", Score: float64(GetScoreWithTime(ctx, 129))},
}
// 清空榜单
if err := RedisClient.Del(ctx, Ex062RankKey).Err(); err != nil {
panic(err)
}
nums, err := RedisClient.ZAdd(ctx, Ex062RankKey, initList...).Result()
if err != nil {
panic(err)
}
fmt.Printf("初始化榜单Item数量:%d\n", nums)
time.Sleep(2 * time.Second)
lastItem := []redis.Z{
{Member: "user4", Score: float64(GetScoreWithTime(ctx, 232))},
}
nums, err = RedisClient.ZAdd(ctx, Ex062RankKey, lastItem...).Result()
if err != nil {
panic(err)
}
fmt.Printf("初始化榜单Item数量:%d\n", nums)
}
// 榜单逆序输出
// ZRANGE ex06_rank_zset +inf -inf BYSCORE rev WITHSCORES
// 正序输出
// ZRANGE ex06_rank_zset 0 -1 WITHSCORES
func GetRevOrderAllList062(ctx context.Context, limit, offset int64) {
resList, err := RedisClient.ZRevRangeWithScores(ctx, Ex062RankKey, 0, -1).Result()
if err != nil {
panic(err)
}
fmt.Printf("\n榜单:\n")
for i, z := range resList {
scoreWithoutTime := GetScoreWithoutTime(ctx, int64(z.Score))
fmt.Printf("第%d名 %s\t%d\n", i+1, z.Member, scoreWithoutTime)
}
}
func GetOrderListByPage062(ctx context.Context, offset, pageSize int64) {
// zrange ex06_rank_zset 300 0 byscore rev limit 1 2 withscores // 取300分到0分之间的排名
// zrange ex06_rank_zset -inf +inf byscore withscores 正序输出
// ZRANGE ex06_rank_zset +inf -inf BYSCORE REV WITHSCORES 逆序输出所有排名
// zrange ex06_rank_zset +inf -inf byscore rev limit 0 2 withscores 逆序分页输出排名
zRangeArgs := redis.ZRangeArgs{
Key: Ex062RankKey,
ByScore: true,
Rev: true,
Start: "-inf",
Stop: "+inf",
Offset: offset,
Count: pageSize,
}
resList, err := RedisClient.ZRangeArgsWithScores(ctx, zRangeArgs).Result()
if err != nil {
panic(err)
}
fmt.Printf("\n榜单(offest=%d, pageSize=%d):\n", offset, pageSize)
offNum := int(pageSize * offset)
for i, z := range resList {
rank := i + 1 + offNum
scoreWithoutTime := GetScoreWithoutTime(ctx, int64(z.Score))
fmt.Printf("第%d名 %s\t%d\n", rank, z.Member, scoreWithoutTime)
}
fmt.Println()
}
// GetUserRankByName062 获取用户排名
func GetUserRankByName062(ctx context.Context, name string) {
rank, err := RedisClient.ZRevRank(ctx, Ex062RankKey, name).Result()
if err != nil {
fmt.Errorf("error getting name=%s, err=%v", name, err)
return
}
fmt.Printf("name=%s, 排名=%d\n", name, rank+1)
}
// GetUserScoreByName062 获取用户分值
func GetUserScoreByName062(ctx context.Context, name string) {
// fmt.Println(strconv.FormatInt(1<<41, 2))
// fmt.Println(strconv.FormatInt(MaxTime, 2))
score, err := RedisClient.ZScore(ctx, Ex062RankKey, name).Result()
if err != nil {
fmt.Errorf("error getting name=%s, err=%v", name, err)
return
}
scoreWithoutTime := GetScoreWithoutTime(ctx, int64(score))
fmt.Printf("name=%s, 分数=%d\n", name, scoreWithoutTime)
}
// AddUserScore062 增加一个排名用户
func AddUserScore062(ctx context.Context, name string, score int64) {
scoreWithT := GetScoreWithTime(ctx, score)
z := redis.Z{
Score: float64(scoreWithT),
Member: name,
}
num, err := RedisClient.ZAdd(ctx, Ex062RankKey, z).Result()
if err != nil {
panic(err)
}
fmt.Printf("set[%d] name=%s, score=%d, scoreWithTime=%d\n", num, name, score, scoreWithT)
}
5.限流
使用string的数据结构,作为一个限流的计数,判断时候达到限流条件来看是否进行放行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
package example
import (
"context"
"fmt"
"sync/atomic"
"time"
"github.com/go-redis/redis/v9"
"gitee.com/wedone/redis_course/example/common"
)
type Ex03Params struct {
}
var ex03LimitKeyPrefix = "comment_freq_limit"
var accessQueryNum = int32(0)
const ex03MaxQPS = 10 // 限流次数
// ex03LimitKey 返回key格式为:comment_freq_limit-1669524458 // 用来记录这1秒内的请求数量
func ex03LimitKey(currentTimeStamp time.Time) string {
return fmt.Sprintf("%s-%d", ex03LimitKeyPrefix, currentTimeStamp.Unix())
}
// Ex03 简单限流
func Ex03(ctx context.Context) {
eventLogger := &common.ConcurrentEventLogger{}
// new一个并发执行器
cInst := common.NewConcurrentRoutine(500, eventLogger)
// 并发执行用户自定义函数work
cInst.Run(ctx, Ex03Params{}, ex03Work)
// 按日志时间正序打印日志
eventLogger.PrintLogs()
fmt.Printf("放行总数:%d\n", accessQueryNum)
fmt.Printf("\n------\n下一秒请求\n------\n")
accessQueryNum = 0
time.Sleep(1 * time.Second)
// new一个并发执行器
cInst = common.NewConcurrentRoutine(10, eventLogger)
// 并发执行用户自定义函数work
cInst.Run(ctx, Ex03Params{}, ex03Work)
// 按日志时间正序打印日志
eventLogger.PrintLogs()
fmt.Printf("放行总数:%d\n", accessQueryNum)
}
func ex03Work(ctx context.Context, cInstParam common.CInstParams) {
routine := cInstParam.Routine
eventLogger := cInstParam.ConcurrentEventLogger
key := ex03LimitKey(time.Now())
currentQPS, err := RedisClient.Incr(ctx, key).Result()
if err != nil || err == redis.Nil {
err = RedisClient.Incr(ctx, ex03LimitKey(time.Now())).Err()
if err != nil {
panic(err)
}
}
if currentQPS > ex03MaxQPS {
// 超过流量限制,请求被限制
eventLogger.Append(common.EventLog{
EventTime: time.Now(),
Log: common.LogFormat(routine, "被限流[%d]", currentQPS),
})
// sleep 模拟业务逻辑耗时
time.Sleep(50 * time.Millisecond)
err = RedisClient.Decr(ctx, key).Err()
if err != nil {
panic(err)
}
} else {
// 流量放行
eventLogger.Append(common.EventLog{
EventTime: time.Now(),
Log: common.LogFormat(routine, "流量放行[%d]", currentQPS),
})
atomic.AddInt32(&accessQueryNum, 1)
time.Sleep(20 * time.Millisecond)
}
}
6.分布式锁
使用redis的setnx实现加锁
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
package example
// setnx 分布式锁
import (
"context"
"fmt"
"strconv"
"time"
"gitee.com/wedone/redis_course/example/common"
)
const resourceKey = "syncKey" // 分布式锁的key
const exp = 800 * time.Millisecond // 锁的过期时间,避免死锁
// EventLog 搜集日志的结构
type EventLog struct {
eventTime time.Time
log string
}
// Ex02Params Ex02的自定义函数
type Ex02Params struct {
}
// Ex02 只是体验SetNX的特性,不是高可用的分布式锁实现
// 该实现存在的问题:
// (1) 业务超时解锁,导致并发问题。业务执行时间超过锁超时时间
// (2) redis主备切换临界点问题。主备切换后,A持有的锁还未同步到新的主节点时,B可在新主节点获取锁,导致并发问题。
// (3) redis集群脑裂,导致出现多个主节点
func Ex02(ctx context.Context) {
eventLogger := &common.ConcurrentEventLogger{}
// new一个并发执行器
cInst := common.NewConcurrentRoutine(10, eventLogger)
// 并发执行用户自定义函数work
cInst.Run(ctx, Ex02Params{}, ex02Work)
// 按日志时间正序打印日志
eventLogger.PrintLogs()
}
func ex02Work(ctx context.Context, cInstParam common.CInstParams) {
routine := cInstParam.Routine
eventLogger := cInstParam.ConcurrentEventLogger
defer ex02ReleaseLock(ctx, routine, eventLogger)
for {
// 1. 尝试获取锁
// exp - 锁过期设置,避免异常死锁
acquired, err := RedisClient.SetNX(ctx, resourceKey, routine, exp).Result() // 尝试获取锁
if err != nil {
eventLogger.Append(common.EventLog{
EventTime: time.Now(), Log: fmt.Sprintf("[%s] error routine[%d], %v", time.Now().Format(time.RFC3339Nano), routine, err),
})
panic(err)
}
if acquired {
// 2. 成功获取锁
eventLogger.Append(common.EventLog{
EventTime: time.Now(), Log: fmt.Sprintf("[%s] routine[%d] 获取锁", time.Now().Format(time.RFC3339Nano), routine),
})
// 3. sleep 模拟业务逻辑耗时
time.Sleep(10 * time.Millisecond)
eventLogger.Append(common.EventLog{
EventTime: time.Now(), Log: fmt.Sprintf("[%s] routine[%d] 完成业务逻辑", time.Now().Format(time.RFC3339Nano), routine),
})
return
} else {
// 没有获得锁,等待后重试
time.Sleep(100 * time.Millisecond)
}
}
}
func ex02ReleaseLock(ctx context.Context, routine int, eventLogger *common.ConcurrentEventLogger) {
routineMark, _ := RedisClient.Get(ctx, resourceKey).Result()
if strconv.FormatInt(int64(routine), 10) != routineMark {
// 其它协程误删lock
panic(fmt.Sprintf("del err lock[%s] can not del by [%d]", routineMark, routine))
}
set, err := RedisClient.Del(ctx, resourceKey).Result()
if set == 1 {
eventLogger.Append(common.EventLog{
EventTime: time.Now(), Log: fmt.Sprintf("[%s] routine[%d] 释放锁", time.Now().Format(time.RFC3339Nano), routine),
})
} else {
eventLogger.Append(common.EventLog{
EventTime: time.Now(), Log: fmt.Sprintf("[%s] routine[%d] no lock to del", time.Now().Format(time.RFC3339Nano), routine),
})
}
if err != nil {
fmt.Errorf("[%s] error routine=%d, %v", time.Now().Format(time.RFC3339Nano), routine, err)
panic(err)
}
}
注意事项
大key
导致读取成本高,慢查询,主从复制异常,服务阻塞等问题
消除方法:
- 拆分:大Key拆小key
- 压缩:将value压缩后写入redis,读取时解压后再使用。压缩算法可以使用gzip、snappy等
- 使用集合类结构hash、list、set
- 区分冷热:如榜单,只缓存前10页,后续数据走db
热key
qps超过500就可以认为热key
-
设置Localcache
即在redis前再加一个本地缓存,前判断是否在本地缓存,不在再去redis中找,可以设置2s
-
拆分
-
redis代理来实现localcache的能力,本质还是结合了发现热Key和LocalCache
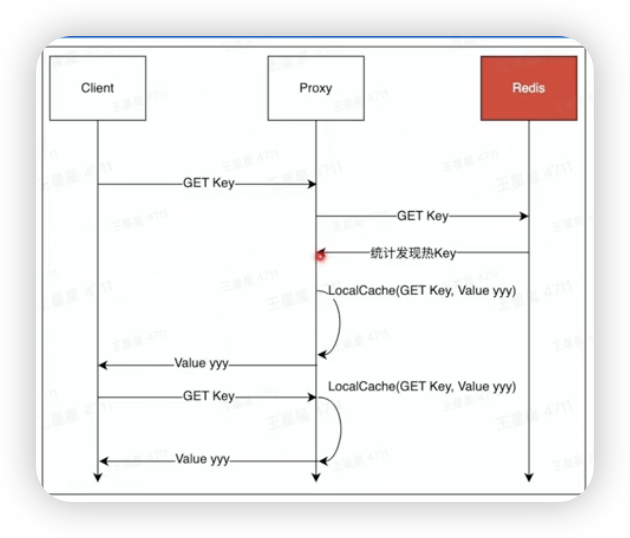
慢查询
容易造成慢查询的操作
- 批量操作一次性传入过多的key/value,如mset/hmset/sadd/zadd等O(n)操作,建议单批次不要超过100,超过100之后性能下降明显。
- zset大部分命令复杂度是O(log(n)),当大小超过5k以上时,简单的zadd/zrem也可能导致慢查询。
- 操作的单个value过大,超过10KB,也即,避免使用大Key。
- 对大key的delete/expire操作也可能导致慢查询,Redis4.0之前不支持异步unlink,大key删除会阻塞Redis。
对象存储
选择对象存储的原因
背景:面对海量数据存储的需求,急需一个方式能便宜,易用的存储海量数据
对象存储TOS:支持海量数据存储,对象数量无限制,Restful HTTP接口,云原生,使用普通X86冷热数据粉籍存储能力,成本更低
对象存储使用方式
- 申请Bucket
- 业务逻辑开发
- 视频上传
- 视频下载
- 视频删除
- 视频查看
- 上线测试
业务逻辑开发
Restful接口
例如
1
2
3
4
5
6
//./toscli表示使用 toscli 命令行工具,专门用于与对象存储服务交互
//--bucket tos-youth-train-demo指定是操作哪个Bucket
//put:执行 put 操作,将本地文件上传到指定的 Bucket 中
//-name youth_in_tos.txt:指定上传后的对象名称为 youth_in_tos.txt
//./youth.txt:要上传的源文件
./toscli --bucket tos-youth-train-demo put -name youth_in_tos.txt ./youth.txt
MultiUpload接口
用于解决大对象上传,基本思路就是将大对象进行切分,分批上传,给每个分块一个UploadId,用于识别
Listprefix接口
对于Bucket里面的对象进行分页展示
TOS实践
- 可扩展性解法之Partition
采用分而治之,不同数据映射到不同Partition分区
- 持久度解法之Replication
数据复制多份,即多个副本
- 成本解法之EC
由于Replication能解决持久化问题,但成本高,所以使用EC算法进行编码,这样冗余更低,但需要额外计算
- 成本解法之冷热转化
例如热门数据放ssd,一般数据放HHD,冷门数据放蓝光光盘
- 高可用之镜像灾备
完全镜像的主备Bucket,出现问题及时切换,两个设备同步增量
消息队列
消息队列,指保存消息的一个容器,本质是个队列,但要支持高并发、高可用
Kafka:分布式、分区、多副本的日志提交服务,在高吞吐场景下发挥较为出色
RocketMQ:低延迟、强一致、高性能、高可靠,在一些实时场景中运用较广
BMQ:存算分离
Kafka
创建集群—新增Topic—编写生产者逻辑—编写消费者逻辑
基本概念
-
Producer
-
Consumer
-
Cluster
物理集群,每个集群可以建立多个不同的Topic
-
Topic
逻辑队列,不同Topic可以建立不同的partition
-
Partition
每个Partition存储不同的消息,使用offset来保证顺序性
- 每个partition中是有多个Replica副本,消费的时候使用Replica leader,Replica follower会一直从leader拷贝数据,用于防止leader所在的broker宕机造成的数据丢失
-
-
Producer-数据压缩
通过数据压缩,减少消息的大小,接着发送给broker
Broker消息文件结构
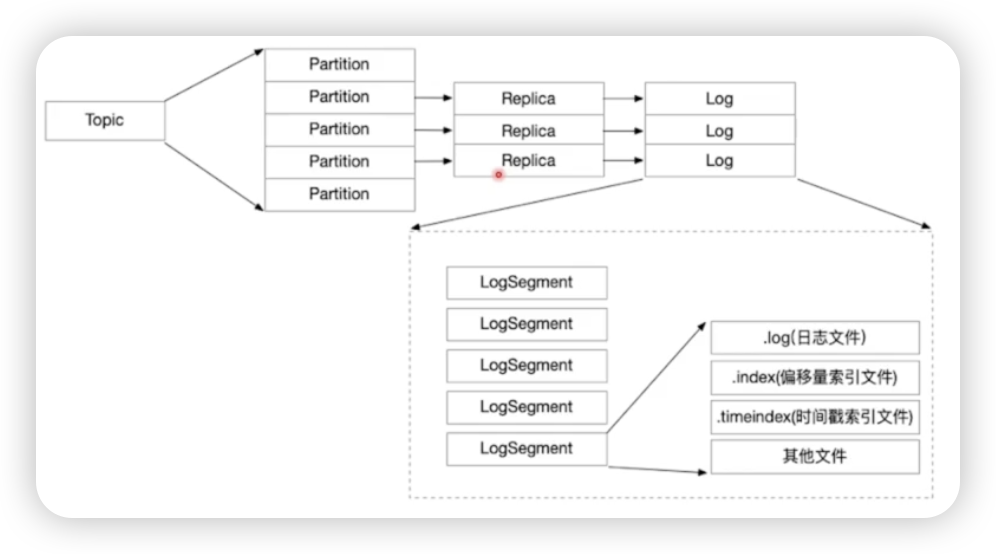
-
通过顺序写的方式进行写入,以提高写入效率
-
Broker查找消息时,首先通过二分查找找到最近的时间戳,然后再通过offset找到对应的消息
-
对于Broker发送数据给consumer的过程中,Broker是需要将数据从磁盘空间拷贝到内核空间再到应用空间的,这里就涉及到数据拷贝,使用传统的数据拷贝,消耗太大,所以使用零拷贝
Consumer-消息的接收端
Consumer消费和Partition分配方式选择是添加一个Coordinator,进行自动分配
- rebalance机制是消费者组内的消费者重新分配分区(partition)的过程。Rebalance是Kafka Consumer Group实现动态负载均衡和高可用性的重要机制
Kafka缺点:
1、重启
当进行重启broker1操作时,如果这个broker上有leader节点,那leader也会被重启,那么其他broker2上对应的follower节点就会被选为leader节点,但整个重启的过程中,数据的写入还在执行,所以broker2还在接受新的数据,所以broker1就会又疯狂追赶broker2上的新增数据,这个时候要进行leader节点的回切(如果不回切,可能随着不同的broker的重启,最后leader都堆在了一个broker上,造成负载均衡问题),随着那么多流程时间成本会很高
并且不能进行并发重启broker,因为如果某一次重启的几个broker上覆盖了同一个分片的所有副本,那么这重启的过程中这个分片就是不可用状态
2、负载不均衡
因为同一个partition数据是写到同一个broker上的,如果一个partition特别大,就会造成负载均衡问题,如果进行数据迁移,又会造成新的数据复制成本
BMQ
兼容Kafka协议,存算分离,云原生消息队列
每个partition的分片都均匀分布在不同的broker上,所以不会存在分布不均匀的情况
Partition状态机
保证对于任意分片在同一时刻只能在一个Broker上存活,防止脑裂