maskformer
分割领域有两个大框架,一方面是像素级分类(per-pixel classification)统治语义分割领域,另一方面是以Mask-FCN为首的掩膜分类(mask classification)统治实例分割、全景分割领域
像素级分类(per-pixel classification):分类损失应用于每个输出像素,将预测图像划分为不同类别的区域; 掩膜分类(mask classification):基于mask的方法不对每个像素进行分类,而是预测一组二进制掩码,每个掩预测一个单一的类别
motivation
- 自FCN提出以来,语义分割使用的方法都是对图像中的每个像素进行分类,作者提出使用mask classification来替代per-pixel分类
contribution
- 提出了一种简单的 MaskFormer 方法,可无缝转换任何现有的每像素分类模型转换为掩模分类
architecture
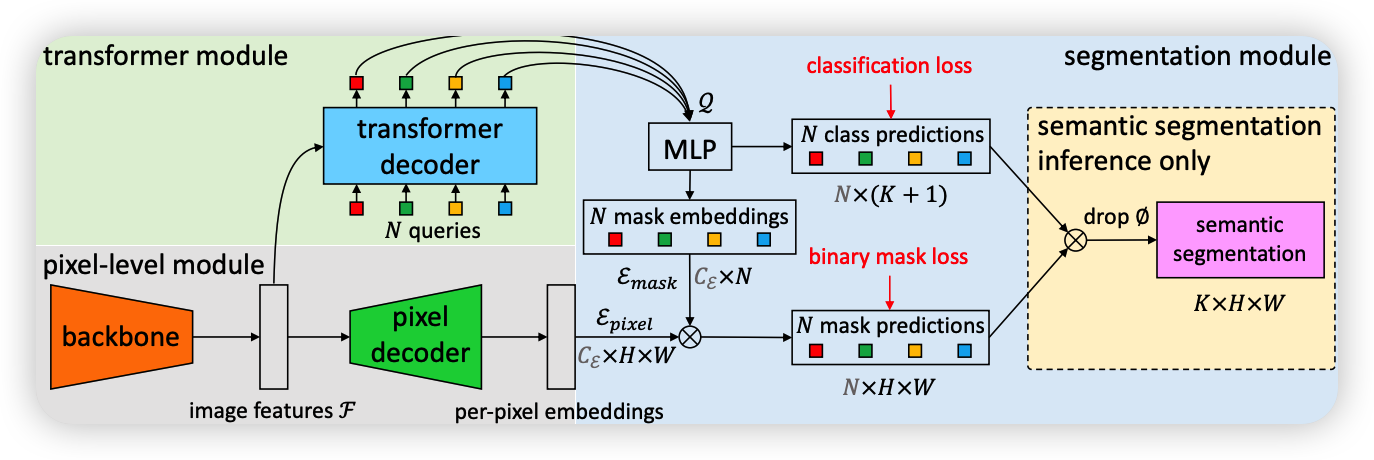
由结构图可以看出来可以分成三个部分
- Pixel-level module:用来提取每个像素embedding
- transformer module:用来计算N个segment的embedding
- segmentation module:将两个embedding进行融合得到最后的预测结果
Pixel-level module
输入H×W的图像:
- backbone生成低分辨率图像特征图F(CH/SW/S);
- pixel decoder逐步对特征进行上采样到CHW大小,以生成per-pixel embeding Epixel
transformer module
使用标准的 Transformer 解码器 来计算图像特征和 N 个可学习的位置embedding,其输出是 N 个分割embedding编码成每个分割的全局信息 MaskFormer预测。
segmentation module
将transformer decoder得到的全局信息编码经过MLP,对注意力层的输出进行进一步的非线性变换和特征表示学习,转化成Mask embeddings与pixel decoder相乘得到N个mask predictions,mask predictions中没有目标的区域是0,然后与class prediction相乘,得到最后的结果
-
Previous
Rich CNN Features for Water-Body Segmentation from VeryHigh Resolution Aerial and Satellite Imagery -
Next
mask2former